Comparing with Vector Search
I was reading up on RAG and the article used a vector search in MongoDB to select documents to add to a GenAI prompt. I got curious if I could use a similar vector search here. My attempts at providing a search functionality so far have been underwhelming. Either they are some arbitrary SQL queries in MySQL, or a hand-crafted search service that does not tokenize properly.
Here is how I could see it working in a microservice setup. The search
service records all searches and their results on a Kafka topic. A new
vector_search service could listen to that topic and replay searches using a
vector search. It could then compare the results from the initial search with
those of the vector search.
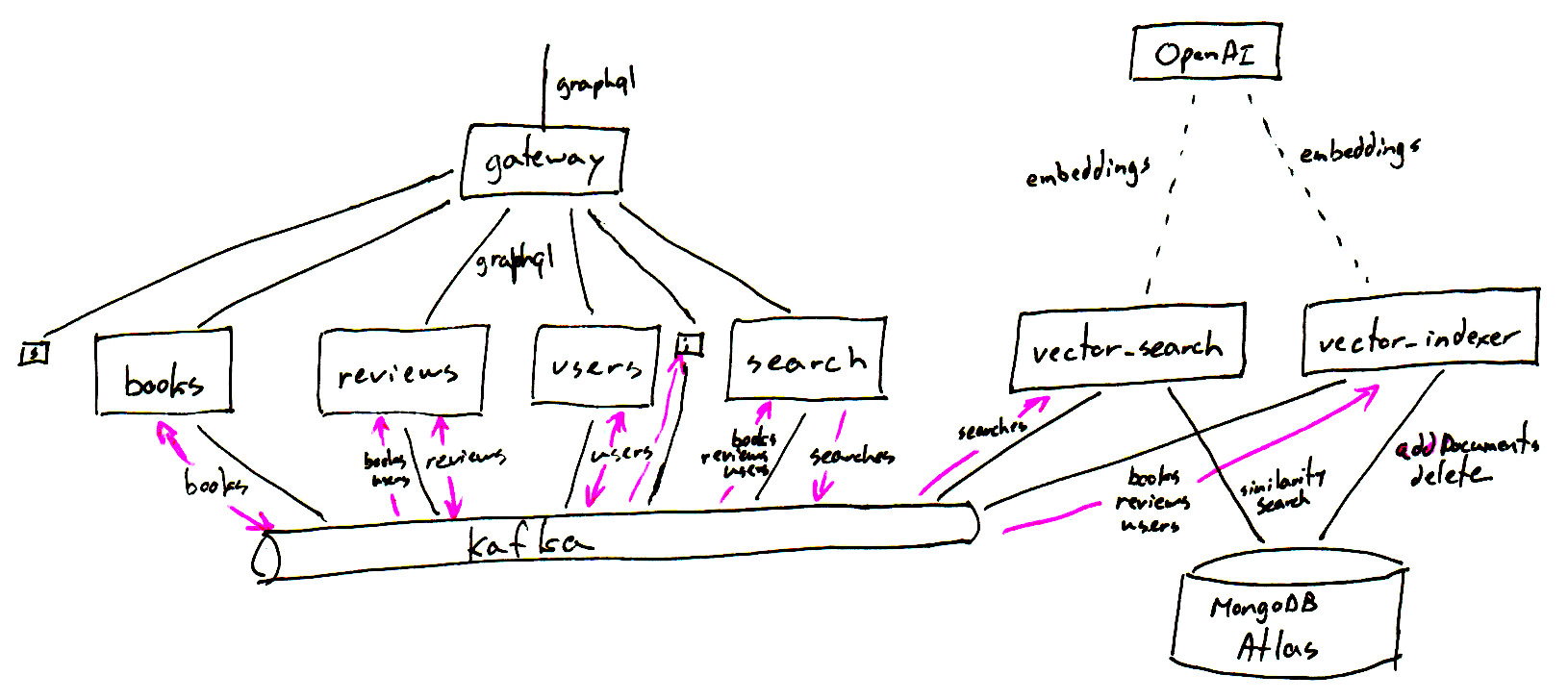
MongoDB Atlas supports vector searches, and there is a free tier for me to experiment on a zero budget.
Vector search relies on embeddings computed by GenAI models. The articles I’ve read all use OpenAI, but its doesn’t have a free tier.
I need two pieces to make it work.
Vector Indexer
The vector_indexer service syncs up the state of entities in the MongoDB
database. It listens to changes on the entity-related topics and applies them
to MongoDB.
When a Book or User or Review entity is added or updated, this service
creates a text representation and sends it to the vector store. The store will
break it down into segments and compute an embedding for each segment. It uses
a model for interpreting the text and mapping to an embedding. These get added
to the store. In the case of an update, the documentation says the store
replaces the old entries with the new ones.
When a Book or User or Review entity is removed, this service removes its
entries from the vector store.
Vector Search
The vector_search service takes a search record, gets an embedding for the
query using the same model as the vector_indexer service, and performs a
similarity search in the vector store for that embedding.
Design Choices
Shared Database
The vector_indexer and vector_search services share the MongoDB database
for their vector store. This is unfortunate coupling. I could fuse them into
a single service, but the functionalities are pretty disjoint. They share the
same model to compute embeddings, but everything else is unrelated to one
another.
One or Many Collections
In the vector store, I can either have separate collections for each type of entity, or I can stuff them all in a single collection. If I use multiple collections, I have to make multiple similarity searches and collate the results, somehow. With a single collection, I make a single search and all the results are ranked appropriately, regardless of their type.
OpenAI Versus Others
OpenAI doesn’t have a free tier. I’m able to make API calls against Google’s Gemini, either because their have a free tier or because I have an account with Google where I pay for some other services. The documentation is a little sparse on using one embeddings generator versus the other, but the vector index in MongoDB Atlas is sensitive to the shape of the embeddings. If I change models, I have to change the index in the database to reflect the new embeddings.