Event Streaming with Kafka
Event streaming in Kafka offers the opportunity to store all events in the broker and use the event stream as the source of truth.
Straightforward Setup
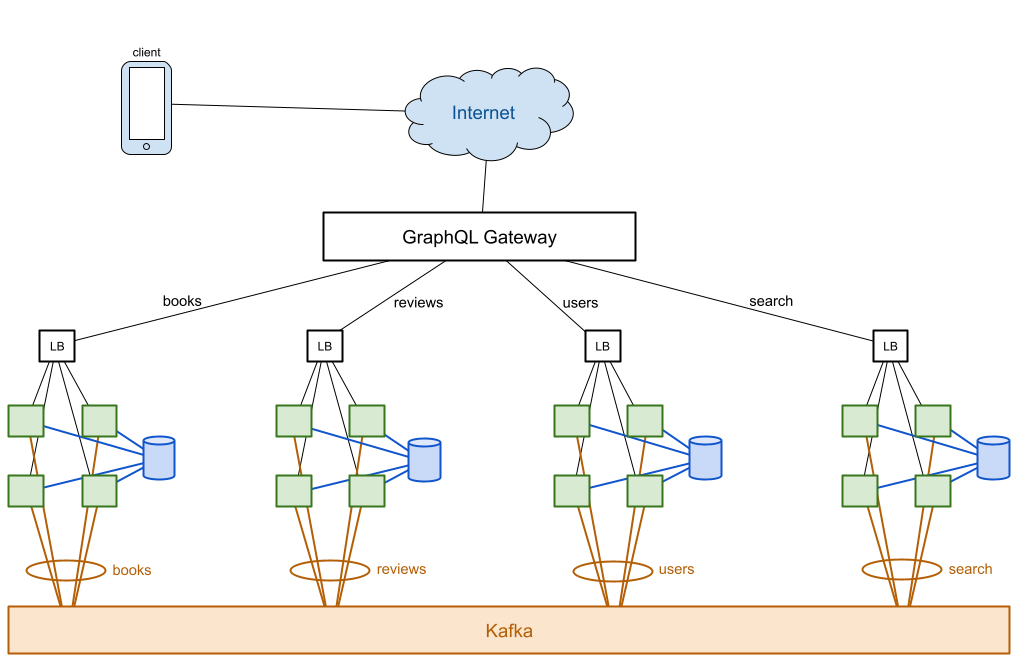
In a more straightforward setup, each microservice has its own local storage. Each microservice is a cluster with instances that share the local storage and connect to Kafka as part of a consumer group. When a mutation comes from the client, the microservice’s load balancer will send it to one instance, which will mutate the service state in the local storage. Since the storage is shared by all instances of the microservice, all instances in the cluster reflect the change instantaneously. The instance that handles the mutation also publishes an event to let other microservices know about the change.
Because each cluster uses a consumer group, a single instance will receive any given event. It then updates the local state as appropriate, and may even trigger more events.
There is an interesting variation where handling a mutation coming from the client only triggers an event without changing the local state, yet. The cluster listens for this event, and an instance will receive the event, maybe the same instance that handled the mutation or maybe a different one. The state change only occurs in response to events.
Adding an instance to the cluster is pretty quick: spin up a new instance, attach it to the shared local storage and to Kafka, and make it available to the load balancer. The gating factor is the start up time for the application.
We can optimize the number of nodes in the cluster with regard to the number of partitions in the Kafka topics. Event handling ends up being spread out across the cluster.
Event Streaming Setup
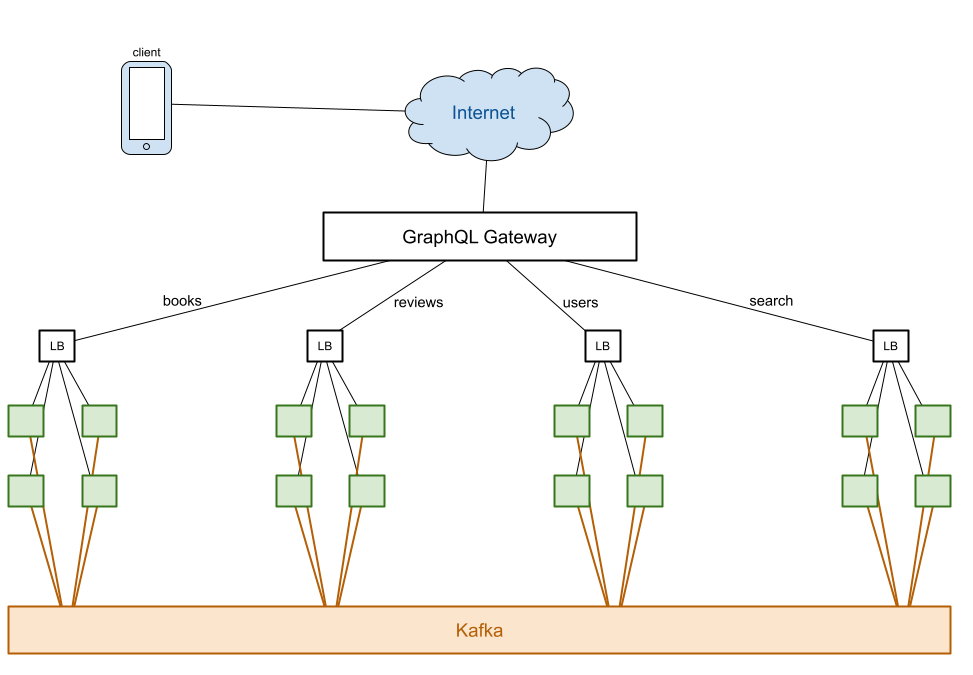
Kafka can hold on to events indefinitely and consumers can replay the event
stream from the very beginning. If all state mutations occur through events,
we can recreate the state by replaying the stream. Instead of synchronizing
the instances in a cluster through a shared local storage, we can let each one
build its own representation in memory by replaying the event stream. The
mutations that create a record are responsible for finding a unique key for that
record and include it in the creation event, so that all present and future
instances in the cluster share the same ID for the record. A UUID is an obvious
simple solution, but so are Book.name and User.email in our case, here.
Because each instance needs to receive all events, it precludes using a consumer group. This will mean more communication between Kafka and the instances.
To add a new instance to the cluster, we must spin up a new instance and connect it to Kafka, so it can replay all the events from the beginning to build its internal state. Depending on the size of the system, this may take some time. The advantage is that by keeping all the state in memory, operations are fast. The gating factor is the processing time for reading the entirety of the relevant topics.