Jean's Journal
Jean Tessier on LinkedIn
![]()
March 17, 2026
Java 26 is out.
I looked at the
JVM specification, and I
couldn't find any changes to the .class file format. Good.
January 29, 2026
Dependency Finder is now 25 years old.
December 07, 2025
Finally figured out how to make clicking on a query result update the state of the React app. I had to consolidate the form state into a single object and move it to the parent component. I used the opportunity to clean up the React code to use more barrel files.
September 25, 2025
Java 25 has been
out for a few days. I looked at the
JVM specification, and I
couldn't find any changes to the .class file format. Good.
June 20, 2025
Updated some of the dependencies, like Ant(!) and JUnit Jupiter.
May 30, 2025
Back on 2025-05-26, the continuous build started taking much longer than usual. It usually takes about 4.5 minutes, but on that day I killed one after 15 minutes and another one after 9 minutes. I hoped it was some factor beyond my control in the GitHub cloud, or something.
Today, I upgraded Gradle to 8.14.1 and the CI stalled again while setting up
Gradle. I noticed the gradle/actions/* actions had had a major version
number update. Maybe the newer version would work better. While I was
researching this, the CI actually finished. It had taken more than 30 minutes.
With the updated action, it's back to around 4 minutes. Coincidence?!?
Some researchers in New Zealand wrote a
paper
analysing unit test coverage in Dependency Finder, one of five OSS software,
back in 2015. They compute a Centrality metric for each class that indicates
classes that are core to the library. Then, they see if high Centrality
classes have dedicated unit tests. I guess their hypothesis is that central
classes are more important and warrant dedicated unit tests. One central
class they identified in Dependency Finder is
com.jeantessier.dependency.Printer. It does not have dedicated unit tests.
It is an abstract base class, and it gets tested through the tests of its
concrete subclasses.
May 26, 2025
I refactored RatioMeasurement to reuse the "term" evaluation logic from
SumMeasurement to handle constants and named measurements. I also added
parameters to set up alternative values when the ration evaluates to NaN
or infinities. This way, I can use a RatioMeasurement to compute the
abstractness of a class as nb abstract methods / nb methods and use an
alternative 1 when it encounters marker interfaces that don't have any
methods.
I added a new configuration for OOMetrics that computes three versions of
abstractness. There is one that simply counts classes and interfaces, taken
from Robert C. Martin's work. Another just counts methods and abstract
methods. The last one computes the abstractness of a class by counting methods
and averages them at the package level. You can use
etc/AbstractnessConfig.xml to try it out on your own code.
I pushed out version 1.4.3.
May 25, 2025
I was looking at the idea of the abstractness of a package, as described by Robert C. Martin. He describes it as the number of interfaces and abstract classes in a package over the total number of classes in this package. The idea is that when developers make a change, the impact of its implementation on a given package should be inversely related to the abstractness of that package. The change is more likely to modify concrete classes, in packages with low abstractness.
To keep things simple, let's look at methods. A method either has an implementation or it doesn't (and is abstract). A software change will have an implementation, so it is more likely to impact concrete methods. It would only impact an abstract method if it were to change its signature. So, a method's abstractness is either 0% (concrete) or 100% (abstract).
Rolling this up to classes, a concrete class has only concrete methods, so its abstractedness is 0%. Prior to Java 8, interfaces could only have abstract methods, so their abstractness would be 100%, unless we count static methods . I don't remember if interfaces were prohibited from having static methods back then. Abstract classes are wildcards; all their methods might be abstract, all their methods might be concrete, or anywhere in between. In Martin's definition, he gives all interfaces and abstract classes an abstractness of 100%.
Rolling this up to packages, how do we determine the abstractness of a package?
Martin's shortcut with interfaces and abstract classes makes it easier to
calculate abstractness in the absence of tools. But with tools, maybe we can
do better. OOMetrics can use AM / M for each class. And it can sum up
AM and M across a package to figure out the package's abstractness with
better accuracy than the rough estimate of Martin's definition.
When I tried this out, the abstractness values decreased by an order of
magnitude. This is because there are many, many more methods than classes.
Some concrete classes can have a lot of methods, which skews the abstractness
of the package down. And a side effect is that marker interfaces, those with
no methods, get ignored altogether. Their AM / M is 0 / 0 = NaN.
I tried to modify RatioMeasurement to return 1 instead of 0 / 0, and I
modified the abstractness of a package to be the average of the abstractness of
its classes. This helped reduce the impact of large concrete classes. Over
large bodies of code, this new abstractness gets close to Martin's
abstractness. But on smaller bodies of code, it can vary widely. I'm going to
sleep on it.
Separately, I also fixed an overcounting bug when computing effective method length.
Depending on how the compiler generates the bytecode, the same line number can
show up multiple times in a single LineNumberTable attribute.
For example, this C.m() method:
import java.util.stream.*;
public class C {
public int m() {
return Stream.of("abc", "def", "ghi")
.mapToInt(String::length)
.sum();
}
}
Has the following LineNumberTable attribute according to javap -c -l:
LineNumberTable:
line 5: 0
line 6: 27
line 7: 32
line 5: 37
The first entry deals with the call to Stream.of(). The next entry deals
with mapToInt(), and the third one with sum(). The last instruction, at
pc: 37, is an ireturn instruction for the return keyword at the top of
the method. It shares line number 5 with the first entry.
The SLOC measurement counts the entries in the LineNumberTable attribute
and adds 1 for the method's declaration. Here, it will be 4 + 1 = 5.
The raw method length simply looks at the line numbers and returns
max - min + 1. Here, it will be 7 - 5 + 1 = 3.
The effective method length would simply count entries in the LineNumberTable
attribute. Here, it would be 4.
This is wrong.
C.m(): int
Single Lines of Code (SLOC): 5
Raw Method Length (RML): 3
Effective Method Length (EML): 4 (133%)
I changed the computation of effective method length to count the number of
distinct lines, here 5, 6, and 7. So its value should be 3.
C.m(): int
Single Lines of Code (SLOC): 5
Raw Method Length (RML): 3
Effective Method Length (EML): 3 (100%)
Suppose we add some arbitrary comments:
import java.util.stream.*;
public class C {
public int m() {
return Stream.of("abc", "def", "ghi")
// Comment 1 is rather short.
.mapToInt(String::length)
// Comment 2 is
// much,
// much
// longer.
.sum();
}
}
The LineNumberTable attribute is now:
LineNumberTable:
line 5: 0
line 7: 27
line 12: 32
line 5: 37
The raw length will increase, but the effective length will remain the same.
C.m(): int
Single Lines of Code (SLOC): 5
Raw Method Length (RML): 8
Effective Method Length (EML): 3 (38%)
May 14, 2025
Updated all the public DTDs. It appears I had forgotten to do it when I
deployed 1.4.2, or maybe even farther back than that.
Back when the website was hosted by SourceForge, I could use the webserver to
list the DTDs as part of the website. I used an .htaccess file to tell the
server to list the contents of the dtd/ directory. GitHub Pages does not
recognize the .htaccess file, so I had to add an explicit index.html to
list the DTDs and what XML they describe.
May 12, 2025
Adjusted DiffToHTML to mark synthetic features. Sometimes, the changes are
synthetic fields and methods. While still relevant, they can often be glossed
over.
I, once more, re-created the "recent" API changes for Dependency Finder using
the latest version of JarJarDiff and this new version of DiffToHTML.
By "recent", I mean versions 1.2.1-beta3 and later.
May 11, 2025
Adjusted DiffToHTML to mark inherited features instead of silently ignoring
them. The silencing logic was overly simplistic; it left behind potentially
empty "Removed Methods" sections, and putting a conditional on that heading
could leave behind empty classes. I tested it out with cases where I moved a
method up a class hierarchy. It was a better experience to show the removed
method with an indication that it was now being inherited than to leave it out
altogether.
I, again, had to re-create the "recent" API changes for Dependency Finder using
the latest version of JarJarDiff and the new version of DiffToHTML. Again,
"recent" means versions 1.2.1-beta3 and later.
May 03, 2025
Re-created the "recent" API changes for Dependency Finder using the latest
version of JarJarDiff. By "recent", I mean from version 1.2.1-beta3
forward.
May 01, 2025
There is a curious check in DifferencesFactory when dealing with removed
methods. It checks that either both oldClass and newClass are classes, or
both are interfaces, before marking a removed method as being inherited. I
found a note, dated 2001-04-05, that discusses methods that are now being
inherited. Back then, interfaces could not provide implementations, so a class
could not inherit a method implementation from an interface. I did think, at
the time, of an abstract class inheriting a method declaration only. Now,
interfaces can supply a default implementation for their methods. So, a class
can (or an interface) can inherit declarations as well as implementations from
their parents, superclasses or superinterfaces. I went ahead and removed this
extra check that is no longer relevant.
I wrote some tests first, this time.
The note from 2001 says that removed features should only be shown if they are
not inherited from a parent. The XML output from JarJarDiff will continue to
show the declaration, but mark it with inherited="yes". The HTML output
from DiffToHTML will drop it, so it does not confuse diff reports.
April 30, 2025
Found another problem with JarJarDiff and bridge methods. Earlier, I
switched to processing methods up by unique name instead of signature. I
forgot to update the part where it checks if a removed method is still
inherited from a superclass or interface. It was comparing signatures to a
wanted unique name, and not finding anything.
I need to get better at test-driving these errors. Setting up test fixtures for differences can be fairly complex, and I've become lazy.
I noticed the XSL stylesheet for DiffToHTML does not take the inherited
attribute into consideration. If a feature is no longer in a class, but gets
inherited from a parent, it shows up as a removed field or as a removed method,
with the inherited="yes" attribute. The stylesheet could drop them from
the HTML output. Or should that be a separate tool?
April 27, 2025
I think there are two underlying problems with how JarJarDiff deals with
bridge methods.
The first problem is that I use parallelStream() in many places, e.g.,
Classfile.getMethod(filter), and blindly trust the JVM to do the right thing.
In most places, I use LinkedList to store lists of things, and setting up a
parallel stream on a LinkedList somewhat defeats the purpose
See lesson 3-5 in this
course on functional programming..
When I call findAny() on a parallel steam over a LinkedList, sometimes it
finds the matching thing, and sometimes it does not. The solution, here, is
for me to use stream() only. Processing with parallel streams might be more
efficient on very long lists, but I don't know that programming elements lists
fall in that range. I could profile it to make sure, but my intuition will do
for now.
The second problem is that DifferencesFactory looks up method by their
signature. Bridge methods share the same signature as the method they are
bridging. So, sometimes Classfile.getMethod(filter) returns the actual
method, and sometimes it returns the bridge(s). The solution, here, is to look
up methods by their unique name instead. The unique name includes the return
type, so the factory will get a unique result. It also has the added benefit
that I can treat fields
A field's unique name is just its name, so going from
names to unique names changes nothing for them semantically. There is a
notion of synthetic fields, but I don't think they circumvent the
restrictions on names the way methods do with their signatures. and
methods the same: look them up by their unique name and use their full
signature.
Fixing these two problems takes care of all the fuzziness around bridge methods
I discussed on 2025-04-25. The method with the more specific return type
will either appear as having been removed or added, depending on the change.
The inherited signature and return type will appear unchanged (unless you use
-code to look at the actual instructions in the method).
One side effect, though, is that changing the return type of a method used to be considered a method modification. Now, it is treated as if the old method has been removed and the new one has been added.
With the fix in place, I pushed out version 1.4.2.
April 26, 2025
Fixed the deep links into the Tools page (and Manual and Developer too). The
previous version was very simpleminded. Each heading became a top-level
anchor; duplicates were dealt with by appending Xs to them. The new links
are hierarchical, building on higher headings and joining them using _.
The link to OOMetrics -version went from #-versionXXXXXXXXXXXXXXXX to
#ToolsinDependencyFinder_OOMetrics_Switches_-version.
One day, I would like to turn the switches in the various synopses into links to each switch's description.
April 25, 2025
Looking back at my bridge method example from 2024-09-04 and 2024-07-04
to figure out what to do in JarJarDiff. To refresh our mind, the
implementation of an interface method can either match the return type from the
declaration, or return something that is congruent with it (i.e., a subtype).
In the examples, I posited a stylistic choice on the part of the implementer.
They could conceivably go from one to the other, in either direction.
Suppose version X uses a congruent return type, the compiler will add a bridge method to "bridge" the gap.
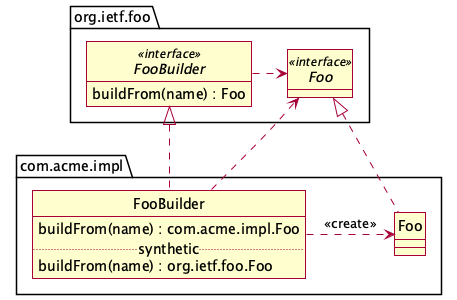
And suppose version Y uses the exact return type, and does not need a bridge method.
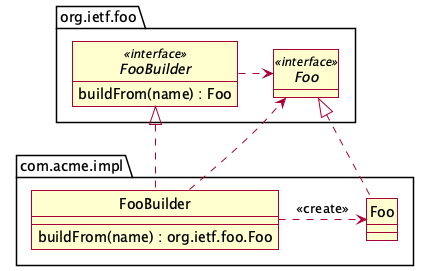
The question remains: what, if anything, should JarJarDiff report when going
from X to Y? And about the converse, where it's going from Y to X?
My first immediate concern is that when, in version X, I ask the Classfile
for the buildFrom(String) method, I randomly get the implementation or the
bridge method.
One tentative solution would be to have two Method_info structures to define
the signature: one for its declaration and one for its implementation. If
there is no bridge method, the same Method_info can serve both purposes. If
there is a bridge method, it plays the role of the declaration.
I explored a couple codebases to see some bridge methods in the wild. It turns out a method can have multiple bridge methods. Here is a "simple" example.
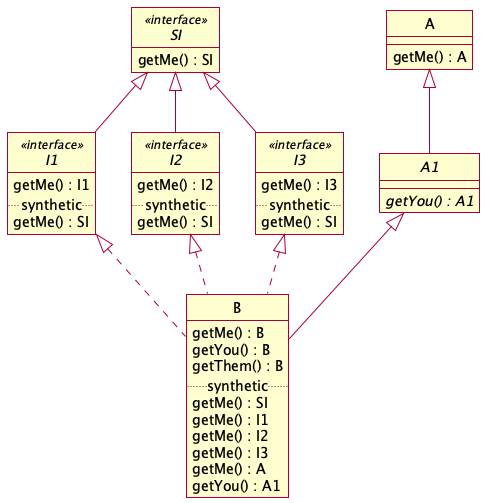
Class B inherits a getMe() method from an interface hierarchy
I found a read-life example in Saxon-HE where the
AtomicValue class inherits multiple declarations of the iterate() method
from multiple interfaces., each with a different return type. The
interfaces themselves can have their own bridge methods, according to their own
superinterfaces. Class B also inherits a getYou() method from an abstract
base class.
Perhaps JarJarDiff should spread each signature into declaration-implementation tuples, one for each bridge method.
When looking at the B class, for the getMe() method, JarJarDiff would
consider the following tuples:
B.getMe(): SI—B.getMe(): BB.getMe(): I1—B.getMe(): BB.getMe(): I2—B.getMe(): BB.getMe(): I3—B.getMe(): BB.getMe(): A—B.getMe(): BB.getMe(): B—B.getMe(): B
For the getYou() method, it would consider these tuples:
B.getYou(): A1—B.getYou(): BB.getYou(): B—B.getYou(): B
And for the getThem() method, it would consider a single tuple:
B.getThem(): B—B.getThem(): B
For each tuple, JarJarDiff would look for a matching tuple in the old and
the new codebases and use them to build a CodeDifferences. The
declaration part of the tuple would determine any changes in return type or
visibility. The implementation part of the tuple would determine if the code
itself was changed.
In the case of versions X and Y of com.acme.impl above, version X would have
the two tuples:
buildFrom(name) : org.ietf.foo.Foo—buildFrom(name) : com.acme.impl.FoobuildFrom(name) : com.acme.impl.Foo—buildFrom(name) : com.acme.impl.Foo
And version Y would have a single tuple:
buildFrom(name) : org.ietf.foo.Foo—buildFrom(name) : org.ietf.foo.Foo
JarJarDiff would match the version Y tuple with the version X tuple for the
bridge method (No. 1 in each list) and find no differences. That would leave
the second tuple in version X (No. 2 in that list) as either a removed method
if it's going from X to Y, or an added method if it's going from Y to X.
April 24, 2025
Big bug: JarJarDiff can be non-deterministic under certain conditions. I was
generating differences between version 1.4.1.1 and the latest code, and the
results kept changing from one call to the next. For example, Classfile
could have anywhere between 1 and 6 differences, even though I was analyzing
the very same files. I ran the same comparison 10 times and compared the
results. A few methods kept coming in and out of the report.
getConstantPool()getField()getInterface()getMethod()getRawClass()getRawSuperclass()
These methods have one thing in common: the latest version of Classfile has
two methods for each signature: one explicit method and one synthetic bridge
method.
In DifferencesFactory, when analyzing a class, we collect unique signatures
from the old and new versions. If a method is a synthetic variation, it gets
treated as one with the explicit method. The factory uses
Classfile.getMethod() to get the old and new Method_info that represent the
method. But getMethod() uses a stream with findAny(), whose documentation
says: "The behavior of this operation is explicitly nondeterministic."
Sometimes, it might return the explicit method, and at other times, it might
return the corresponding synthetic method.
I will need to revise how DifferencesFactory selects Method_info instances
when looking for differences between methods.
April 23, 2025
Fixed the servlet-based webapp so it properly escapes () and [] and \
and $ characters when you click on a name in a dependency graph.
I also updated the copyright notice to 2025.
I added the link to Perl regular expressions in the Manual to the React app. And I copied inputs to and from the URL's search params. I am still figuring out how to trigger a call to the backend when parameters are passed in the URL.
April 22, 2025
The servlet-based webapp lets you click on a name in a dependency graph to move
the query to that element. This is useful when navigating a graph and to
follow from one dependency to the next. My React app does not do that yet. I
added a Name component to render each name. Each has an onClick handler.
For now, the handler is in the Query component that represents the page, but
I am struggling to make it populate the right input element and trigger a query
to the backend. I did add a way to save the query parameters to the URL. Baby
steps.
I also noticed a while back that the servlet-based webapp was slightly broken.
When I click on a method name, I get a "URL contains illegal characters" error.
I believe it is reacting to () and escape \ characters in the regex. I
will need to refine how I escape names for inclusion in URLs in HTMLPrinter.
This used to work years ago. There must have been some recent development to
tighten what is considered a valid URL.
April 21, 2025
I learned that Pivotal Tracker is going away. Here is the official announcement, dated 2024-09-18. I have not maintained the project there for quite some time. I took a quick look, just to see if anything was worth salvaging. I closed one story about bridge methods.
There was another story about getting deprecation status when it is done with
the @Deprecated annotation. As I described on 2008-11-13, you can
deprecate a programming element with either a @deprecated javadoc tag or
with a @Deprecated annotation. In both cases, the compiler adds a
Deprecated attribute to the .class structure. In the case of the
annotation, there is also an entry in the RuntimeVisibleAnnotations attribute
to represent the annotation and its optional elements, if any. Therefore, the
current logic in Classfile and in Feature_info are sufficient to detect
deprecated elements, irrespective of how that deprecation is actually done.
The specification
JVMS §4.7.15 "A class, interface, method, or
field may be marked using a Deprecated attribute to indicate that the class,
interface, method, or field has been superseded." ties deprecation
semantics to the attribute and not to the annotation, so I might not need to
look explicitly for annotations in this case. I did add tests to cover both
means of deprecating programming elements.
The other stories in Pivotal Tracker were less immediately actionable. I exported the project data to a CSV file so I can dig into it later.
April 11, 2025
Loading Classfile instances from files starts with a beginSession event and
ends with an endSession event. These events are triggered in the
ClassfileLoader.load(filenames) method, which drives the loading process.
The dependency extraction process described in the DependencyListener
interface also has beginSession and endSession events, but they are never
actually fired. This process is tied to loading Classfile instances via a
LoadListenerVisitorAdapter. This adapter receives load-related events, but
only has a Visitor to interact with. It takes the Classfile instance from
the load endClassfile event and applies the visitor to it. The visitor sees
Classfile one after the other, but it has no notion of a session with a
beginning and an end.
In the sequence diagram below, I've attached a VerboseListener to both the
TransientClassfileLoader and the CodeDependencyCollector to illustrate the
events. In the diagram, load-related events are in yellow and the dependency
extraction-related events are in red. The adapter only acts on endClassfile
events and does nothing on all others.

If, instead, I removed the adapter and I made CodeDependencyCollector
implement the LoadListener interface directly, it would then know when the
session starts and ends. It would be able to map a dependency extraction
session to the Classfile loading session.
The revised sequence diagram below shows how CodeDependencyCollector acts on
beginSession, endClassfile, and endSession load-related events, and does
nothing on the other ones.

There are other tools that rely on LoadListenerVisitorAdapter, but they have
nothing to do with dependency extraction.
April 09, 2025
I have been toying with the idea of listening to dependency events using
DependencyListener and feeding the dependencies to a relational database.
The schema could separate package, class, and feature names. It could also
track the cardinality of each dependency.
For example, take the following class Test:
public class Test {{
System.out.println("abc");
System.out.println("123");
}}
When extracting dependencies, a listener receives the following dependency
events:
Test --> java.lang.Object *
Test.Test() --> java.lang.Object.Object() *
Test.Test() --> java.lang.System.out *
Test.Test() --> java.io.PrintStream *
Test.Test() --> java.io.PrintStream.println(java.lang.String): void *
Test.Test() --> java.lang.String *
Test.Test() --> java.lang.System.out *
Test.Test() --> java.io.PrintStream *
Test.Test() --> java.io.PrintStream.println(java.lang.String): void *
Test.Test() --> java.lang.String *
The Test.Test() constructor depends on class java.io.PrintStream twice. It
depends on method java.io.PrintStream.println(java.lang.String): void twice.
Currently, Dependency Finder collapses these multiples into a single edge in
the dependency graph. Is there some value to this information? I don't know.
I toyed with a schema that would split each node into its constituents. It can
use NULL in feature positions for class-related dependencies. Likewise, it
can use NULl in class and feature positions for package-related dependencies.
+--------------+------------+--------------+----------------+------------+-------------+---------------------------------+--------------+-------------+ | package_from | class_from | feature_from | confirmed_from | package_to | class_to | feature_to | confirmed_to | cardinality | +--------------+------------+--------------+----------------+------------+-------------+---------------------------------+--------------+-------------+ | | Test | NULL | true | java.lang | Object | NULL | false | 1 | | | Test | Test() | true | java.lang | Object | Object() | false | 1 | | | Test | Test() | true | java.lang | System | out | false | 2 | | | Test | Test() | true | java.io | PrintStream | NULL | false | 2 | | | Test | Test() | true | java.io | PrintStream | println(java.lang.String): void | false | 2 | | | Test | Test() | true | java.lang | String | NULL | false | 2 | +--------------+------------+--------------+----------------+------------+-------------+---------------------------------+--------------+-------------+
In SQL, we can roll up dependency counts with some GROUP BY statements.
Here is an example that sums outbound dependencies by method.
SELECT
package_from,
class_from,
feature_from,
SUM(cardinality)
FROM
dependencies
WHERE
class_from IS NOT NULL AND
feature_from IS NOT NULL
GROUP BY
package_from,
class_from,
feature_from
;
Here is another example that sums them up by package.
SELECT
package_from,
SUM(cardinality)
FROM
dependencies
GROUP BY
package_from
;
And here is an example for inbound dependencies, summed up by class:
SELECT
package_to,
class_to,
SUM(cardinality)
FROM
dependencies
WHERE
class_to IS NOT NULL
GROUP BY
package_to,
class_to
;
I struggled to use an ON DUPLICATE KEY UPDATE clause to increment the
cardinality column and update the confirmed_* in a single pass. Otherwise,
I would have to accumulate all events in memory and write the final status
after extracting dependencies. More on this later, maybe.
Another question that arose was how wide should these columns be? I don't want to use CLOB columns, so I have to give them a size large enough to contain all values. Is 1,024 too much and wasteful? Is 256 too small?
I added some measurements in OOMetrics, with a StatisticalMeasurement at
the project level to find the largest value. Is it useful enough to warrant
adding them to the codebase? I found an alternate way to get mostly the same
information with ListSymbols and some creative bash scripting.
ListSymbols lib/DependencyFinder.jar -txt -methods \
| perl -n -e 'chomp; print sprintf("%6d\t%s\n", length($_), $_)' \
| sort -n -r \
| head
OOMetrics does a better job of separating package, class and feature portions
of each fully qualified symbol. But, maybe I don't need that level of
precision. And, ListSymbols has fine controls to also look at fields and
local variables, which are outside the reach of OOMetrics.
April 02, 2025
I tried to generate some representations of Dependency Finder using ChatGPT. I asked it to do them in the style of Studio Ghibli.
Here is one for Dependency Finder:

And here is one for OOMetrics:

March 19, 2025
I removed all references to Cobertura, Clover, and EMMA, now that I use JaCoCo for code coverage.
March 18, 2025
Java 24 is out.
I looked at the
JVM specification, and I
couldn't find any changes to the .class file format. Good.
March 14, 2025
Changed the HTML metrics report to draw EML histograms using
Apache ECharts. At first, I hard-coded a
log-log plot to highlight how EML might be a power law, as suggested by
Kent Beck.
But HistogramMeasurement can be used with more than method lengths and for
measurements that might not be power laws. So, I added a parameter in its
<init> tag to specify the preferred plot for that histogram
measurement. For now, it is only applicable to the HTML report.
Here is an example of the distribution of method length in Dependency Finder.
March 13, 2025
Added HistogramMeasurement to all the OOMetrics printers. JSON, text, XML,
and YAML printers can print the actual histogram data, but the CSV printer
cannot. This is just like it cannot expand collection measurements.
March 12, 2025
Added new OOMetrics measurements for raw method length (RML) and
effective method length (EML). RML is based on
maxline numbers - minline numbers + 1, and EML is
based on |line numbers| (the cardinality of line number entries).
I also fixed SLOC for methods so it includes the method's definition. For
most methods, it works just fine. But it also adds 1 "line" to static
initializers. SLOC remains an approximation that is close enough.
I made a change to StatisticalMeasurement. When it is empty, it used to
return NaN for its sum. This caused problems when I tried to aggregate
methods lengths at the class, group, or project levels. I think it is
reasonable to have sum return 0 when the measurement is empty. I am
beginning to think it wouldn't be a bad thing to have some kind of
indeterminate state for measurements that don't have a definitive value, like
empty stats or some counters that have not been added to.
I started working on a HistogramMeasurement. It aggregates values from
submetrics. One challenge is figuring out what its getValue() should return.
For now, I'm having it return the value of the largest bucket in the histogram.
I am also having it use integer buckets. It rounds up values to the nearest
integer. I will need to modify all the measurement printers so they handle
histograms properly.
March 11, 2025
Kent Beck was discussing
how long should functions be
and I started thinking that I could use OOMetrics to find that out. The
default configuration includes SLOC measurements, but they include a value of
1 for abstract methods. Synthetic methods and methods that do not have a
Code_attribute get a value of 0, although "not definitive" would be more
accurate. The CounterMeasurement type of measurements does not have an
indeterminate state, so 0 will have to do.
I could create a new measurement for function length and populate it based on
LineNumberTable_attribute. I could either count the entries in the
attribute, or do arithmetic with the line numbers it contains. I could even
possibly refactor the existing SLOC measurement calculation to make use of
it.
For example, take the load(DataInput) method of ClassfileLoader. It is an
abstract method in an abstract base class.
line 62 protected Classfile load(DataInput in) throws IOException;
It is a line of code, so it should be included in the SLOC measurement.
And, its length is clearly zero.
Now, consider its implementation in AggregatingClassfileLoader.
line 75 protected Classfile load(DataInput in) throws IOException {
line 76 var result = getFactory().create(this, in);
line 77
line 78 classfiles.put(result.getClassName(), result);
line 79
line 80 return result;
line 81 }
Its LineNumberTable_attribute only includes lines 76, 78, and 80.
Its SLOC measurement is 3. Looks like a bug is causing it to ignore the
method declaration on line 75.
The function length is more ambiguous. Do we count the declaration (line 75)? Do we count the closing brace on line 81? There are 3 active lines in the body, but 5 lines in total. Should the length be 3? 4? 5? 7?
Kent Beck's article shows many 1-line and 2-line functions. So I feel he is not including the method declaration and closing brace in his definition. He's only looking at the body of the method. Most people don't include empty lines and comments either, but the article does not say.
I am tempted to add two new measurements: a raw count that is simply
maxline numbers - minline numbers + 1 and an actual
count that is the count of line numbers. For the load(DataInput) method
implementation, the raw count would be 80 - 76 + 1, so 5. The actual
count would be 3. Its SLOC measurement should be 4.
February 02, 2025
Renamed the Micronaut and React projects to more official Dependency Finder names.
micronaut-depfind-test⇒dependency-finder-micronautdependencyfinder-react-app⇒dependency-finder-react
January 31, 2025
Figured out how to use environment variables and Docker settings to point the Micronaut service to custom code and dependency graph locations. The defaults in `application.properties` are for running the service locally, outside of Docker. When running it in a container, I can use environment variables to point the service to `/code`, like the Dependency Finder webapp, and then mount volumes at these locations.
I wrote some integration
tests for Micronaut.
I started with LoadController and ExtractController. I was able to do
simple GET requests and verify the load and extract metadata. I could put
test-specific properties using special .properties files, but I was not
successful is making POST requests to trigger loading or extracting.
I broke up the single micronaut.depfind.test package into:
com.jeantessier.dependencyfinder.micronautcom.jeantessier.dependencyfinder.micronaut.controllerscom.jeantessier.dependencyfinder.micronaut.services
The whole Micronaut service is still called micronaut-depfind-test, but it's
a start.
January 29, 2025
Dependency Finder is now 24 years old.
Looking at code coverage data, I realized there was a missing Fit test for
ListDynamicInstructions.
There are no Fit tests for ClassDump either. But that is because it is not
even a proper Command-based CLI tool. It was always meant to stand on its
own, with no dependencies outside the JDK. When ClassDump encounters a
.class file, it reads it one byte at a time, in a while (true) {} loop.
The EOFException when it reads past the end of the file will kill it out of
the infinite loop. This is not very clean, but the I/O interfaces are not very
good at letting me detect the end of the file.
I was curious how big my .class files got to be. The largest one I could
find in the Dependency Finder codebase was TestXMLPrinter, in the
:integration-tests subproject, at 115KB. It has a lot of tests and most
of them use jMock to re-create specific situations. Since most tests didn't
interact with the file system, I broke it down between unit tests and the few
legitimate integration tests. 196 tests ended up moving to the :lib
subproject.
I added a navigation bar to the React app. I couldn't find a standard way of doing this in React or Vite, so I went with a custom component for now.
I pushed out version 1.4.1. While I was following instructions to generate
the sample data for the new release, I realized the Linux scripts were not
escaping spaces correctly. For example, when I called:
JarJarDiff -name "Dependency Finder" ...
The differences report had a name of "Dependency" only. I had to fix the launching scripts to handle escaped spaces correctly.
I pushed out version 1.4.1.1 with the fixed scripts. The launching scripts
are the only thing that's changed, so I will not update the documentation and
everything at this time.
January 25, 2025
I managed to fix the connection between the Micronaut microservice and the
React frontend, even through an ngrok tunnel. After digging through the
Vite documentation, I moved the
.env.local file that was setting the service URL to http://localhost:8080.
By renaming it to .env.development, it now only applies in development mode,
and it is no longer part of the final build. There, it uses
document.location.origin
instead. So, whatever URL gets you to the app also gets it to the service.
I used the same URL for actions in the service and pages on the frontend, which
can lead to confusion. If you go to / and then navigate to /extract, you
get the Extract UI. If you go directly to /extract, you get a JSON with
Extract metadata. So, I moved the actions in the service to /api URLs. Now,
you can no longer go directly to /extract, it only works when navigating from
the home page. You can reach the Extract action by going to /api/extract.
There are a few things I still need to work on:
- The Micronaut app needs a better name than
micronaut-depfind-test. - I don't like the package name for the Groovy code,
micronaut.depfind.test. - The names of code and dependency graph files need to be more user-friendly, given that it is hard to change them in a running container.
- The Home page for the React app is still the default Vite demo page.
- I need to make the navigation accessible on all pages in a way congruent with Vite.
But, all the major functionality is there.
January 24, 2025
Created a Docker image to run Dependency Finder Micronaut app and React frontend in a Docker container.
I built the
React app and
dropped it in the
Micronaut app's
src/main/resources/static/frontend/ folder. This way, it is included when
the Micronaut app gets deployed. If I run it in a Docker container and export
port 8080, my browser can download the React app from http://localhost:8080
and it can contact the microservice back at http://localhost:8080.
I created a tunnel to my app running locally using
ngrok. I could download the React app from another
computer, through the ngrok tunnel, but it still believed it was being hosted
at localhost, so it couldn't connect back to the microservice to load any
data.
I also tried to deploy the Micronaut Docker image using GitHub actions, but I couldn't get the workflow quite right. In Micronaut, interactions with Docker are mediated through Gradle. I will need to explore how to make it work with the GitHub actions for Docker. Or, maybe I just use a bunch of shell commands instead of a third-party GitHub action.
January 23, 2025
Found a problem with JSON and YAML printers and irregular values. An empty
StatisticalMeasurement has all sub-values as NaN. It is possible for a
RatioMeasurement to have a value of NaN, infinity, or negative infinity,
which Java renders as "NaN", "Infinity", and -"Infinity" respectively.
JSON does not have a representation for
these values. I changed the printers to put null instead.
YAML does have representations for these
values. I changed the printers to put .NaN, .Inf, and -.Inf as
appropriate. YAML is not case-sensitive, but I liked these capitalized
versions.
And it was not just the printers, but the MetricsToJSON and MetricsToYAML
XSL stylesheets too.
With these fixes in place, I was able to add the /metrics page to my React
app and complete it. I also used
Apache ECharts to render the dependency
metrics chart and all the histograms.
January 22, 2025
I needed to add a JSON output to dependency metrics from DependencyMetrics so
they can be fed from the Micronaut service to the React frontend.
I was looking at MetricsReport. It exposes charts, but each of the eight
charts are the same lengths, padded with zeroes as needed. This seems wasteful
to me. I added a histogram version of each chart that only includes parts
where there is actual data.
I also split the old MetricsReport into an abstract base class
MetricsReport that has all the flags, and a specific TextMetricsReport for
the details of writing textual metrics reports. With this split in place, it
was easier to introduce a class that renders the report as a JSON object.
January 21, 2025
Wrote a JSON printer for dependency cycles.
These cycles:
a
--> b
--> a
a
--> b
--> c
--> a
Become the following JSON document:
[
[
{"type": "package", "name": "a"},
{"type": "package", "name": "b"}
],
[
{"type": "package", "name": "a"},
{"type": "package", "name": "b"},
{"type": "package", "name": "c"}
]
]
January 13, 2025
Finished converting all tests to JUnit Jupiter.
I used Perl to do some of the heavy lifting, then reviewed each file manually.
These regex would move the assertion message to the last parameter. They would get confused when expressions were too complex or had method calls with extra commas in them.
s/assert(Equals|Same|NotSame)\((.*), +(.*), +(.*)\);/assert\1(\3, \4, \2);/;
s/assert(True|False|Null|NotNull)\((.*), +(.*)\);/assert\1(\3, \2);/;
These regex would change test method signatures and add annotations.
if (/^(\s*)protected void setUp\(\)/) {
print($1 . "\@BeforeEach\n");
s/protected void/void/;
}
if (/^(\s*)public void test\w+\(\)/) {
print($1 . "\@Test\n");
s/public void/void/;
}
if (/super.setUp\(\)/) {
$_ = "";
}
January 12, 2025
I think I found a workaround for my problems with DOT files. I added a switch
to DependencyReporter to force it to output nodes that match the filter
criteria, along with nodes that match the scope criteria. The new switch is
called -include-filter-nodes. With it, the XML output will have everything
needed by DependencyGraphToDOT to render the graphs I want.
I also changed the URL prefix for DTDs from https://depfind.sourceforge.io/
to https://jeantessier.github.io/dependency-finder/. This way, these
resources will come from the official site on GitHub instead of the old site
back on SourceForge.
January 11, 2025
There are some issues with the way I generate the DOT files. I currently do it in two passes:
- Generate nodes based on packages, classes, and features in the source XML.
- Generate dependency edges based on
<outbound>elements.
The initial samples I was working from when I handcrafted the XSL stylesheet
was essentially the raw output of DependencyExtractor. It included all the
relevant nodes and all edges were represented by both <outbound> and
<inbound> elements. It made sense, under these circumstances, to only
look at <outbound> elements to prevent duplication. And every
dependency was between nodes present as either <package>,
<class>, or <feature> elements.
But most graphs come from DependencyReporter instead, so we can focus on
specific dependencies. These graphs may include only <inbound>
elements, for example. The source parameters will result in <package>,
<class>, or <feature> elements, but filter parameters will not.
For example, if I want to find out which com.jeantessier.dependencyfinder.*
classes are using GraphCopier or GraphSummarizer, I can do the following:
DependencyExtractor -xml lib/DependencyFinder.jar |
c2c -xml
-scope-includes '/Graph(Copier|Summarizer)/'
-filter-includes /com.jeantessier.dependencyfinder/
The XML output is as follows. There is one <package> element and two
<class> elements. The references to
com.jeantessier.dependencyfinder.* classes are only in <inbound>
elements.
<dependencies>
<package confirmed="yes">
<name simple-name="com.jeantessier.dependency">com.jeantessier.dependency</name>
<class confirmed="yes">
<name simple-name="GraphCopier">com.jeantessier.dependency.GraphCopier</name>
<inbound type="class" confirmed="yes">com.jeantessier.dependencyfinder.ant.DependencyReporter</inbound>
<inbound type="class" confirmed="yes">com.jeantessier.dependencyfinder.cli.DependencyReporter</inbound>
<inbound type="class" confirmed="yes">com.jeantessier.dependencyfinder.gui.DependencyFinder</inbound>
</class>
<class confirmed="yes">
<name simple-name="GraphSummarizer">com.jeantessier.dependency.GraphSummarizer</name>
<inbound type="class" confirmed="yes">com.jeantessier.dependencyfinder.ant.DependencyReporter</inbound>
<inbound type="class" confirmed="yes">com.jeantessier.dependencyfinder.cli.DependencyReporter</inbound>
<inbound type="class" confirmed="yes">com.jeantessier.dependencyfinder.gui.DependencyFinder</inbound>
</class>
</package>
</dependencies>
And here is the graph that I generate from this XML output.

The first thing I can do is look at both <outbound> and
<inbound> elements. There might be some duplicate edges as a result,
but since I use a strict digraph in the DOT file, Graphviz should de-dupe
them for me.
There will still be a problem that the nodes from filter parameters are not expressed correctly, though.

Where what I really want is closer to:

January 10, 2025
I saw someone's Advent of Code solution where they were generating a DOT file for a graph and rendering it using Graphviz. I thought I should be able to render a dependency graph the same way. I wrote an XSL transform to convert the XML graph file to the DOT language. I had to add each node's simple name to the XML output.
January 09, 2025
Converting more unit tests to JUnit Jupiter. I migrated all tests to jMock
with JUnit Jupiter. I migrated all JUnit 4 parameterized tests to JUnit
Jupiter parameterized tests. I migrated all JUnit 4 tests to JUnit Jupiter.
I used a Perl script to do some of the more tedious conversions, but I still
had to manually inspect hundreds of files. All I have left are a bunch of
JUnit 3 tests in com.jeantessier.dependency, and then I'll be all on the most
up-to-date JUnit.
January 08, 2025
Converting more unit tests to JUnit Jupiter.
January 07, 2025
Started converting some of the unit tests to JUnit Jupiter.
I really like assertLinesMatch() for comparing text that spans multiple
lines. I got creative with Stream.of() and flatMap() to build the expected
output for some printers.
January 06, 2025
Finished converting all the integration tests to JUnit Jupiter.
I started converting some unit tests, too. I created the class
com.jeantessier.MockObjectTestCase as an almost drop-in replacement for the
one from jMock for Junit 3. It saves me from having to edit all the calls
to mock() and checking(), but the name is ugly. I still have to edit all
the assertions, mostly to put the error message as the last parameter. It's
tedious work.
January 05, 2025
Started converting some JUnit 3 tests to JUnit Jupiter. I started with integration tests, since there are not as many of those. I'm hoping I can eventually remove dependencies on JUnit 3 and 4 completely, but that might take a while.
I'm still using jMock, but I don't have access to MockObjectTestCase anymore.
I managed to add mock() and checking() methods to one base class so I
wouldn't have to edit too many tests. I guess I could write my own
MockObjectTestCase class, maybe as a temporary stopgap.
I am keeping setUp() methods as setUp(), but with the @BeforeEach
annotation from JUnit Jupiter. I need to be careful when a test class
hierarchy needs setup at multiple levels. I got burned because the subclasses
were overriding their superclass's setUp() and it wasn't being called by
JUnit as a result. I will be using more descriptive names in superclasses
going forward.
November 21, 2024
Ran this journal through a spellchecker.
November 19, 2024
Finished reformating the /query page of my React app using
Grid Layout.
I was able to get rid of <blockquote> tags and replace them by
<div> tags with CSS classes. I used the ch unit to re-create the
indentation from <blockquote>.
November 18, 2024
I'm reformating the /query page of my React app using
Grid Layout.
November 11, 2024
Dependency Finder received PR #13 from GenZmeY that fixes the Windows scripts. I haven't had access to a Windows machine for years, so I didn't have a way to test them. Thank you, GenZmeY!
October 20, 2024
Added a fully functional /query page to my React app. You can specify scope
and filter criteria, run the query, and view the results. It doesn't do graph
surfing or set query string search parameters, yet. And, I don't know if I
will get to the Advanced Query page. I might do closures and metrics first.
I found a "bug" in com.jeantessier.dependency.JSONPrinter. It rendered
boolean values for confirmed nodes as the strings "true" and "false",
instead of the raw boolean values true and false that are allowed in JSON.
I had to fix quite a few test data templates. The templates didn't end with a
newline character because I compared them to the printer's output, which
doesn't have one either. But IntelliJ IDEA decided to add a newline on each
file that I touched, out of the goodness of its heart. I would have been
tedious to open each file in another editor, just to remove a newline. So, I
adjusted the test to add a newline to the printer's output instead.
October 19, 2024
Copied the compiled React app to a static assets folder
There is an example in the
Micronaut guides.
It sets up a rather convoluted sample app with a messaging service, but you can
tease out the crux of how to do static assets if you squint. under
Micronaut. With a single server running the Micronaut app, I can get to the
React app's home page and its extract and load pages to trigger the
matching extract and load endpoints in the Micronaut app.
October 18, 2024
Fixed the update checkbox on the /extract page. Also, added title and logo
in the browser tabs.
And now, when I build the React app to static assets, it all works just fine. I don't know what I did that made it work, but it is nice.
October 17, 2024
More tinkering with my React-based experiment. I added the /load page to
load a pre-extracted dependency graph instead of creating one from compiled
Java code. This got me to create a shared <Stats> component for both
pages.
I wired the forms to actually trigger the corresponding actions on the
Micronaut service. It even forces a refresh of the <Stats> component
with updated data from the service.
I tried adding dotenv so I could put the service URL in a .env file. After
getting it all setup, I found out Vite already includes dotenv, complete with
a .env.local file that is already being ignored by Git. So, I reverted my
dotenv work in favor of the "standard" one.
October 16, 2024
More tinkering with my React-based experiment. I fleshed out the /extract
page and created sub-components for parts of the page. I found
react-hook-form to try to handle the form to launch the extraction, but I am
struggling to make it work properly.
October 11, 2024
Figured out how to log requests in Micronaut for my React-based experiment.
October 03, 2024
I tried to do static exports of my Next.js project, but it seems to be losing the CSS styling.
I looked for more alternatives to
create-react-app in 2024. One Reddit user
recommended using Vite instead. The Vite documentation
describes how to add
React Router, which is what I
have been using on other React projects. It also described using
SWR for fetching data. I managed to
create a /extract route that fetches source and filter information from the
/extract endpoint on the Dependency Finder service. But when I build the
project to generate static assets, the page does not render for some reason.
October 02, 2024
My experimentation with Next.js is not going well. It
looks like Next.js wants both a server-side component and a client-side
component. It requires something like a Node server running to serve the app.
I'm already toying with a Micronaut app to interact with the graph, I don't
need yet another one just to mediate with the frontend. I have built
I used create-react-app,
which is no longer the popular, hip way to setup a React project. It is while
searching for a replacement that I found Next.js. React apps that deploy
as static assets and call to a backend to get their data. I was hoping Next.js
could give me something just like that. There is a way to compile the app to a
static version, but routing gets very limited. I couldn't do what they call
dynamic routing in a static version, but I might be able to make it work with
extract and query pages, and the like.
September 30, 2024
More experimenting with Micronaut and Next.js.
I also read an
article
on the new
Class-File API
that started previewing in Java 22. It includes features to read .class
files, similar to my com.jeantessier.classreader package. The Class-File API
also includes features to generate .class files and manipulate code, which I
don't do.
September 28, 2024
More experimenting with Micronaut. I managed to extract and load graphs, and issue simple queries.
I google'd how to do React in 2024, and Next.js came on top. So, I'm making my way through the tutorial.
September 27, 2024
Finished work on printers in com.jeantessier.dependency. I can now generate
HTML (partial), JSON, text, XML, and YAML directly from inside the application.
For JSON and YAML, I tried to make the direct output match the output from the
corresponding XSLT stylesheets as best I could.
September 26, 2024
Refactored tests for printers in com.jeantessier.dependency. Instead of
using complicated line-matching logic in ad hoc tests, I switched to external
files that contain the expected outputs. The files have proper extensions so
tools can help with the editing. And, I can use parameterized tests to match
test setups to expected output files. I got through text and XML outputs,
and did JSON output, too. I also want to do YAML and HTML, for to have the
coverage.
September 25, 2024
Experimented with Micronaut to see how I could add
the JAR files for Dependency Finder to a Micronaut app and call its classes
from the application. I managed to wire together a simple /version endpoint
that returns data from the Version bean inside Dependency Finder. I could
create controllers that rough match the JSP pages in :webapp. I'll have to
figure out how to move a Micronaut app from a top-level Gradle project to a
subproject in Dependency Finder.
I have an XSLT stylesheet to convert dependency graphs from XML to JSON. But, I don't have a way to generate JSON directly from within the application.
September 21, 2024
I was reading up on Declarative Gradle, and I found a deprecation warning in build scans. So, I converted all the build configurations to the new Test Suite plugin.
September 20, 2024
Crazy thought: could I replace :webapp with a microservice with a React
frontend? Should I? I could write the microservice with Micronaut. I would
need a JSONPrinter for dependency graphs.
September 19, 2024
I want to rename getSignatureDeclaration() to locateMethodDeclaration().
This will draw a parallel with the existing locateMethod(). It also links
the caveats that applies to both methods: they can only locate methods and
declarations in classes that were loaded by a Dependency Finder
ClassfileLoader.
Actually, by the same loader as the one that loaded the current classfile.
Actually, only if it is an AggregatingClassfileLoader.
The following example shows a bridge method when implementing
Enumeration<E>.
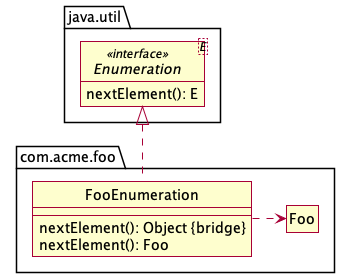
The declaration for the bridge method would be
java.util.Enumeration.nextElement(): Object. The declaration for the
method with the actual implementation would be the method itself.
We could try to match the signature of the bridge
method to that of the implementation method, but such a match would only work
when the methods differ only in their return type.
September 18, 2024
Finished getSignatureDeclaration() by adding a method on Classfile to walk
the class hierarchy.
One issue that comes up is what to do when the same method is declared in multiple interfaces.
In the following example, the method m() is declared in both SuperInterface
and OtherInterface.
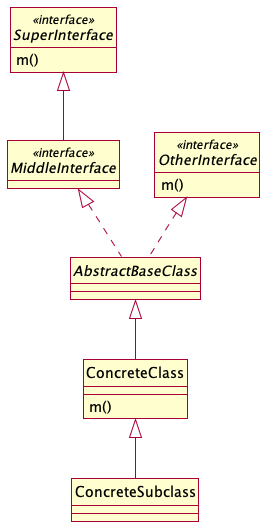
Which one should I pick when trying to locate the declaration of
ConcreteClass.m()? Should I always return a list of all candidates? Even if
most of the time, it will have only one element?
A second issue comes up when a method comes from an ancestor that Dependency
Finder has not parsed. Take the following example that extends java.io
classes.
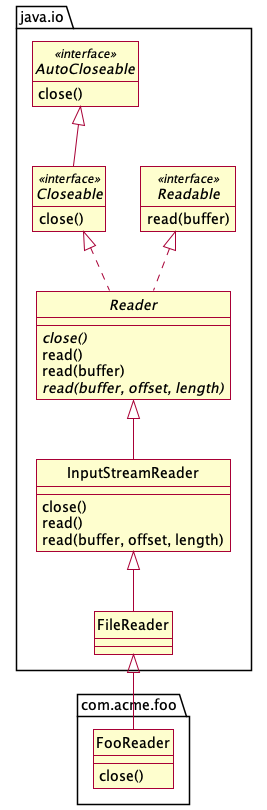
If Dependency Finder only sees the com.acme.foo package and not the java.io
package, then it will think the close() method was declared in FooReader,
and it won't even see the read() methods.
Maybe as unconfirmed nodes in a dependency
graph.
September 17, 2024
Java 23 is out.
I looked at the
JVM specification, and I
couldn't find any changes to the .class file format. Good.
I tried to add a getSignatureDeclaration() method to Method_info. The goal
is to walk up the class hierarchy to locate the declaration of a given method.
I don't really like the name, but I can't think of a better one for now.
September 16, 2024
Following up on the Mastodon
question about identically named methods,
but with different return types. The original poster gave an example that
implemented Enumeration<E>, and its nextElement() that should return
an E.
I updated my illustrative example.
public interface Factory<T> {
T create();
}
public class Circle {}
public class CircleFactory implements Factory<Circle> {
public Circle create() {
return new Circle();
}
}
CircleFactory still has two create() methods: one is a bridge method that
returns an Object from the definition of Factory with type erasure, and the
other remains the method from the source that returns a Circle.
During the discussion, I had to double-check my definitions for descriptors and signatures. A method's signature JLS §8.4.2 is its name + parameter types. A method's descriptor JVMS §4.3.3 is its parameter types + return type. It's interesting to note that strictly speaking, a method's name is not part of its descriptor.
From this, we can state that the compiler will reject source code for a class with duplicate signatures JLS §8.4.2 "It is a compile-time error to declare two methods with override-equivalent signatures in a class.". But, the JVM will accept the bytecode of a class that has methods with matching signatures, as long as their descriptors are different JVMS §4.6 "No two methods in one class file may have the same name and descriptor (§4.3.3).".
September 14, 2024
Someone on Mastodon asked a question about identically named methods, but with different return types. This is a good example of bridge methods. It is very timely that I recently learned about these.
I came up with a nice little example to illustrate.
public interface Shape {}
public interface Factory {
Shape create();
}
public class Circle implements Shape {}
public class CircleFactory implements Factory {
public Circle create() {
return new Circle();
}
}
Now, CircleFactory has two create() methods: one is a bridge method that
returns a Shape, and the other is the method from the source that returns a
Circle.
September 05, 2024
Released version 1.4.0, with:
- better handling of bridge methods
- unique name of method includes its return type
ListSymbolscan output CSV, YAML, JSON, and XML
September 04, 2024
Looping back on the discussion on bridge methods and code differences I brought up on 2024-07-04, imagine the following interfaces:
package org.ietf.foo;
public interface Foo {}
public interface FooBuilder {
Foo buildFrom(String name);
}
And the initial implementation below. They chose to name their classes exactly
like the interface they implement, because reasons
Maybe they like to keep names simple, like Foo. The
alternative is to distinguish them artificially, either as FooInterface and
Foo, or else as Foo and FooImpl. Nobody in their right mind would use
something as silly as IFoo and FooImpl, though. Right?!? Regardless of
the names, the compiler will create a bridge method..
package com.acme.impl;
public class Foo implements org.ietf.foo.Foo {}
public class FooBuilder implements org.ietf.foo.FooBuilder {
public Foo buildFrom(String name) {
return new Foo();
}
}
The Foo in the method's return type is really a com.acme.impl.Foo.
The type is congruent with the interface definition, so there is no problem.
The compiler creates a bridge method to "bridge" the difference, and everyone
is happy.
Let's say the developers decide to remove the ambiguity and write a new version.
package com.acme.impl;
public class Foo implements org.ietf.foo.Foo {}
public class FooBuilder implements org.ietf.foo.FooBuilder {
public org.ietf.foo.Foo buildFrom(String name) {
return new Foo();
}
}
It is a little bit more verbose, but removes the need for the bridge method.
What should JarJarDiff say in its reports about the changes from the initial
version to the new version, if anything?
The initial version has three method symbols.
com.acme.impl.FooBuilder.FooBuilder()com.acme.impl.FooBuilder.buildFrom(java.lang.String): org.ietf.foo.Foo(the bridge method, calls the other symbol)com.acme.impl.FooBuilder.buildFrom(java.lang.String): com.acme.impl.Foo(the implementation from source code)
The call graph for some hypothetical client code that calls buildFrom() looks
like this.
Client.main(java.lang.String[]): void
--> com.acme.impl.FooBuilder.buildFrom(java.lang.String): org.ietf.foo.Foo
--> com.acme.impl.FooBuilder.buildFrom(java.lang.String): com.acme.impl.Foo
The new version has only two method symbols.
com.acme.impl.FooBuilder.FooBuilder()com.acme.impl.FooBuilder.buildFrom(java.lang.String): org.ietf.foo.Foo(the implementation from source code)
And a more compact call graph.
Client.main(java.lang.String[]): void
--> com.acme.impl.FooBuilder.buildFrom(java.lang.String): org.ietf.foo.Foo
From the client's perspective, nothing has changed. It calls an interface
method, and what happens after that is not the client's concern. Whether it is
a bridge method that then calls an implementation, or that implementation
itself, is completely hidden from the client. Therefore, maybe JarJarDiff
should not report any changes?
But there is a public method that has disappeared. Does it not matter?
I tried to modify DifferencesFactory to compare methods by their
unique name instead of their signature. It would report the mismatched
signature as having been removed, and the matching signature as having a code
change. But distinguishing methods based on their unique name makes it
impossible to track changes to a method's return type. Instead, it looks like
one method was removed and another method was added.
So, I will keep distinguishing methods based on their signature. In our
example, the default report will show no changes, just like the client code
perceives. If JarJarDiff has the -code switch, it will report a change of
the return type, which is not untrue.
Method Changes:
old:public com.acme.impl.Foo buildFrom(java.lang.String)
new:public org.ietf.foo.Foo buildFrom(java.lang.String)
Two months ago, I wasn't sure how to interpret and report on this code change. By looking at it from the perspective of the calling client code, it was instantly clear what I needed to do.
August 27, 2024
I fixed ListSymbols to include the return type of methods, so I can use its
output in -includes-list type of switches. The method nodes in dependency
graphs include the return type, so list elements need it too so they can match
nodes.
I added JaCoCo coverage report to the website. I just copied it into Git. This is simpler, for now, than figuring out how to do partial deployments in GitHub Pages.
I'm not thrilled that there is 0% code coverage for symbol printers.
August 23, 2024
Added steps to the GitHub Actions workflow that generates releases so it will also build the Docker image and upload it to Docker Hub.
August 22, 2024
Created a GitHub Actions workflow to generate releases. I found a way to pass
in the VERSION value to And, and through it, to Gradle. This way, Gradle can
include it in the JAR file's manifest, and Ant can use it when it generates
the Manual and Tools pages, as well as naming distribution files.
I found a trick where pushing a tag can trigger a workflow. The workflow has access to the tag name, so it can pass it to Ant and Gradle. I also found a GitHub Action that creates a release in GitHub and uploads the distribution files to it.
All I have left is to make the workflow create the Docker image and upload it to Docker Hub.
August 21, 2024
The text output from ListSymbols can be used with -includes-list and
-excludes-list command-line switches. Methods will have their full signature
matched against these lists, so I needed to change TextSymbolPrinter to show
full signatures instead of unique names.
I took the opportunity to rename the switches to ListSymbols. Since it
reports more than just names, now, I removed the name part of the switches.
-class-names⇒-classes-field-names⇒-fields-method-names⇒-methods-local-names⇒-local-variables-inner-class-names⇒-inner-classes
and
-non-private-field-names⇒-non-private-fields-final-method-or-class-names⇒-final-methods-or-classes
August 13, 2024
I played with reproducing the method name analysis from that article using a simple script in Ruby I picked Ruby for this example because it has built-in support for reading CSV files..
For example, I can get the top ten method prefixes with the following. First, I extract the method names to a CSV file.
ListSymbols
-method-names
-csv
-out symbols
lib/DependencyFinder.jar
Then, I can use this Ruby code to look at the names only, extract their prefix, and list the ten most common ones.
require 'csv'
prefix_histo = Hash.new {|hash, key| hash[key] = []}
CSV.foreach('symbols_method_names.csv', headers: true, strip: true) do |row|
name = row['name']
prefix_regex = /^([a-z]+)[A-Z].*/
match = prefix_regex.match(name)
prefix_histo[match[1]] << name if match
end
puts "Top Prefixes"
puts "------------"
prefix_histo.sort_by {|k, v| -v.size}[..10].each {|k, v| puts "#{v.size}\t#{k}"}
As of this writing, the top ten prefixes are:
Top Prefixes
------------
1524 get
651 visit
356 is
329 set
72 print
60 to
53 add
51 create
49 build
42 fire
36 has
August 12, 2024
Extracted the logic to break down symbols to SymbolPrinter and wrote
text and CSV variations.
Also added JSON, XML, and YAML formats after further refactoring.
August 11, 2024
Worked on CSV output for ListSymbols and breaking down symbols into
constituents. I'm trying it out in the CLI first. I'll have to extract it
later to some common place (com.jeantessier.classreader?) that can be shared
between the CLI and Ant tasks.
August 09, 2024
Refactored SymbolGatherer to track Visitable objects instead of only
String. The next step will be to separate output generation between text and
CSV, and I might also add YAML, JSON, and XML for good measure.
August 08, 2024
I read an article where they
categorize methods
by their first letter, their prefix, their suffix, or their functional
interface parameter. In the article, they apply this categorization to
java.util.stream.Stream, and look for any insights. It got me wondering if I
could do the same in Dependency Finder or arbitrary classes. Would it help
reveal any useful insights?
ListSymbols is an obvious candidate to host this functionality. It uses
SymbolGatherer, which only works in terms of strings. I need to refactor it
to track `Method_info` so I can more easily isolate the method name to tease
out prefixes and suffixes and so forth. I could have a tabular output where
I break down a method into its fully qualified class name, the method name,
the method signature, and its return type.
July 25, 2024
I found a library in Java to generate test objects with random data. It is
named Instancio. I read about it in
this article.
It looks somewhat akin to the
factory_bot gem in Ruby,
and the Faker library in Ruby and
JavaScript.
July 17, 2024
I want to replace the cgi-bin/Journal.cgi script with a static page. The
script takes too long to generate the contents from all the Journal entries.
I would like to automate the construction of a Journal.html static page as
part of the continuous build, so I can still edit individual files for each
Journal entry, but be able to load the Journal quickly when visiting the site.
I had a GitHub workflow that would generate Journal.html and saves it as a
build artifact. I needed to figure out how to deploy it to GitHub Pages
alongside the rest of the website.
I found a "standard" GitHub Pages deployment workflow by playing around with Pages settings on the GitHub repo. It packages all files it finds into a single archive and deploys it to GitHub Pages. I added steps to generate the static Journal page and Atom feed (and fixed some URLs), that now I have a CI that generates the static assets that I need.
July 08, 2024
Added code coverage using JaCoCo, a
descendent of EMMA. There is a
Gradle plugin
for it. I used a variation with a
standalone utility project
to get transitive dependencies between the various test subprojects and the
:lib subproject. I set up :integration-tests and :fit-tests as their own
subprojects, so they could encapsulate the test data and fixture classes that
each one needs. This makes it more complicated for JaCoCo to track coverage of
classes in :lib that are exercised by the tests in these subprojects.
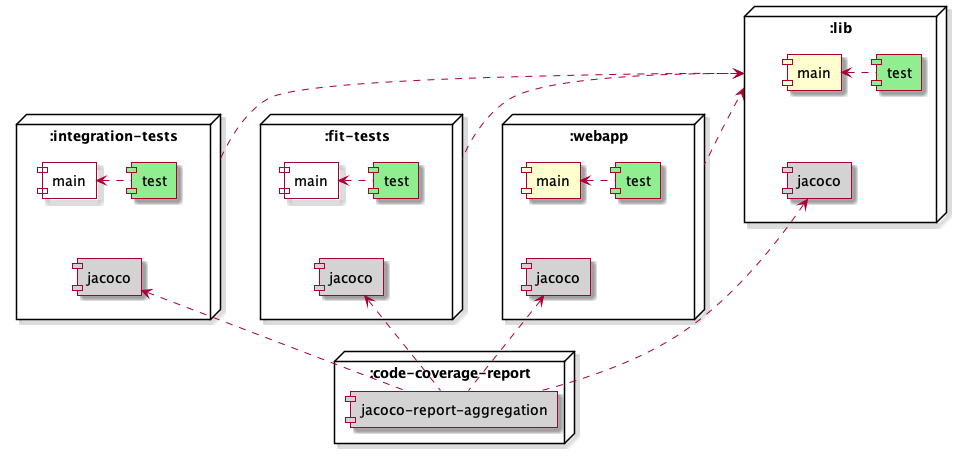
It seems the other code coverage tools I had been using in the past, like Cobertura, Clover, and EMMA, have fallen behind.
I also refreshed the Samples page to bring it up to date with the latest versions of Dependency Finder. It had been over 10 years since the last update. For some reason, the layout of the dependency graph page does not work properly with the latest graphs. I can't see any difference, and it works just fine when I point my browser to the local files, or serve them from my laptop using a local webserver. But when I load them from SourceForge, everything is against the left margin.
July 07, 2024
Used GitHub Actions to create the distribution files and store them in GitHub Packages. I will figure out how to create a release from them later. The examples I have, they use a tool to generate semantic versions. But, I am not quite ready for the level of involvement in supporting semver.
I also added a workflow to compile the Journal entries into a single HTML file. I could use it on the github.io to have the Journal page there too. I cannot run CGI scripts on GitHub, so I have to find a way to render static contents instead.
July 04, 2024
Is changing a signature to remove the need for a bridge method a change in signature or the removal of a method?
For example, imagine we have an API package defining interfaces for a Foo
abstraction and its factory FooBuilder.
package org.ietf.foo;
public interface Foo {}
public interface FooBuilder {
Foo buildFrom(String name);
}
If we can implement these interfaces in a separate implementation package, we can match the names of the classes to the interfaces they implement.
package com.acme.impl;
public class Foo implements org.ietf.foo.Foo {}
public class FooBuilder implements org.ietf.foo.FooBuilder {
public Foo buildFrom(String name) {
return new Foo();
}
}
Since there are no import statements, the implementation of buildFrom() has
a return type of com.acme.impl.Foo. Since it is a subtype of the Foo
interface, it satisfies the contract of buildFrom() from the FooBuilder
interface. But the compiler will create a bridge method with the correct
return type and have it call our implementation.
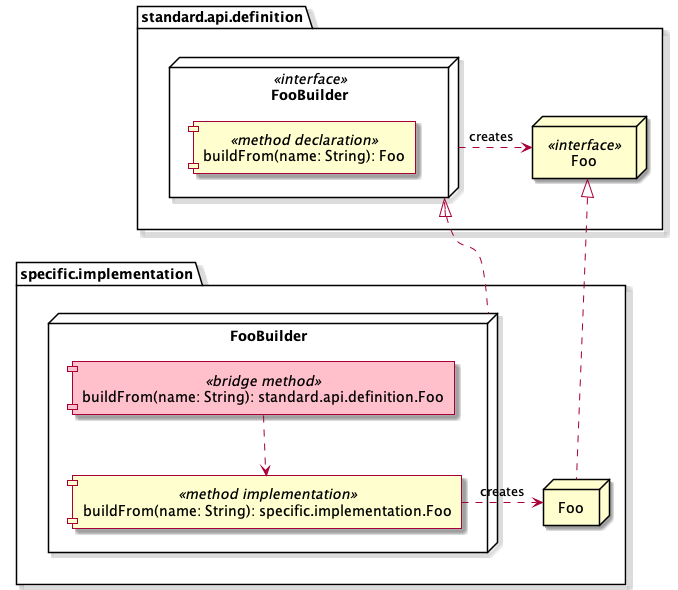
We can alleviate the need for a bridge method by giving our implementation the correct exact return type. It makes the implementation more verbose and potentially harder to read, though. Which is why we were using the form with the bridge method in the first place.
package com.acme.impl;
public class Foo implements org.ietf.foo.Foo {}
public class FooBuilder implements org.ietf.foo.FooBuilder {
public org.ietf.foo.Foo buildFrom(String name) {
return new Foo();
}
}
Now, the code looks as follows.
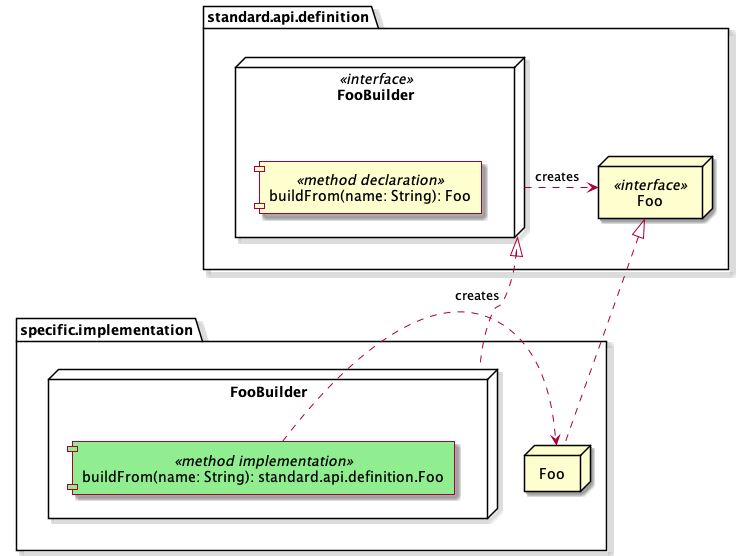
If I run both versions through JarJarDiff while it is using method
signatures to analyze differences, it reports:
Method Changes:
old:public com.acme.impl.Foo buildFrom(java.lang.String)
new:public org.ietf.foo.Foo buildFrom(java.lang.String)
That is, it completely ignores the bridge method and compares the change in the implementations of the interface.
But when I modify JarJarDiff to use methods' unique name instead, it
reports:
Removed Methods:
public com.acme.impl.Foo buildFrom(java.lang.String)
The bridge method is matched to the new implementation, and the old implementation has nothing to compare it against.
So, which is the correct interpretation? Is it a method change or did we remove a method?
July 03, 2024
Did a bit of refactoring. DifferencesFactory looks up fields by their name
and methods by their signature. I need it to do it by their unique name
instead. The original method to look up a Method_info is:
public Method_info getMethod(String signature) {
return methods.parallelStream()
.filter(method -> method.getSignature().equals(signature))
.findAny()
.orElse(null);
}
Instead of adding a separate variant just for uniqueName, I figured I could
use a functional interface to let me pass in what to match against. I can also
re-write the existing method in terms of the new functional interface, so I
don't break existing callers.
public Method_info getMethod(String signature) {
return getMethod(signature, Method_info::getSignature);
}
public Method_info getMethod(String name, Function<Method_info, String> getter) {
return methods.parallelStream()
.filter(method -> getter.apply(method).equals(name))
.findAny()
.orElse(null);
}
With this new getMethod() in place, the DifferencesFactory can call it with
Method_info::getUniqueName to find methods by their unique name.
I could even take it one step further and pass in an arbitrary criteria using
the Predicate functional interface.
public Method_info getMethod(String signature) {
return getMethod(signature, Method_info::getSignature);
}
public Method_info getMethod(String name, Function<Method_info, String> getter) {
return getMethod(method -> getter.apply(method).equals(name));
}
public Method_info getMethod(Predicate<Method_info> filter) {
return methods.parallelStream()
.filter(filter)
.findAny()
.orElse(null);
}
Now, it turns out there are just a couple of places where I use getMethod().
I converted these places to use Predicate instead.
oldClass.getMethod(signature);
became
oldClass.getMethod(method -> method.getSignature().equals(signature))
And with that, I only needed to keep the one version of getMethod() that
takes a Predicate. I did the same to locateMethod(signature),
getField(name), and locateField(name) to convert them all to using
Predicate as the criteria used in their search.
With this refactoring in place, I could run differences on unique methods by
changing DifferencesFactory to call:
oldClass.getMethod(method -> method.getUniqueName().equals(name))
With one caveat. The current logic uses signatures, like foo(int), and not
full signatures like some.package.Foo.foo(int). The current incarnation of
uniqueName is fully qualified, and I'm afraid it will break API differences,
especially when ClassClassDiff tries to compare two classes with different
names.
So, I split the existing getUniqueName() into a method called
getUniqueName() that returns an unqualified foo(int): void and another
method called getFullUniqueName() that returns the fully qualified version
with package and class names. I changed all the places where I had been using
getUniqueName() to call getFullUniqueName() instead. Actually, it was the
other way around: I did the renaming first, and then I split them.
July 02, 2024
Created the GitHub Action
jeantessier/test-summary-action
as a separate project. I can use it instead of the custom Ruby code in
Dependency Finder, and remove all needs for Ruby to keep it simple.
July 01, 2024
Updated the JUnit dependency to JUnit Jupiter (JUnit 5). The tests are still written for a mix of JUnit 3 and JUnit 4, but at least the package dependency should now be up-to-date. I received a security warning from GitHub, and I'm hoping this upgrade addresses it.
I also added a step in the GitHub Actions workflow to report on tests that
pass and/or fail as part of the job summary. The information I need is in XML
files produced by JUnit. I used Ruby and the nokogiri gem to parse the XML
and generate a Markdown table. I am not too keen to introduce yet another
language, Ruby, in Dependency Finder. But, it is the quickest and simplest way
to parse XML files and extract the information I need. It is only in the
GitHub Actions workflow. For now.
I could extract the test summary logic into my own GitHub Action, separate from Dependency Finder. This would keep the Ruby code out. This new action could either be a Docker container or a composite action that calls Ruby from the runner's shell.
Someone wrote a test-summary GitHub
Action that does a similar job. This could be a way to not have to
introduce Ruby into Dependency Finder.
June 30, 2024
The next release will be 1.4.0. The change to method unique names will break
some setups out there, just like I've been updating regular expressions in
Dependency Finder itself.
I renamed the master branch to main.
I've been experimenting with GitHub Actions. I set up a workflow that runs
./gradlew build, which builds everything and runs all tests. I still have to
figure out how to publish distributions and Docker images from GitHub Actions.
June 28, 2024
Use methods' unique name in the dependency graph. And also for fields, for
good measure. As it turns out, all that was required was to update a regex in
NodeFactory and another regex in TextPrinter.
OOMetrics relied on Deprecated_attribute to find deprecated classes. But
it used Feature_info.isDeprecated() for fields and methods. I removed the
inconsistency, and now OOMetrics no longer looks at Deprecated_attribute
directly. It's all hidden behind isDeprecated() methods.
June 27, 2024
Moved the logic to build unique names for method metrics to Feature_info and
FeatureRef_info, so they can be consistent across client packages. Fields
just use their name, and methods append their return type to their signature.
Constructors and class initializers are exempt.
I also updated the copyright notice to 2024.
June 25, 2024
Updated the OOMetrics documentation to use the new names of method metrics.
And fixed a number of typos across the documentation in the process.
June 24, 2024
Continued work on issue #8.
It turns out everywhere in OOMetrics where I used a method's signature ended
up using the new key. So, I faced reality and make this key the actual
name of method-level metrics.
Completed the tests for all metrics printers. They now cover all outputs and a few additional variations.
June 20, 2024
Worked on issue #8.
I added an indexing key to Metrics, separate from their name, for use
when tracking metrics. For project-, group-, and class-level metrics, it is
the same as their name. But for methods, it is the combination of the method's
signature and its return type. Some synthetic methods have the same signature
as an existing method, but will have a different return type (e.g.,
erasures,
bridge methods).
I had to change references to method names to use the key instead, so each variation gets reported correctly.
I added some tests for the various metrics printers. Keeping track of all the
hidden vs. empty options was getting too complicated to do in my head. I put
the expected output in files under integration-tests/src/test/resources and
the tests generate an actual output and compare it to the expected output from
the files. These tests can be somewhat fragile if the output changes a lot,
but I don't feel this will be the case here. I could use data-driven tests to
generate most variations. I use the MartinConfig.xml configuration because
it has hidden measurements, and it surfaces all variations of empty metrics,
hidden measurements, etc.
In the process of testing the printers, I realized the JSON printer was missing
a newline character at the end of its output. I had noticed a weird character
when I called OOMetrics -json, but never understood that it was because of a
missing newline. Now, this mystery is solved.
June 19, 2024
Removed the synchronization around the firing of events. Synchronizing the list of listeners makes a lot of sense if listeners keep registering and de-registering while we are firing events. But in Dependency Finder, we set up the listeners are the beginning and don't change them once the main processing starts. There is no need to synchronize this list when we are firing events. I was copying the list of listeners in a synchronized block to keep the critical section short. By removing the critical section, I don't need to copy lists all the time anymore.
I wrote CodeSpliterator, as a simile to CodeIterator, so the
Code_attribute can expose a Stream<Instruction> via its stream()
method.
June 18, 2024
There were some flaky tests in the metrics printers. Looking into it, it
turned out that when generating random percentiles, they sometimes used the
value 0. Percentiles have to be 0 < p ≤ 100, so a value of 0 was
causing problems.
OOMetrics and ClassMetrics were only using Synthetic_attribute to
identify synthetic elements and they were ignoring elements that have the
ACC_SYNTHETIC in their access_flags. I refactored them to use the
helper method isSynthetic(), which adequately checks both the attribute and
the access flags.
I also updated both OOMetrics and ClassMetrics to include reports of all
variations of classes, fields, methods, and inner classes. They had fallen
behind during the update to Java 21. I took this opportunity to refactor
ClassMetrics to remove a lot of duplication in how it prints reports. When I
switched to the Streams API, I mistakenly added quite a few empty lines in
reports with the -list switch. I was able to restore the look of the reports
back to how it was before, while preserving the new additions.
June 13, 2024
Every once in a while, an item in the Classfile structure will reference an
entry in the constant pool. The constant pool index starts at 1 and the
Classfile structure uses a special value of 0 to indicate an empty
reference. For example, Classfile has a item called super_class that
indicates the superclass of the current class being described by the
Classfile. The item super_class can have the value 0 if the current
class does not have a superclass, e.g., Object or interfaces.
For each of these items, the interfaces in com.jeantessier.classreader expose
a number of methods to get the index value, the raw constant pool entry, or a
more helpful value. For example, for super_class, we have:
int getSuperclassIndex()Class_info getRawSuperclass()String getSuperclassName()
In the code, when we need to verify if there is a superclass or not, we would
check the value of getSuperclassIndex(). This introduces a magic constant
0 that means "there is no superclass."
Magic constants tend to make the code harder to read. So, I added a new method for such items:
boolean hasSuperclass()
The new method handles the check for 0 so the magic constant does not spread
throughout the code. It makes the client code easier to read.
Since I had a pervasive pattern for checking for 0 everytime I looked up
these items from the constant pool, I found a few places where I was checking
for 0 when the specification clearly states that it must not be zero. In
these cases, I removed the check and I expect the Classfile structure to be
compliant with the specification.
June 07, 2024
Looked at adding percentiles to OOMetricsGUI. I haven't looked at the Swing
code that makes up the GUI applications since I first wrote it over 20 years
ago. It uses sets of constants to build column names, so the set of subvalues
is essentially hard-coded. I will have to do some major refactoring of the
models that feed the GUI to make column names more dynamic and make them based
on what's in the metrics configuration.
June 06, 2024
Added percentiles to the CLI and Ant versions of OOMetrics. In the process,
I wrote unit tests for all the subclasses of com.jeantessier.metrics.Printer.
June 05, 2024
Found another problem, and this one is a big one.
I've always assumed field names and method signatures were unique within a given class. After all, the Java language specification states that:
It is a compile-time error for the body of a class declaration to declare two fields with the same name.
It is a compile-time error to declare two methods with override-equivalent signatures in a class.
While this is true for Java code that you feed to the compiler, it is not strictly true inside the classfile structure. Bridge methods are allowed to share a signature with the method they are a bridge for. Here is an example.
Suppose an interface package a.
package a;
public interface Foo {}
public interface FooCreator {
Foo buildFrom(String name);
}
And its implementation package a.impl:
package a.impl;
public class Foo implements a.Foo {}
public class FooBuilder implements a.FooBuilder {
public Foo buildFrom(String name) {
return new Foo();
}
}
The interface method a.FooBuilder.buildFrom(String) returns an instance of
interface a.Foo. The implementation method
a.impl.FooBuilder.buildFrom(String) is returning an instance of class
a.impl.Foo. This is legal, since a.impl.Foo is a a.Foo. While the
methods' signatures match, their descriptors do not, because the return
types are different.
To resolve this, the compiler generates a bridge method in
a.impl.FooBuilder that reconciles the descriptors. It has the same signature
as the implementation method, but the descriptor matches the one from the
interface. It is as if the implementation
This code will not compile because there are two methods
with the signature buildFor(String).
had been:
package a.impl;
public class Foo implements a.Foo {}
public class FooBuilder implements a.FooBuilder {
public Foo buildFrom(String name) {
return new Foo();
}
public a.Foo buildFrom(String name) {
return buildFrom(name); // meaning, the other method defined above
}
}
In this case, you could fix it by explicitly returning the interface type in the declaration of the implementation method.
package a.impl;
public class FooBuilder implements a.FooBuilder {
public a.Foo buildFrom(String name) {
return new Foo();
}
}
But this may be impractical if package names are long, or if the result is one method with a very long declaration when all the other methods in the class are much more concise.
Sometimes, it is inevitable. Consider the following interface and its
implementation.
Funnily, when I tried to run ClassReader on this
Wrapper class, I found another bug. A name deep inside an attribute
structure turns out to be optional and, my code assumed it was always
present.
public class Wrapper<T> implements Comparable<Wrapper<T>> {
private final T wrappedObject;
public Wrapper(T object) {
wrappedObject = object;
}
public int compareTo(Wrapper<T> other) {
// Implementation compares
// "this" to "other" and returns
// -1, 0, or 1 as appropriate.
}
}
After type erasure, Comparable demands a method with the signature
compareTo(java.lang.Object). But the compiler demands that we write a method
with the signature compareTo(Wrapper<T>). We will not be able to avoid
this bridge method.
Classfile stores a collection of methods, so the bridge methods and the
methods they are bridging are present and accounted for.
Now, for the bug. There are times in Dependency Finder when I use maps to store information about methods. These maps are keyed on the methods' signature. For example:
FeatureNodein a dependency graph- method-related differences
- method-related metrics
Classfile.getMethod(String)will return the first method with a matching signature, but it searches the methods in an indeterminate order.
Depending on the case, two methods with the same signatures may end up merged together (this is the case in dependency graphs), or one method may completely mask the other (this is the case in difference reports).
I will need to identify all the places where I use a maps keyed on method signatures and figure out an alternative implementation, including changing assumptions downstream from them that methods signatures are unique within a class.
June 04, 2024
Wrote a bunch of unit tests for CSVPrinter to specify its exact behavior.
Added skinparam backgroundColor transparent to PlantUML diagrams so they look
better on the Journal page, which gets an off-white background from Tufte CSS.
June 03, 2024
Fourteen years later after the fact, I find out that
"Users are encouraged to use similar features in
newer Java versions, where available."
Jakarta ORO has been retired. I use it
all over the place in DependencyFinder, so I will not be ripping it out any
time soon. But I might start using java.util.regex in select places,
especially when the Streams API makes it even more powerful.
I came up with a way to request various percentiles as part of the init text
for StatisticalMeasurement. It was nice and contained in the measurements
themselves, until I got to CSVPrinter. It prints a header that would need
column names for each requested percentile, but it hasn't seen the measurements
at this point. It operates solely in terms of descriptors, and the descriptors
are measurement type agnostic. The printer already has a special case for
StatisticalMeasurement, so I could call static methods of this class to help
me figure out the percentile columns.
I found a troubling bug in com.jeantessier.metrics.TextPrinter. It renders
all metrics according to the project-level measurement descriptors. It renders
group-level, class-level, and method-level metrics as if they had been
populated with the project-level descriptors. This means that it does not
render any measurement whose name does not appear among the top, project-level
configuration.
I first noticed it when my class-level report in CSV had a
"Character Count" CNCC measurement that did not appear in text reports,
even though all the other switches were the same.
Most of the other printers,
JSONPrinter, XMLPrinter, and YAMLPrinter, explicitly navigate down to
each level and pass on the appropriate collection of descriptors. For
CSVPrinter, it is done externally by the calling tools. But TextPrinter
uses a single collection of descriptors for all metrics and this needs to be
fixed.
June 02, 2024
Refactored StatisticalMeasurement to add percentiles. The statistics that it
exposes are minimum, median, and maximum. But this does not tell us how far
outliers are from the other results. For that, it would be helpful to have
values line the 90th percentile or the 99th percentile.
And maybe even the 1st and 10th percentile for the lower
end of the range. Maybe, once I have a percentile function, I can replace
getMedian() with the 50th percentile!
I keep thinking of the median as a value from the set. But looking at the code, I noticed it was averaging the two central values when the dataset had an even number of elements. That is how they recommend to do it on Wikipedia, and it is likely where I picked it up. So I left the calculation of the median as it was, but with a little bit of clean up to use the Streams API and inline some trivial methods.
I did add getPercentile(n) and I will look for the best way to expose
percentiles in OOMetrics reports. I could use canned percentiles, like
1, 10, 50, 90, and 99, but I'd like to let users decide which
percentiles make sense for them. Maybe there is a way to specify them in the
configuration, as part of the initialization text for StatisticalMeasurement.
May 31, 2024
Switched the Introduction page and the Journal page to Tufte CSS.
I have been using Tufte CSS for my personal blog for a few years now, and I like the look. It uses white space intelligently to help the eye read the text with minimal straining. I write my blog using Markdown and a JavaScript library converts it to HTML in the browser. This conversion step sometimes interfere with some of the features of Tufte CSS, so I cannot use it to its full potential. But the Journal page is rendered HTML on the server, and I have complete control on it. I can use features like sidenotes and figures to their fullest.
May 23, 2024
Drew up a map of all the tools that create classfile loaders and will need an extra parameter to target JDK versions when reading multi-release JAR files.
The green ones use TransientClassfileLoader. The red ones use
AggregatingClassfileLoader. Two-colored ones, like OOMetrics, use both.
The yellow boxes use neither.
May 22, 2024
Worked on JarClassfileLoader to handle multi-release JAR files and only load
a single version of a class, potentially based on a target JDK. The changes
removed any commonality there was between ZipClassfileLoader and
JarClassfileLoader, so I made them sibling classes instead of one inheriting
from the other. When loading a JAR file from an InputStream, I copy it to a
temporary file so I can better use the Streams API to sort and filter entries.
Next, I will have to update all the tools and their documentation to add a switch to target specific JDK versions.
Created a multi-release JAR file from the command line. I'm using the same
.class file multiple times. I just need to have the same class in multiple
META-INF/versions/N locations.
jar cf multi.jar -C integration-tests/build/classes/java/main test.class
jar uf multi.jar --release 17 -C integration-tests/build/classes/java/main test.class
jar uf multi.jar --release 9 -C integration-tests/build/classes/java/main test.class
jar uf multi.jar --release 22 -C integration-tests/build/classes/java/main test.class
jar uf multi.jar --release 21 -C integration-tests/build/classes/java/main test.class
And here is the resulting JAR file.
jar tf multi.jar
META-INF/
META-INF/MANIFEST.MF
test.class
META-INF/versions/17/test.class
META-INF/versions/9/test.class
META-INF/versions/22/test.class
META-INF/versions/21/test.class
May 21, 2024
Wrote a test to create a multi-release JAR file and read it using
JarClassfileLoader. I don't quite know how I will approach processing
the JAR file to zero-in on a single .class file, but I now have a test in
place to let me know how I'm doing.
May 13, 2024
I am looking for a way to pick a single version of a class from a multi-release
JAR file. Such JAR files can contain any number of versions of a given class
in various META-INF/versions/N directories, plus a default version in the
top-level directory. If I ignore the META-INF/versions/N directories, then
I might be ignoring more advanced versions. If I only look at the first file I
encounter, then I might be picking an arbitrary version.
JAR files tend to list files in alphabetical order, so it might list versions
of an example class com.foo.Bar as:
META-INF/versions/11/com/foo/Bar.classMETA-INF/versions/17/com/foo/Bar.classMETA-INF/versions/21/com/foo/Bar.classMETA-INF/versions/22/com/foo/Bar.classMETA-INF/versions/9/com/foo/Bar.classcom/foo/Bar.class
This JAR file supports up to JDK 22. But maybe the user is limited to JDK 17 for business reasons. They would want to analyze the JDK 17 version and ignore all others.
JAR files tend to list files in alphabetical order, but they don't really have to.
I could add some filtering function in JarClassfileLoader. But its usage is
buried pretty deep in the framework. It would be difficult to pass a filtering
criteria for which JDK version to target through constructors. I could add a
filter between the loader and the visitor.
loader.addLoadListener(new MultiReleaseFilter(targetJDK, new LoadListenerVisitorAdapter(gatherer)));
The filter could zero in to the most adequate version that meets the
targetJDK criteria. It would need receive versions in decreasing order of
JDK version, so I might have to tweak JarClassfileLoader anyway. It would
traverse JAR file entries in order of version instead of alphabetically.
META-INF/versions/22/com/foo/Bar.classMETA-INF/versions/21/com/foo/Bar.classMETA-INF/versions/17/com/foo/Bar.classMETA-INF/versions/11/com/foo/Bar.classMETA-INF/versions/9/com/foo/Bar.classcom/foo/Bar.class
If the target is JDK 19, it would forward events about the third entry and skip all others.
May 10, 2024
Added SingleValueMeasurement to fix the problem with tracking major and
minor version numbers in OOMetrics.
It doesn't fix the problem with processing multiple copies of the same class in multi-release JAR files, though.
For example, I extracted log4j-api.jar to /tmp so I could analyze the
various versions of the Base64Util class separately.
For the JDK 8 version of the class in the top-level declaration:
OOMetrics \
-txt \
-classes \
-methods \
/tmp/log4j-api/org/apache/logging/log4j/util/Base64Util.class
Class metrics
-------------
org.apache.logging.log4j.util.Base64Util
Major Version (MaV): 52
Methods (M): 3
Attributes (A): 2
Inner Classes (IC): 0
Single Lines of Code (SLOC): 27
Subclasses (SUB): 0
Depth of Inheritance (DOI): 0
Method metrics
--------------
org.apache.logging.log4j.util.Base64Util.Base64Util()
Single Lines of Code (SLOC): 1
org.apache.logging.log4j.util.Base64Util.encode(java.lang.String)
Single Lines of Code (SLOC): 8
org.apache.logging.log4j.util.Base64Util.static {}
Single Lines of Code (SLOC): 15
For the JDK 9 version of the class in the META-INF/versions/9 directory:
OOMetrics \
-txt \
-classes
-methods \
/tmp/log4j-api/META-INF/versions/9/org/apache/logging/log4j/util/Base64Util.class
Class metrics
-------------
org.apache.logging.log4j.util.Base64Util
Major Version (MaV): 53
Methods (M): 3
Attributes (A): 1
Inner Classes (IC): 0
Single Lines of Code (SLOC): 5
Subclasses (SUB): 0
Depth of Inheritance (DOI): 0
Method metrics
--------------
org.apache.logging.log4j.util.Base64Util.Base64Util()
Single Lines of Code (SLOC): 1
org.apache.logging.log4j.util.Base64Util.encode(java.lang.String)
Single Lines of Code (SLOC): 1
org.apache.logging.log4j.util.Base64Util.static {}
Single Lines of Code (SLOC): 1
When I run OOMetrics on both files at the same time, notice how the SLOC
and A measurements adds up across both versions of the class.
OOMetrics \
-txt \
-classes \
-methods \
/tmp/log4j-api/META-INF/versions/9/org/apache/logging/log4j/util/Base64Util.class \
/tmp/log4j-api/org/apache/logging/log4j/util/Base64Util.class
Class metrics
-------------
org.apache.logging.log4j.util.Base64Util
Major Version (MaV): 52
Methods (M): 3
Attributes (A): 3 // 2 + 1
Inner Classes (IC): 0
Single Lines of Code (SLOC): 32 // 27 + 5
Subclasses (SUB): 0
Depth of Inheritance (DOI): 0
Method metrics
--------------
org.apache.logging.log4j.util.Base64Util.Base64Util()
Single Lines of Code (SLOC): 2 // 1 + 1
org.apache.logging.log4j.util.Base64Util.encode(java.lang.String)
Single Lines of Code (SLOC): 9 // 8 + 1
org.apache.logging.log4j.util.Base64Util.static {}
Single Lines of Code (SLOC): 16 // 15 + 1
The Major Version measurement now uses the new SingleValueMeasurement, so it
takes the value of the last version that was visited. When analyzing a JAR
file, OOMetrics visits the versions in META-INF/versions/N before the
top-level version.
May 09, 2024
Found a problem with how OOMetrics collects major version information. It
assumes it visits each class only once, which may not always be the case. I
found at least two situations where it visits a class more than once. Since
MetricsGatherer calls addToMeasurement(), it ends up accumulating the value
of major version, leading to confusing results.
The first case is module-info. Module information is stored in a top-level
.class file named module-info.class. It contains a classfile structure
with the ACC_MODULE flag turned on, the name `module-info`, is part of the
default package, and it doesn't have a superclass. If you run OOMetrics on
multiple JAR files together, it is possible that more than one of these files
will have a module-info.class entry and OOMetrics will treat them as
multiple presentations of the single module-info "class". When it processes
the "Major Version" measurement, it adds the value of the major version to
the measurement instance. If two module-info.class files have the major
version 61, the resulting metrics measurement has a value of 122.
Unfortunately, OOMetrics only has method, class, group, and project
levels of metrics. Either it can treat module-info as a class, when it is
not one, or it can ignore it altogether. It is probably unlikely that it would
have a different major version from the actual classes in the JAR file, so we
would not lose any information by ignoring it.
I came across the second case while running OOMetrics against the LOG4J
archives. It has to do with "Multi-release JAR files", as described in the
JAR File Specification.
The META-INF/versions/N directory inside each JAR file can have additional
.class files that replace the top-level declaration of their respective
class. For example, log4j-api.jar has both:
META-INF/versions/9/org/apache/logging/log4j/util/Base64Util.classwith major version53org/apache/logging/log4j/util/Base64Util.classwith major version52
Again, OOMetrics traverses both classfile structures but uses the same
Metrics instance for class Base64Util to aggregate measurements across both
structures. The result is a "Major Version" measurement of 105.
Instead of using a CounterMeasurement with an add() method that accumulates
values, I could create a new type of measurement that only records the first or
last value passed to add(). The only visitors are printers, so the impact
would be contained.
February 22, 2024
I discovered Apache ECharts as a JavaScript library for building charts in the browser.
Here is an example, with charts about the Robert C. Martin metrics for Dependency Finder.
January 29, 2024
Dependency Finder is now 23 years old.
January 26, 2024
Refactored Log4J calls to use lazy string interpolation.
Lines like:
debug("msg " + val);
became:
debug("msg {}", val):
So Log4J only does the string interpolation if the log is enabled.
Some lines where a value was expensive to compute became:
debug("msg {}", () -> val);
So that even the computation is deferred until the log actually needs it.
January 24, 2024
Replaced Log4J with Log4J2. This meant changing log4j.properties to
log4j2.properties and adapting it to the new format. I could have used the
XML format, which all Log4J2 docs use, or the YAML format, but the properties
file seemed most straightforward way to go for now.
I also figured out how to copy JAR files from Gradle dependencies, instead of
fetching them by hand and hard-checking them in Git. As a result, I had to
rework the launching script to dynamically build a CLASSPATH from the list of
JAR files in lib/.
I don't know how to do that under Windows, so all the Windows launching scripts are broken at the moment.
I removed the scripts to run JUnit since I run JUnit through Gradle, now.
I removed the scripts to run Chainsaw since it no longer ships with Log4J, but as a separate download.
January 23, 2024
Removed some unnecessary dependencies from Gradle subprojects. Also removed some unnecessary uses of Log4J in tests.
January 19, 2024
I'm looking into what it would take to include Java modules as an additional
layer of the dependency graph, above packages. The Module attribute has
requires structures to get the modules that are dependencies of the current
module, and uses structures for services, possibly in other modules, that it
references. I could use the ModulePackages attribute lists the packages in a
module, but I would need some mechanism to unclaimed packages to the default
unnamed module.
The Node hierarchy is not an articulation point in the design of Dependency
Finder. Adding a new kind of dependency would have a sizeable impact (i.e., a
large blast radius).
As I was looking at Fit tests, my IDE kept complaining that
<table border="1"> is no longer valid HTML. I tried replacing it
with CSS, only to realize that the FitNesse CSS was overwriting it anyway. I
took the opportunity to remove all these obsolete border attributes in Fit
tests.
December 15, 2023
I moved the Ant logic that was in integration-tests/jarjardiff/build.xml to
the :integration-tests:jarjardiff:old Gradle subproject. I managed to create
the archives in the :integration-tests:jarjardiff:old subproject, but I'm not
quite sure on the best way to move them back up to either the
:integration-tests:jarjardiff subproject or the :integration-tests
subproject. For now, the tests that use these archives use explicit paths into
the integration-tests/jarjardiff/old/build/archives folder.
Now, I can run:
./gradlew check
from a clean folder, and it takes care of everything.
December 14, 2023
I merged the migration to Gradle back into the master branch. I verified
that everything works: exec environment, distribution files, WAR file, and the
Docker image. I still need Ant at the top level to coordinate some last
cross-project dependencies, until I can figure out how to do it from within
Gradle.
Adjusted the Docker instructions to use Gradle instead.
Refreshed the Tutorial on the website. The old HTML was geared towards Internet Explorer and no longer works in modern browsers. I don't have access to PowerPoint anymore, so I loaded it in Apple's Keynote and saved as HTML again. I also added a PDF version.
December 13, 2023
Fixed Ant targets for Tomcat 7+. I have an experimental branch from 2011-05-19 that was trying to do that too. I had noted back then that HttpUnit tests were not able to launch the webapp.
Fixed webapp descriptor location in the :webapp subproject. Gradle expects
all webapp-related files to be under src/main/webapp.
Fixed location of javadocs and GUI resources in :lib subproject. Gradle
expects all non-Java files to be under src/main/resources.
Cleaned up distribution files to remove duplicate JAR files.
December 10, 2023
Moved the remaining build.test.xml logic to build.xml. Moved the last bits
of tests/JarJarDiff to the :integration-tests:jarjardiff subproject.
Cleaned up tests and their imports.
Removed source and *.bz2 distribution archives. The sources are
automatically available via GitHub; it even puts them as release files without
having to ask for it.
Skipped all :webapp tests. I had to convert them to JUnit 4 so I could use
@Ignore to skip them. Now, I can just type ./gradle check and it runs all
tests across all subprojects (and skips the HttpUnit tests).
December 08, 2023
Migrated the Fit tests to a Gradle subproject called :fit-tests. I was able
to "upgrade" fitlibrary from 20060116 that I had been using until now to
20070619. The next version up introduces some changes that break my tests.
I think something changed in DoFixture, but I cannot find release notes that
would explain how to update my tests. It's been 16 years, so I'll have to do
some digging.
December 07, 2023
I successfully separated the pure unit tests from "integration tests" that need
test data: compiled Java code. The main :lib subproject can run all the unit
tests that don't require external data. The :integration-tests subproject
has the sample code that the other tests are running against. I don't know how
to effectively share test data between projects, yet. So the tests dig
directly into the subprojects to find what they need.
I moved the webapp code to its own subproject. It seems to compile fine, but the HttpUnit tests are broken. They were broken to begin with, so they will need more work later. But the status quo is preserved.
December 06, 2023
Created a branch to try and move at least of the build to Gradle. I can still have Ant at the top level and use it to call some Gradle builds to generate some of the artifacts. Until I can find a way to migrate all Ant tasks over time.
November 30, 2023
Experimented with replacing Ant with Gradle. New versions of Gradle use
sub-projects to organize the build. My Ant-based build has a lot of custom
pieces, like compiling sample code for the tests to parse and operate against.
I can compile them in sub-projects, but it's not clear how to share build
products between sub-projects. The documentation shows how to share JAR files
on CLASSPATH, but what I want is read them from some of the tests. I could
have all the unit tests in one sub-project and have "integration" tests that
also depend on sample code in another sub-project. I could also build the WAR
file in a sub-project separate from the library JAR file. Lots of
possibilities, but wiring it all together will be a challenge.
November 22, 2023
Cleaned up the com.jeantessier.commandline package.
November 20, 2023
Finished removing the explicit public qualifiers from interfaces in
com.jeantessier.classreader. I also moved some behavior from abstract base
classes to default methods in their related interfaces.
More for() loops converted to Stream API. More dead code removed, more
hand-written mocks replaced with jMock.
November 19, 2023
I'm finally getting rid of explicit public qualifiers in interfaces. The
Java 21 language specification says it is discouraged.
I moved some default implementations to default methods in interfaces instead
of abstract base classes in the dependency, diff, and metrics packages.
I also converted more for() loops to the Stream API, and even wrote a custom
Spliterator for use in DescriptorHelper.
I realized that after I started processing StackMapTable_attribute for
dependencies, I inadvertently introduced dependencies on arrays of primitive
types. A stack frame might reference a local byte[] with the descriptor
"[B" and reference it via a Class_info in the constant pool. The
CodeDependencyCollector would mistakenly parse it as a type B[] and treat
that as the name of a class. I fixed it so it ignores them from now on, just
like it ignores dependencies on primitives in general.
November 14, 2023
Cut release 1.3.1 which includes dependencies on lambdas, method references,
and other dynamic callsites.
November 13, 2023
Renamed InvokeDynamicFinder to ListDynamicInstructions. Wrote
documentation for this new tool.
I found some documentation on callsites in the javadocs for the
java.lang.runtime.SwitchBootstraps
class and the
java.lang.invoke
package. It is very technical, and I'm not sure how exhaustive it really is.
I'm tempted to move up to Java 21 so I can use type pattern matching in
switch expressions. They make the code much more compact and streamlined.
It turns this somewhat awkward code:
Object owner = attribute.getOwner();
if (owner instanceof Classfile classfile) {
syntheticClasses.add(classfile);
} else if (owner instanceof Field_info field) {
syntheticFields.add(field);
} else if (owner instanceof Method_info method) {
syntheticMethods.add(method);
} else {
Logger.getLogger(getClass()).warn("Synthetic attribute on unknown Visitable: " + owner.getClass().getName());
}
Into this:
switch (attribute.getOwner()) {
case Classfile classfile -> syntheticClasses.add(classfile);
case Field_info field -> syntheticFields.add(field);
case Method_info method -> syntheticMethods.add(method);
default -> Logger.getLogger(getClass()).warn("Synthetic attribute on unknown Visitable: " + attribute.getOwner().getClass().getName());
}
But if I do this, I will need to compile the library to Java 21 and users will need to be on Java 21 to use Dependency Finder.
November 12, 2023
Wrote InvokeDynamicFinder, a tool to show the object graph rooted at
invokedynamic instructions. It helps me see better the variations in
callsites, so I can better determine if CodeDependencyCollector is doing a
good enough job or not.
November 11, 2023
I realized ClassMetrics uses lists to accumulate elements, so it needs some
major deduping. I switched to TreeSet to get rid of duplicates and sort the
elements alphabetically to boot. I had to make Classfile and Field_info
and Method_info implement Comparable so I could store them in TreeSet.
I took to opportunity to refactor the compareTo() and equals() methods to
replace if cascades with guard clauses. They are more fashionable.
November 10, 2023
All these dependencies to java.lang.invoke were bugging me, so I refactored
the default traversal in VisitorBase to do something special in the case of
invokedynamic instructions. I added
Instruction.getDynamicConstantPoolEntries() to look for MethodHandle_info
in arguments to bootstrap methods and collect what these handles are
referencing. This way, I can skip java.lang.invoke artifacts in dynamic
calls and focus on what the code is trying to express.
Going back to the sample code from issue #6:
import java.util.function.*;
public class Test {
public void someMethod(){
Consumer<String> function = (x -> System.out.println(x));
}
}
The dependency graph now looks like this:
Test
--> java.lang.Object *
Test()
--> java.lang.Object.Object() *
lambda$someMethod$0(java.lang.String)
--> java.io.PrintStream *
--> java.io.PrintStream.println(java.lang.String) *
--> java.lang.String *
--> java.lang.System.out *
<-- Test.someMethod()
someMethod()
--> java.lang.String *
--> Test.lambda$someMethod$0(java.lang.String)
And even ClassReader now shows the intended reference:
public void someMethod();
CODE
0: invokedynamic void test.Test.lambda$someMethod$0(java.lang.String)
5: astore_1
6: return
November 09, 2023
Now that I have code to parse BootstrapMethods_attribute, I can do a better
job at processing invokedynamic instructions for dependencies. Someone
opened issue #6
about tracking dependencies on lambdas. Lambdas are called using the
invokedynamic instruction, but go through a callsite to figure out what
actual method to call. The callsite resolves the target using data from the
BootstrapMethods_attribute.
Issue #6 includes this sample code:
import java.util.function.*;
public class Test {
public void someMethod(){
Consumer<String> function = (x -> System.out.println(x));
}
}
Running it through javap -c shows the following:
public class Test {
public Test();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public void someMethod();
Code:
0: invokedynamic #7, 0 // InvokeDynamic #0:accept:()Ljava/util/function/Consumer;
5: astore_1
6: return
}
Here is a diagram of the information structure for where the method calls the lambda (click for larger version).
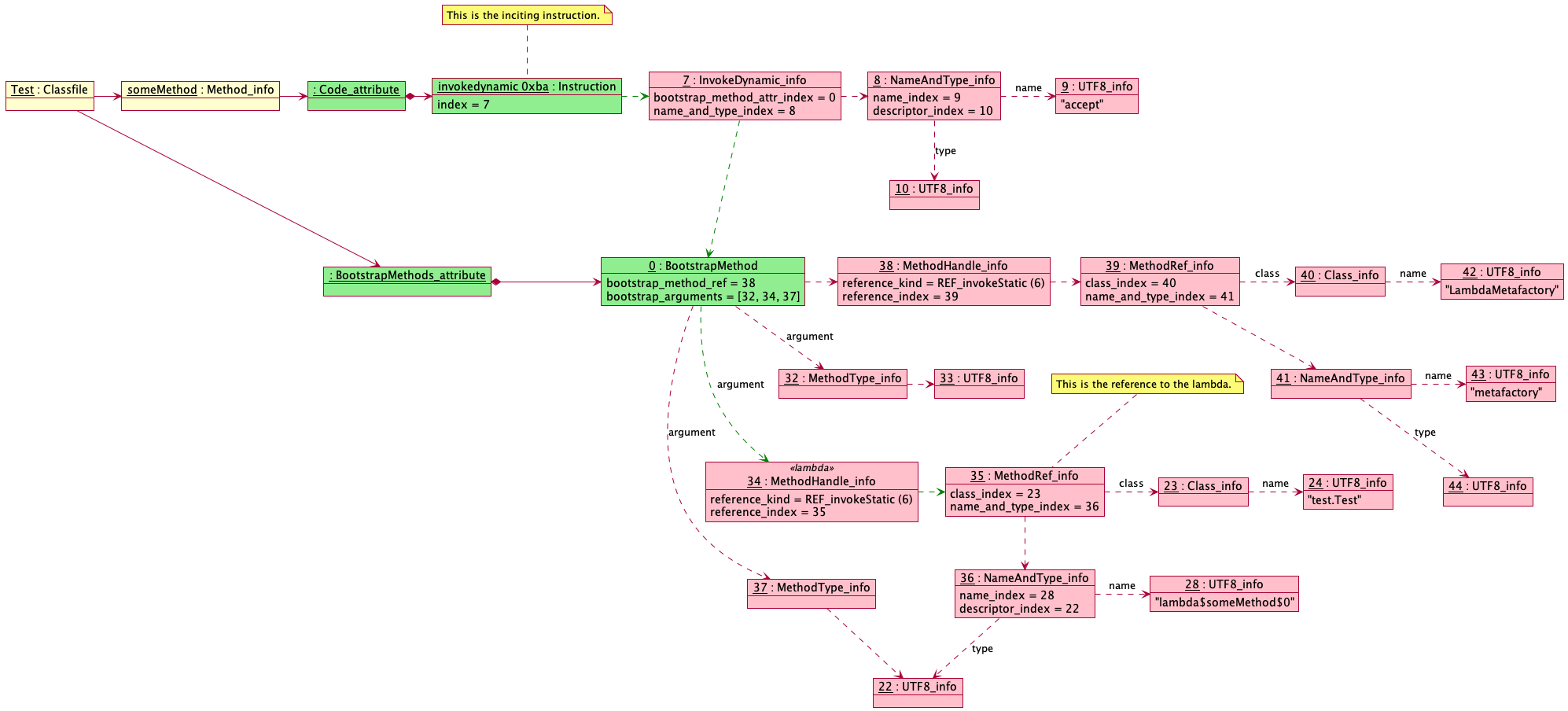
Attributes are shown in green and constant pool entries are shown in pink, with their index in the constant pool.
We see that javap stopped at the InvokeDynamic_info that the instruction
points to, at index 7 in the constant pool. It only showed the information
from the NameAndType_info at index 8 in the constant pool. With Dependency
Finder, I can follow the references all the way to the MethodRef_info for
the lambda (index 35 in the constant pool), down in the
BootstrapMethods_attribute.
The default Classfile traversal in VisitorBase will navigate from the
Instruction through the BootstrapMethod and visit both MethodRef_info
with IDs 39 and 35. #39 is the internal JVM machinery to create the callsite
and execute through it. #35 is the lambda. Because VisitorBase goes through
both, we end up with an extra dependency on
java.lang.invoke.LambdaMetafactory.metafactory() and a few other items in the
java.lang.invoke package.
Test
--> java.lang.Object *
--> java.lang.String *
--> java.lang.invoke.CallSite *
--> java.lang.invoke.LambdaMetafactory.metafactory(java.lang.invoke.MethodHandles$Lookup, java.lang.String, java.lang.invoke.MethodType, java.lang.invoke.MethodType, java.lang.invoke.MethodHandle, java.lang.invoke.MethodType) *
--> java.lang.invoke.MethodHandle *
--> java.lang.invoke.MethodHandles$Lookup *
--> java.lang.invoke.MethodType *
Test()
--> java.lang.Object.Object() *
lambda$someMethod$0(java.lang.String)
--> java.io.PrintStream *
--> java.io.PrintStream.println(java.lang.String) *
--> java.lang.String *
--> java.lang.System.out *
<-- Test.someMethod()
someMethod()
--> java.lang.String *
--> java.lang.invoke.CallSite *
--> java.lang.invoke.LambdaMetafactory.metafactory(java.lang.invoke.MethodHandles$Lookup, java.lang.String, java.lang.invoke.MethodType, java.lang.invoke.MethodType, java.lang.invoke.MethodHandle, java.lang.invoke.MethodType) *
--> java.lang.invoke.MethodHandle *
--> java.lang.invoke.MethodHandles$Lookup *
--> java.lang.invoke.MethodType *
--> Test.lambda$someMethod$0(java.lang.String)
I find it annoying that it pollutes the dependency graph with these
artifacts, but we can skip them with a judicious
-filter-excludes /^java.lang.invoke/, if you need to. Though, this will also
exclude some legitimate dependencies to that package if your code happens to
call into it.
I also refactored TestRegularExpressionParser to be data-driven tests.
November 08, 2023
Updated the official DTDs on the website to 1.3.0.
Refactored some code, mostly in com.jeantessier.dependency, to use more
modern Java. A lot of Stream API and using var where possible.
November 06, 2023
Now that I'm done with the work to bring the .class file parser up to the
latest specification, I'm ready to do a release. There were API changes that
broke backwards compatibility, but there were no major new features. If I
were to adhere strictly to semantic versioning, I
should go to 2.0. But, I'm hesitant to do this since there are no major
additions to Dependency Finder. I'm also uncomfortable just going to 1.2.1,
because it's more than just a bugfix and there are some large-ish changes in
the Classfile structure, after all. So, I've decided to go with 1.3.0.
I'm doing my development using Java 21, but I'm reluctant to release bytecode with major version 65. It all compiles and passes the tests with JDK 17. I will not force users to upgrade to the latest Java just yet, but I will not stay in the Java Dark Ages either. I'm using some recent language features, so I cannot really go back much further than Java 17.
November 02, 2023
Refactored some code to make better use of switch expressions. A long time
ago, I was a big fan of having a single exit point in methods. I would often
set up a result variable at the top of a method and have a single return
statement at the bottom. It helped with debugging because I could put a
print statement just before returning and see what was what. Since then, as
I've been working with other languages, I've become more prone to short methods
that simply return an expression. So, I'm making a few changes here and there
to make the code "look better".
November 01, 2023
Completed support for Java 17 by adding PermittedSubclasses_attribute, and
its helper classes processing in VisitorBase and XMLPrinter.
I also tackled rendering tableswitch and lookupswitch instructions. I
wanted to explore the "new" switch expressions in Java and I needed a way to
visualize the bytecode. I wanted to see if the various forms of switch
statements resulted in different bytecode. It appears that they do not, so
they are essentially syntactic sugar.
I added some helper methods to Instruction to help with combining bytes to
build values that are then used in the execution of the instruction.
October 31, 2023
Completed support for Java 16 by adding Record_attribute, and its helper
classes processing in VisitorBase and XMLPrinter.
October 30, 2023
Completed support for Java 11 by adding NestHost_attribute,
NestMembers_attribute, and their helper classes processing in
VisitorBase and XMLPrinter.
Also restyled the Release Plan page to improve readability. And also to make it easier for me to edit.
October 28, 2023
Completed support for Java 9 by adding ModulePackages_attribute,
ModuleMainClass_attribute, and their helper classes processing in
VisitorBase and XMLPrinter.
October 27, 2023
Added Module_attribute and its helper classes processing in VisitorBase and
XMLPrinter.
I made one change that is not backwards compatible: in =classfile elements, the
module element is now called is-module. This lets me repurpose module to
represent module references that are part of Module_attribute.
October 26, 2023
Started support for Java 9. Implemented Module_attribute and its helper
classes. It was straightforward, but tedious work.
October 25, 2023
Completed support for Java 8 by implementing MethodParameters_attribute and
its helper classes. I first drafted the changes that were required to support
Java 8 back in 2016. Now, I can say that part is done.
Java 9 defined modules. The Module attribute is a big attribute, but it is
very straightforward. Nests from Java 11 are trivial. Records were a big
addition in Java 16, but the Record attribute is a name with a descriptor and
an attribute lists. Easy stuff. The latest change to the .class file
format was in Java 17 with the addition of PermittedSubclasses attribute. It
aggregates together classes from the constant pool and will also be easy to
implement.
I noticed that the JVM specification uses the plural "access flags" but my code is using the singular "access flag". I changed it everywhere to use the plural. Strictly speaking, it breaks backwards compatibility, but I feel it's minor enough to slip it by.
October 24, 2023
Updated the classfile DTD to include elements for
RuntimeVisibleTypeAnnotations_attribute and
RuntimeInvisibleTypeAnnotations_attribute, along with their substructures.
October 23, 2023
Started support for Java 8. Implemented
RuntimeVisibleTypeAnnotations_attribute and
RuntimeInvisibleTypeAnnotations_attribute, along with their helper classes.
It turned out to be trickier than I expected. The TypeAnnotation is
especially gnarly, with lists of unions of bespoke micro-structures. I have
looked at many JAR files on my laptop in various Java-based tools and
libraries, but I still haven't found a class with either one of these
attributes.
I'm updating the DTD for classfile. It was missing many attributes
definitions.
October 22, 2023
Implemented the StackMapFrame parts, including a StackMapFrameFactory. I
did all the wiring for Visitable and Visitor support. I implemented
rendering as XML using XMLPrinter.
I adjusted the Release Plan to have separate items for each Java version that
introduced changes to the .class file format. I filled in dates for the work
I've just been doing. The remainder work for Java 8 through 21 should be
straightforward. (The last change was for Java 17.)
October 21, 2023
I used ClassMetrics to see which attributes I'm currently skipping in a given
codebase. I looked at Dependency Finder itself, a JAR file that was in my JDK
installation, and the JAR files for Groovy. StackMap is by far the most
common attribute being skipped at the moment.
I took another look at what I would need to support it. There are many
ancillary classes that will require interfaces in com.jeantessier.classreader
and implementations in com.jeantessier.classreader.impl. I looked at how I
had done it for ElementValue and I could see a way through if I skimped on
the testing for the more obvious wiring bits.
I implemented the VerificationTypeInfo parts. In doing this, I came upon a
way to test even the wiring with some judicious data-driven tests. I haven't
made them Visitable, yet. The total support for StackMap will add many,
many methods to Visitor and I will do them all at once.
Working on VerificationTypeInfo gave me a path through implementing
StackMapFrame next. The tagging for frames is different from what I've
encountered before. Previous tags were each discreet values. Specific
characters for ElementValue and specific integers for
VerificationTypeInfo. But StackMapFrame uses ranges. This is going to be
fun!
October 19, 2023
I'm going to skip the remainder of Java 5 support for now. Generic signatures
don't add enough information to what's already there to make it worth the
complexity of parsing their signatures. And the StackMap is just too crazy.
I will look for some lower-hanging fruits, first.
I implemented the BootstrapMethods_attribute structure and attendant helpers.
It took all day. I had a couple false starts and fell in a couple of traps,
but it worked out in the end.
October 18, 2023
Looked at what it would take to bring Dependency Finder support up to Java 21.
I have had an open feature to handle Java 5.0 additions to the .class file
format since 2007. The code to parse these additions is there, but I'm missing
the piece to interpret generic signatures. The specification for these
signatures is very complex and is mostly text processing.
Back on 2016-08-21, I had drafted the classes I would need to bring support
up to Java 8. There are a lot of new structures and those for the StackMap
element are particularly gnarly.
The additions for Java 9 through 21 seem fairly straightforward.
I took the opportunity to refactor many classes in
com.jeantessier.classreader.impl to deal make private fields final and use
the Stream API to traverse the Classfile structure. I managed to find a few
tricks to mock streams in visitor tests. For instance, I can mock stream()
to return a canned stream with Stream.of(). I can mock forEach() by
creating a side effect with CustomAction.
I removed some dead code, mostly "testing only" constructors that were not
being used. I noticed that I've been meaning to remove
ClassDependencyCollector and FeatureDependencyCollector since
2003-08-29!
The code coverage on the website dates back to 2010-11-29. It is woefully out of date.
October 16, 2023
Refactored the ClassCohesion CLI tool and wrote documentation for it on the
Tools page. At the moment, it is only accessible via the CLI. There is no Ant
task for it. Refactoring the various print...() helper functions was a nice
exercise in combining streams. Merging two streams was easy enough to do with
Stream.concat(). But merging a stream of XML text with opening and closing
tags was more tricky.
return Stream.of(
Stream.of("<tag>"),
getStreamForContents(contents),
Stream.of("</tag>")
)
.flatMap(Function.identity())
.collect(joining(System.getProperty("line.separator")));
I have to wrap the opening and closing tags in streams of a single value and
then use flatMap() to convert Stream<Stream<String>> to a
Stream<String>. The nice thing was building up streams of streams of
streams with a single joining() at the very top to collapse them back
together.
October 12, 2023
Refactored com.jeantessier.classreader.impl.Classreader to use
IntStream.range() instead of a for loop when reading parts of a .class
file.
The code used to look like this:
for (var i=0; i<attributeCount; i++) {
Logger.getLogger(getClass()).debug("Attribute " + i + ":");
attributes.add(attributeFactory.create(constantPool, this, in));
}
And now it looks like this:
IntStream.range(0, methodCount).forEach(i -> {
try {
Logger.getLogger(getClass()).debug("Method " + i + ":");
methods.add(new Method_info(this, in));
} catch (IOException e) {
throw new RuntimeException(e);
}
});
I think it looks "clever" and more modern, but I have to wrap exceptions
because the functional interface does not allow for checked exceptions such as
IOException. The try/catch block makes it a little ugly, and I am not
sure that the resulting code is really that much better.
October 11, 2023
Refactored com.jeantessier.text.Hex to use the Stream API and
java.util.Formatter to render bytes in text and XML outputs. All the
print() methods were used for single bytes, so I replaced them with calls to
Formatter instead. That left the toString() static method, which I
refactored to use streams to traverse the byte array and write to a String.
I used this opportunity to format the bytes with extra spaces that make the
output easier to read.
October 10, 2023
More tweaking of com.jeantessier.classreader.impl.Classfile to allow for
parallel streams.
I researched how to process byte arrays using streams. I drew inspiration from
this article
where they use java.nio.ByteBuffer.
October 09, 2023
Refactored com.jeantessier.classreader.impl.Classfile to use more modern Java
constructs, such as var local variables and using the Stream API.
September 20, 2023
Committed some changes that introduce some modern Java constructs, such as default methods in interfaces and some more use of the Stream API. I had been trying them out a while back but never got around to committing the changes. I have not applied the changes across the codebase, which is why I hadn't committed them.
I noticed the number of methods (M) measurement didn't have a constant in
BasicMeasurements. This is because it is a computed measurement instead of
being fundamentally derived from the .class file. MetricsGatherer creates
a submetrics for each method, and only for methods. So, we can compute the
number of methods in a class by counting these submetrics. If we ever decide
to have submetrics for things other than methods, we'd have to derive M from
the .class file, just like we do for the number attributes (A) and the
number of inner classes (IC).
March 05, 2023
Used XSLT to convert XML metrics to YAML format. It is also somewhat easier
than doing it in Java. But I'm toying with the idea of keeping both
implementations. There were some interesting uses of the Stream API in those
Printer subclasses. But I still need to fix how JSONPrinter deals with
commas in lists.
I re-wrote the JSONPrinter to capitalize on Collections.joining(). It
clones itself to render sub-parts. It will end up using more memory as it
writes sub-parts using java.io.StringWriter and only writes them out at the
very end.
February 28, 2023
Used XSLT to convert XML metrics to JSON format. It turns out to be much easier than doing it in Java.
February 27, 2023
Created YAML and JSON formats for OOMetrics. The JSON format is particularly
tricky because it uses commas as separators in lists, and the Visitor pattern I
am using doesn't know where it is in the list. How is it supposed to know not
to put a comma after the last element? The Stream API has a joining()
collector, but I will have to skip the Visitor pattern in the JSON
implementation if I want use it.
February 26, 2023
Found a bug in OOMetrics. Group-level basic measurements were not being
computed for defined groups, that is, groups that don't match a Java package
name, but rather a regular expression in a group-definition. The metrics
gatherer was only computing them for the group metrics of the current package.
It was never looking for matching defined groups.
I also moved the P measurement for packages from the top-level project to each
group, and used a SubMetricsAccumulatorMeasurement to aggregate them at the
project-level. Groups that represent individual packages will have a value of
1, but defined groups using regular expressions can cover multiple packages.
February 24, 2023
Using Stream API to simplify (and modernize) some of the logic in OOMetrics.
February 22, 2023
Came upon Jarviz after seeing a toot about it on Mastodon and an article on InfoQ. One interesting use case for Jarviz is finding the version of Java classfiles, so we can make sure dependencies are compatible.
I looked at adding something similar to OOMetrics. But the current metrics
are assumed to be numbers. And the set of metrics is fixed by the config,
instead of creating metrics based on the data, like versions "60" and "63".
I added class-level metrics for "major version" and "minor version". But I will need to do more work to aggregate them at the group- or project-level. I would like to build a histogram of different major versions in JAR files. And maybe go so far as listing out the classes by version number.
February 09, 2023
Removed the dependency on Guava. I wasn't really using it and some of the functionalities have equivalents in recent JDK versions. This makes one fewer external dependency to manage.
I could go one step further and replace Jakarta-ORO with java.util.regex. It
would allow me to get rid of MaximumCapacityPatternCache. But the
Jakarta-ORO API is so much simpler.
And if I were to replace Log4J with java.util.logging, I would have no
external dependencies at all. I like the Log4J API much more, though.
January 27, 2023
Added DependencyGraphToJSON and DependencyGraphToYAML. They use XSLT to
translate dependency graphs in XML to JSON and YAML formats respectively.
January 26, 2023
I'm playing with the idea adding JSON and YAML output formats, in addition to
text and XML. At first, I thought of simply adding new Printer subclasses.
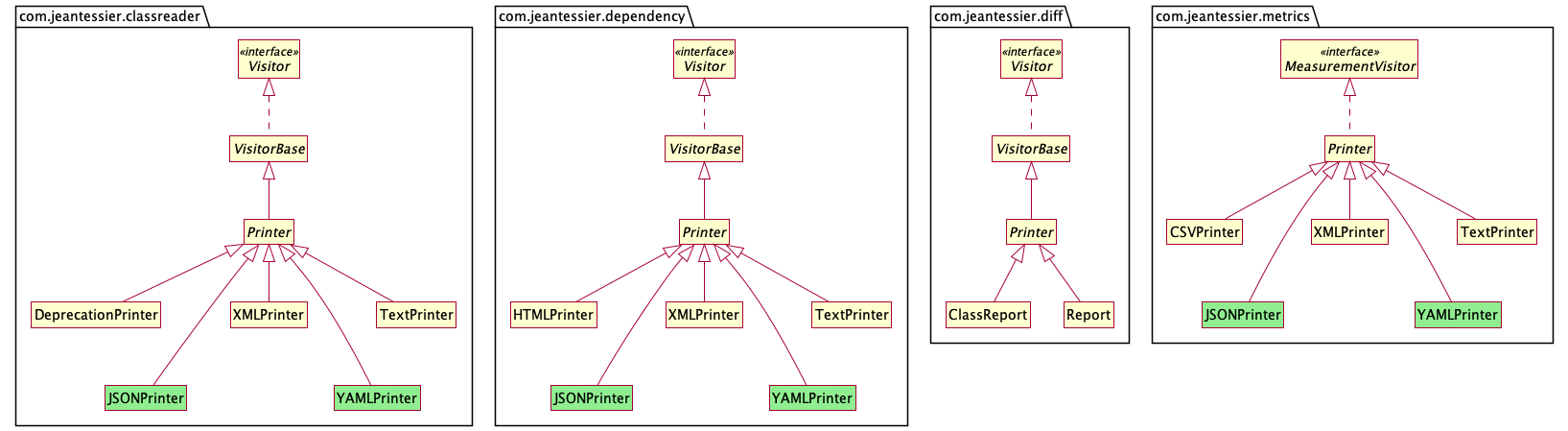
I started drafting what the outputs might look like for dependency graphs.
Then, I realized I might be able to pull it off using XSLT. It wouldn't be
much different from DependencyGraphToText.xsl. It already has logic to treat
inbound and outbound dependencies as separate collections, even though they are
a thrown together in a single collection in XML.
January 22, 2023
Added some support for Java 9 modules. I added the support for accessibility
and constant pool entries. I'm still missing the Module, ModulePackages,
and ModuleMainClass attributes.
January 21, 2023
Added tests for inner classes treatment in ListSymbols to improve code
coverage. And added switches to ListSymbols tools.
Released version 1.2.1-beta6.
January 18, 2023
Fixed instrumenting code for code coverage. When going from Java 1.7 to Java
1.8, the JVM became more strict when validating bytecode. The instrumented
bytecode is failing this stricter validation in Java 1.8. Passing the
-noverify JVM arg allows it to skip this verification and run the instrumented
code just the same.
- Emma: code coverage now works with Emma
2.0.5312. - Clover: Clover
1.3.13is still failing to create its coverage database. - Cobertura: Cobertura
1.9.3cannot handle try-with-resource code.
January 17, 2023
I tried to get some code coverage numbers for the changes I've been making to
ListSymbols, but all three ways that I know of, Emma, Cobertura, and Clover,
are broken at the moment. I don't know if it's the Java version, or the tool
versions, or what the latest recommended way to get code coverage in Java these
days.
January 16, 2023
Fixed how SymbolGatherer gets accessibility of inner classes. When visiting
classfiles, SymbolGatherer waits to see if there is an InnerClass structure
for it. If so, it passes this InnerClass structure to the Strategy to
determine whether to gather it or not. If there is no InnerClass structure,
then it uses the Classfile structure to make that determination.
January 15, 2023
Java specs
talk of accessibility. So, I renamed VisibilitySymbolGathererStrategy to
AccessibilitySymbolGathererStrategy.
January 13, 2023
Wrote VisibilitySymbolGathererStrategy to filter symbols based on their
visibility, as determined by access flags. I realized that top-level classes
can only be public or else package-visible, but inner classes use the full
range of visibility. ListSymbols does not look at inner class metadata, but
I will need to make it do so to properly filter inner classes.
January 12, 2023
A user asked for a way to limit ListSymbols to public and protected features.
There are a number of decorators for the SymbolGathererStrategy that
ListSymbols uses to filter symbols, but none of them match this specific
requirement.
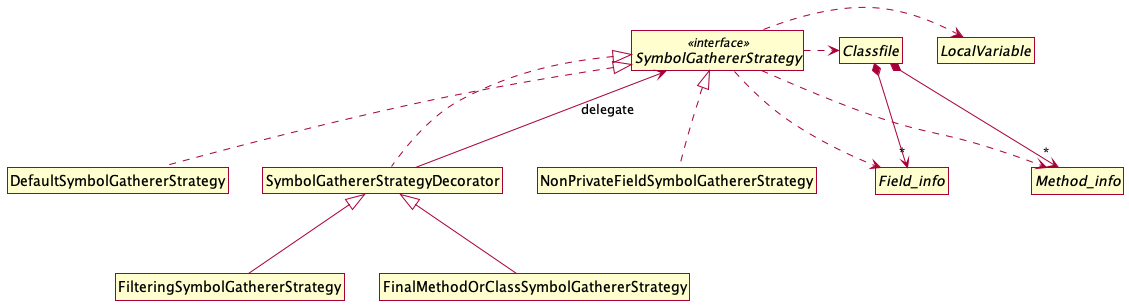
I would like to add a new decorator subclass that would filter based on visibility, but the test matrix is daunting. I looked a doing parameterized tests in JUnit, and found a way in JUnit5. I'm still on JUnit4. I will need to figure out the impact of an upgrade. I now wish I had a Gradle project setup so I could use Spock and write my tests in Groovy.
Maybe I can use Fit tests instead, to minimize the immediate impact.
August 02, 2022
I was reading an
article comparing Fernflower and Quiltflower
where they showed something in Java called
try-with-resources.
It's a way to write try blocks where you close a resource in the finally
clause. It's been in Java since Java 7. I switched all the places where I
would close a resource in a finally clause, usually reading files, and
replaced them with the try-with-resource pattern.
June 17, 2021
Fixed the calculation of median values for StatisticalMeasurement. I'd
always believed that the median value of a list had to be a member of that list.
When the list's size is odd, that's easy enough. But when the list size is
even, I would use the rightmost of the two middle elements. It turns out that
for lists of numbers, we're supposed to use
the average of the two middle numbers
instead.
January 29, 2021
I started Dependency Finder twenty years ago, today.
May 04, 2020
Created a Docker image to run Dependency Finder in a Tomcat container.
April 16, 2020
Somewhere between Java 5 in 2006(?) and Java 7 in 2013, the invokedynamic
instructions grew from 3 bytes to 5 bytes. The two extra bytes are nulled out
all the way through to Java 14.
I should do a pass through all instructions to see if any others have changed.
April 13, 2020
I noticed a new issue (#6). It shows a limitation of Dependency Extractor: it fails to capture dependencies on lambda expressions. Take the following example:
import java.util.function.*;
public class Test {
public void someMethod(){
Consumer<String> function = (x->System.out.println(x));
}
}
You would expect a dependency graph that includes the following:
Test
lambda$someMethod$0(java.lang.String)
<-- Test.someMethod()
someMethod()
--> Test.lambda$someMethod$0(java.lang.String)
The problem is that the reference to the lambda in the bytecode is through the
invokedynamic 0xBA instruction. This instruction allows the JVM to resolve a
method call at runtime. It relies on very intricate data structures and its
description in the
Java Virtual Machine Specification, Java SE 8 Edition,
took five entire pages. I don't know when I will find the time to work on this
very tricky piece of code. The latest
Java Virtual Machine Specification
is a little more concise, so maybe there is hope, yet. I'll have to take a look
at what else is new or changed.
April 09, 2020
Turned on HTTPS on SourceForge. This changed the URL from
http://depfind.sourceforge.net/ to https://depfind.sourceforge.io/.
SourceForge put some redirects in place, but I tried my best to change all
references nonetheless.
April 03, 2020
Fixed a cut'n'paste error in the dependencies DTD that had been going
unchecked since 2005-03-22.
April 01, 2020
Fixed the broken tests.
In one case, the compiler was optimizing away the unused variable c in the
sample test class. I figured a way to tweak the code so the compiler would
keep the variable by declaring it in an enclosing scope.
Tests for CodeDependencyCollector were testing filtering by excluding
/java.lang/ and making sure java.lang entities were absent from the
dependency graph. But after I added inheritance data to the graph, it became
impossible to avoid java.lang.Object since test derives from it. So I
switched the package to exclude to java.io instead. These tests were broken
since 2008-08-17.
I realized that when I ran tests with Ant instead of textjunit, some tests
were failing. I had to add JUnit classes to the CLASSPATH used by Ant's task.
Finally, all the tests for com.jeantessier.dependencyfinder.web are failing
because they use HttpUnit, which is broken. I've excluded these tests for the
time being, until I can find another way to test JSPs.
March 25, 2020
In Java 9, the com.sun.javadoc package was rewritten into the
jdk.javadoc.doclet
package. Some functionality was moved around and some of the classes changed
names. In Java 13, they finally removed the old, deprecated com.sun.javadoc
package. As a result, I will need to rewrite ListDocumentedElements.
March 24, 2020
Explored using Saxon for XSLT processing. I can
run a CLI tool straight out of the JAR file. I could add its JAR file to
Dependency Finder's lib/ folder and only change the XSL script templates to
refer to that JAR file only. One problem, though, is the command-line switches
to specify input and output files are different. (And not to my taste.)
$ DependencyGraphToHTML -in df.xml -out df.html
has become:
$ DependencyGraphToHTML -s:df.xml -o:df.html
I could have parsed the parameters inside the scripts and re-write in and
out switches on the fly. I could have done it for the UNIX shell scripts, but
I don't have access to a DOS machine to do the same for the Windows batch files.
Saxon's HTML output specifies a DOCTYPE. With any DOCTYPE, browsers are
more strict with the CSS stylesheet. Without a DOCTYPE, I can get away with
bare numbers when specifying margins. With a DOCTYPE, I have to provide a
unit. "50" has to become "50px" or else we lose all indentation in the HTML
output and it looks terrible. Fixing the CSS stylesheets to be more explicit
is easy enough and doesn't break anything.
March 23, 2020
Somewhere between Java 8 and Java 11, they removed
com.sun.org.apache.xalan.internal.xslt.Process from the JDK. This means that
I have to change XSLTProcess if I want to continue using XSL templates to
convert XML documents to HTML. I have over 45 tools that are based on XSL and
I am not looking forward to having to rewrite all of them.
March 15, 2020
Upgraded the following development components:
JUnit : 4.12 -> 4.13 Tomcat : 9.0.19 -> 9.0.31
I still have 78 failing tests. :-(
Many of the tools that I was using 10 years ago either don't exist anymore or have widely evolved in incompatible ways. Many of them can only download from Maven. My instructions for setting up a developer environment are pretty much obsolete. People have been asking for the ability to download Dependency Finder from Maven. And it would be nice to write tests in Spock (and write code in Groovy, for that matter). I have some thinking ahead of me.
August 09, 2019
Upgraded the following development components:
JDK : 1.8.0_172 -> 1.8.0_181
April 17, 2019
I found a large number of files that were in DOS format, with \r\n as line
terminators. I fixed them all to be in UNIX \n format, instead.
March 28, 2019
A user pointed out a problem analyzing some JAXB files. Once again, the files
contain new constant pool entries for Java 9. They proposed a patch to ignore
a specific filename, but I think it's better to catch the Exception, log it, and
continue extracting the class information. Now, there is a small risk that
.class files will be skipped "silently". Users could find out by scrutinizing
the output with -verbose, or with clever Log4J settings, but it's more likely
they won't realize they only have partial data.
I will need to update the com.jeantessier.classreader package to the latest
bytecode.
May 14, 2018
Upgraded the following development components:
JDK : 1.5.0_04 (?) -> 1.8.0_172 Ant : 1.9.7 -> 1.10.1
I don't know when it started, but the default Ant target no longer works. These three invocation all do the same thing:
ant
ant all
ant distclean dist
Both distclean and dist depend on the init target, which sets a bunch of
variables and creates output folders. But `distclean` deletes these output
folders so they no longer exist by the time `dist` runs.
I tried to generate a new release, 1.2.1-beta5. However, I am now using Java
8 and it generates .class files that older versions of Java will not be able
to execute. I wonder if that wil be a problem.
The instructions for generating a build need some updating.
April 27, 2017
Aborting efforts to convert to Grails. For the time being.
Grails 3.2.9 just came out and this project is still on Grails 1.3.7! There is
no obvious upgrade path for Grails apps out of 1.x. And I never really got
around to do anything substantive. So, I am giving up and deleting the grails
branch. I'd have to start over anyway, and there isn't much to salvage.
August 21, 2016
I've been looking at what's needed to bring the com.jeantessier.classreader
package up to date with the latest JVM spec for Java 8. I already took care of
the new constant pool elements, but there are new attributes too. And those are
not trivial.
Here is the class structure that supports Java 4. The constant pool is in blue and the various attributes are in yellow.
And here is the class structure needed for Java 8. The new elements are in green.
Bear in mind, these are only the public interfaces in
com.jeantessier.classreader that will be visible to other callers. There will
also be implementation classes in com.jeantessier.classreader.impl and
additional support classes, like factories for the Target, StackMapFrame,
and VerificationType_info hierarchies. It will also impact implementation of
the Visitor interface.
August 10, 2016
A user pointed out to me that they were not able to analyse some Lucene files.
I determined that the files contained new constant pool entries for Java 7/8 and
quickly added support for them in the com.jeantessier.classreader package.
This way, we can at the very least parse the files. The support is very
barebone for now, only printing them out in logs and as part of ClassReader.
After reading about it, I think there are also new attributes that I'll have to
look into.
I realized that the installation instructions still reference Sun Microsystems. I should update them to point to Oracle instead.
July 20, 2016
Aborting efforts to convert to Struts.
July 19, 2016
Figured out how to let Gradle know where to find the classes for Javadoc Doclets
with the following dependency in build.gradle:
compile files(org.gradle.internal.jvm.Jvm.current().toolsJar)
It adds tools.jar to the compiler's classpath. It which contains the
com.sun.* classes used by the Doclet code.
July 18, 2016
Ripped out WebWork. It was a great framework years ago, but there are better alternatives, now.
July 17, 2016
Upgraded the following development components:
Ant : 1.9.4 -> 1.9.7 Guava : r09 -> 19.0 JUnit : 4.8.2 -> 4.12 Log4J : 1.2.15 -> 1.2.17
July 15, 2016
Played with replacing the Ant build script with
Gradle. It has a number of pre-defined tasks to deal
with Java project. It also expects a certain code organization that echoes what
I have seen on other projects. Source code is under src/main/java and unit
tests are under src/tests/java. It is possible to change these defaults to
match legacy projects, but I'm more tempted to move files around to match these
growing best practices.
I can declare dependencies in build.gradle and Gradle will download them
automatically. Such as:
compile "log4j:log4j:1.2.17"
compile "oro:oro:2.0.8"
compile "com.google.guava:guava:r08"
I can also include dependencies for WebWork and such.
I need to find better examples on how to deal with launch scripts and web applications.
April 01, 2016
Here is the most recent link to the JVM specification and the production rules for signatures.
March 31, 2016
Someone emailed me a question about dependencies on types in declarations for generics.
Here is an example:
import java.util.*;
public class SomeClass {
private Set<OtherClass> property = new LinkedHashSet<OtherClass>();
}
And its dependency graph:
Main
--> java.lang.Object *
Main()
--> java.lang.Object.Object() *
--> java.util.LinkedHashSet.LinkedHashSet() *
--> java.util.Set *
--> Main.property
property
--> java.util.Set *
<-- Main.Main()
No mention of OtherClass whatsoever.
This is because the Java compiler applies
type erasure
to generics. It stores the original signature in Signature_attribute
attributes attached to the class, field, and/or method that had a generic
declaration. At this time, CodeDependencyCollector ignores the contents of
these attributes. Their production rules are very complex, given the wide
variety of generic declarations.
For instance, the signature for SomeClass.property above is:
Ljava/util/Set<LOtherClass;>;
In parsing it, we have to detect the inner L...; sequence before we can
process the outer one. And this is a trivial case. Method declarations and
wildcards introduce other levels of complexity that only compound each other.
I looked a little into it back on 2009-06-04, but haven't made any progress since, I'm afraid.
January 22, 2016
I found out some of my code samples in the Developer Guide got mangled by the
pseudo-wiki generator. Whenever a code sample had a == check, the
generator took it to mean an empty <code> tag. I fixed it to leave
these alone.
A podcast mentioned GitBook for publishing books. I could move the guides there, provided I rewrite them using Markdown.
October 03, 2015
Moved the project hosting to GitHub.
I can use GitHub Pages to host the project's website, so I moved the older
website folder to the gh-pages branch and moved everything in the older
DependencyFinder folder up one level. GitHub Pages cannot run CGI scripts, so
I will have to find an alternative for the Journal.
I will also need to change references to SourceForge from the pages and fix deployment instructions.
January 30, 2014
Fixed the problem that prevented me from compiling Dependency Finder. A test class was embedding an irregular
character "¥" saved directly in the source Java code. The compiler decided that it was going to choke on it from
now on. So I changed it for the escape sequence \u00A5 instead and it worked just fine.
There are still 77 broken tests. I vaguely remember that some were broken when I last ran them (years ago). But 77! Many of them relate to a missing Tomcat class, so it's probably because have shifted in Tomcat 7.0.14. If only there was a tool to help me locate a class in folders with a bunch a JAR files in them. :-)
November 25, 2013
Fixed the problem with Perl. I was using an older syntax to load the "getopt" module to parse command-line switches. I updated to a newer syntax and now it's loading just fine.
November 24, 2013
I tried to upgrade from Grails 1.3.7 to the latest, 2.3.3. It proved to be more than I could handle straight out of the box. There have been many many profound changes in Grails since version 1.3.7 and I might have to start from scratch. Lucky for me I haven't had time to get very far in my Grails integration.
On a sadder note, I haven't really kept up with my environment and I realized that I can no longer compile Dependency Finder. Somewhere between computer upgrades and OS upgrades, Perl and Java have changed and my code no longer works. I will have to find the time somewhere to figure out what's changed and fix it.
March 07, 2013
Someone asked for an example of using OOMetrics, such as a constructor that scans an entire folder and a simple getter
that returns all metrics for a given class. OOMetrics is highly configurable and slices and dices the data many
different ways. This usecase is very simple and setting things up for it is a little involved.
Here's the code:
import java.util.*;
import com.jeantessier.classreader.*;
import com.jeantessier.metrics.*;
class OOMetrics {
/**
* names the file that describes which metrics to compute.
*/
public static String METRICS_CONFIG_FILE = "config.xml";
/**
* holds the metrics definitions and collected data.
*/
private MetricsFactory metricsFactory;
/**
* reads the metrics descriptions from the config file and
* collects metrics on all the .class files on paths.
*/
public OOMetrics(Collection<String> paths) throws Exception {
// Setup the MetricsFactory which will hold all the metrics.
MetricsConfiguration metricsConfiguration = new MetricsConfigurationLoader().load(METRICS_CONFIG_FILE);
metricsFactory = new MetricsFactory("OOMetrics", metricsConfiguration);
com.jeantessier.metrics.MetricsGatherer gatherer = new com.jeantessier.metrics.MetricsGatherer(metricsFactory);
// Read in all the classes to analyze
ClassfileLoader classfileLoader = new AggregatingClassfileLoader();
classfileLoader.load(paths);
// Collect metrics on all the classes.
gatherer.visitClassfiles(classfileLoader.getAllClassfiles());
}
/**
* converts the internal metrics data to name-value pairs.
*/
public Map<String, Number> getMetrics(String className) {
Map<String, Number> results = new TreeMap<String, Number>();
Metrics metrics = metricsFactory.createClassMetrics(className);
for (String measurementName : metrics.getMeasurementNames()) {
results.put(measurementName, metrics.getMeasurement(measurementName).getValue());
}
return results;
}
}
The constructor reads the configuration from an external file because hard-coding a configuration would have been very
complex. It is using an AggregatingClassfileLoader because it is more versatile even though it uses a lot more memory
to hold all the classes at the same time.
The getter reduces the measurements to simple numbers. It could return the whole Measurement object and let the
caller sort it out. The traversal is a little awkward because Metrics is meant to be traversed using the visitor
pattern instead of through the programmatic API. It ends up with the measurements' short names, which can be a little
cryptic. An alternative that shows the longer names would look like this:
Measurement measurement = metrics.getMeasurement(measurementName);
results.put(measurement.getLongName() + " (" + measurement.getShortName() + ")", measurement.getValue());
I don't know the full context in which they want to use these metrics, but it may be simpler to use OOMetrics as is,
either from the CLI or through Ant, and then parse the output file.
OOMetrics -classes -xml -out metrics.xml dist/classes/
There is good support for parsing XML in most languages and application frameworks. You'd use it to read the output from the tool and convert it to a lookup table and use XPath expressions to narrow in on the classes you want.
January 29, 2013
Dependency Finder is now 12 years old.
August 07, 2012
Found a Grails plugin, Standalone App Runner, that packages the webapp in a JAR file with a choice of Tomcat or Jetty, so you can run the app simply by executing the JAR file. I was considering a distribution with Jetty a while back and this would be a really easy way to do it. All I have to do is rewrite the webapp as a Grails app.
January 29, 2012
Dependency Finder is now 11 years old.
January 12, 2012
Fixed calls to <javac> in the various build.xml files to include the
includeantruntime attribute needed by Ant 1.8.
This is stupid. For the sake of preserving some old build.xml files, they
polluted all future build.xml files. They could have made it a command-line
switch on Ant itself so old projects could fix it without corrupting all of our
projects.
January 08, 2012
Added -excludes-list to ListSymbols, complete with tests. After two years
in Groovy, Java code feels so different.
January 06, 2012
Someone asked about listing methods in a code JAR file that are not called from a separate test JAR file. They put their code in one JAR file and their tests in another one, and they want to use Dependency Finder to find what methods are not called directly from the tests.
I figured out a way by listing symbols and using them in an exclusion list, but
ListSymbols does not have that switch. Adding it is not too complicated, but
there are quite a few tests to adapt. I have to immerse myself in that code
again. It's been a while.
November 17, 2011
Someone opened a bug about reporting line numbers as part of dependency graphs, bug 3438741. Their arguments are that 1) why not use it when it's there and 2) other tools can pinpoint statements, so why can't Dependency Finder?
So I tried to clarify my reasons in the user's manual. I'm fairly limited by relying only on compiled code and the information that's there. Line number information, when available, is only for methods and not for fields or classes. Implicit return statements and constructors can throw off line number information, making it harder to really trust them. Other tools, aside from exception stacktraces, typically work off of the source code and build their own parse tree, giving them access to the entire code.
I have been tempted for some time to gather information per dependency, such as
the number of times a given dependency is repeated, or possibly what line number
it occurs on. But for that, I would need an new object to model the dependency,
and that would augment the memory footprint. Right now, dependencies are just
Node references in Map instances, keeping things small. But my merging
together all copies of a dependency, it becomes impossible to report specifics.
November 11, 2011
Upgraded the following development components:
Ant : 1.7.0 -> 1.8.2
May 19, 2011
Tried to upgrade to Tomcat 7, but HttpUnit is having problem creating the
ServletContext needed to run the tests. I cannot find information on this
problem online, so I'm going to wait a little.
May 18, 2011
Upgraded the following development components:
Guava : r08 -> r09
March 09, 2011
Tried to convert extract.jsp to a Grails GSP. All the scriptlets are really
getting in the way. And the same problem I had with WebWork is surfacing again:
extract.jsp streams its progress directly to the browser and I haven't quite
found how to do this in these frameworks. Maybe a taglib can help.
March 07, 2011
Upgraded the following development components:
Grails : 1.3.6 -> 1.3.7
February 06, 2011
Copied changes to ClassMetrics CLI to the corresponding Ant task. Also
updated the documentation for both of them.
February 03, 2011
Finished including annotations being used when compiling class metrics. I used
some features of the Guava library to convert a set of Annotation instances to
their type string and remove duplicates. It let me write the transformation in
a more functional way, but Java is so very verbose compared to Groovy.
Here is the code in Java:
Iterable<String> annotationTypes = Sets.newTreeSet(Collections2.transform(metrics.getUsedAnnotations(), new Function<Annotation, String>() {
public String apply(Annotation annotation) {
return annotation.getType();
}
}));
And the equivalent in Groovy:
def annotationTypes = metrics.usedAnnotations.collect*.type as SortedSet
The nice thing with Groovy is that since it's a JVM language, I can just put
DependencyFinder.jar on my CLASSPATH and run that line in some Groovy code.
Upgraded the following development components:
Guava : r06 -> r08
February 02, 2011
Working on a unit tests to check that MetricsGatherer also accumulates
annotations that are being used by the code under examination.
January 29, 2011
Dependency Finder turns 10 years old.
January 13, 2011
Wrote unit tests for MetricsGatherer's handling of runtime annotations when
compiling class metrics.
January 01, 2011
Trying to write unit tests for Field_info so I can tackle
bug 1766486.
Because I decided, a long time ago, to create everything from data streams in
constructors and strictly mirroring the data structure from the classfile
specification, I end up having to mock a lot of things to setup a test for a
field with a string value. There are times when you question some of the
earliest design decisions.
December 31, 2010
Minor tweaks to text docs.
Started working on bug 1766486 about escaping special characters when rendering classes as XML.
December 30, 2010
Upgraded the following development components:
Grails : 1.3.3 -> 1.3.6
December 29, 2010
Fixed the bug with EnclosingMethod_attribute when the enclosing method is a
constructor. I took this opportunity to write some tests for generating XML for
EnclosingMethod_attribute.
December 28, 2010
Researched the bug with EnclosingMethod_attribute when the enclosing method is
a constructor. It turns out that when the enclosing method is a static
initializer, the EnclosingMethod structure does not have a method reference.
December 27, 2010
A user reported a bug with EnclosingMethod_attribute when the enclosing method
is a constructor. When producing XML output from ClassReader, they sometimes
get the string "<init>" in some of the text, which XML parsers think is a
start tag and that the overall XML document is not well-formed. I suspect this
is because an anonymous inner class is declared inside a constructor, since the
bytecode calls all constructors "<init>". I also suspect that anonymous
inner classes declared inside a static initializer might produce an
EnclosingMethod structure with a method name of "<clinit>".
December 09, 2010
Upgraded the following development components:
IntelliJ IDEA : 9.0.4 CE -> 10.0 CE
November 29, 2010
Updated the code coverage reports for release 1.2.1 beta4.
November 28, 2010
Figured out the problem with the ArrayIndexOutOfBoundsException on wide
instructions. There are helper methods inside the Instruction class to fetch
individual bytes from the bytecode. They all take offsets from the
instruction's start position in the bytecode. One branch of a case statement
was adding the instruction's start position to the offset before calling the
helper, resulting in a fetch at twice the start position. If the instruction
was past the half-way park, it resulted in ArrayIndexOutOfBoundsException.
Found another problem with escaping text in XML documents from ClassReader.
It is possible for some string constants in the bytecode to contains characters
that are not strictly UTF-8. I had to brush up on my XML to fix this one. I
found a promising library in Commons Lang from the Apache Project, but it did
not handle low value control characters that are below the range of normal
visible characters. So I had to rework
com.jeantessier.classreader.XMLPrinter.escapeXMLCharacters() myself. I don't
think I'll have the same problem with the other XML generators because they
don't deal with the raw constant strings in Java the way ClassReader does.
Released version 1.2.1 beta4.
November 26, 2010
Received the class that was breaking Dependency Finder back on 2010-10-23.
ClassReader chokes on it but javap is fine. Today's a holiday and I'm busy
with visitors from out of town, so it'll have to wait a little.
November 18, 2010
Found a back link for apache.com that should have been apache.org instead.
November 12, 2010
Upgraded the following development components:
IntelliJ IDEA : 9.0.3 CE -> 9.0.4 CE
November 01, 2010
Back on 2010-08-29, I switched from google-collect to
Guava. Then, on 2010-09-08, I
removed the now obsolete google-collect.jar file but I forgot to update the
scripts that lists JAR files explicitly. That's now fixed.
October 23, 2010
Someone is getting ArrayIndexOutOfBoundsException when Dependency Finder
encounters a wide instruction (opcode 0xCA). If they can send me the class
that causes the problem, I might be able to figure where the problem lies.
October 18, 2010
Someone was asking for help with the dependencyextractor And task, and I
noticed that the documentation contained a typo. It mentioned a task attribute
named filter-excludes but the task has a setter for setFilterexcludes()
instead. So where would the dash in the XML attribute come from? I read the
documentation and confirmed that Ant is case-insensitive when it comes to task
attributes, but it does not add or remove dashes. So the sample code in the
documentation does not work. Oops. All fixed now.
September 08, 2010
Moved the Google Analytics tracking code from the old Urchin-based to their new Asynchronous Snippet. Quite frankly, nobody should notice the difference.
I had to cut and paste the snippet to many files. That was annoying, so I
extracted it to a separate .js so I could copy a single line script inclusion
instead. Then, I realized that defeated the purpose of Google's Asynchronous
Snippet, whose purpose is to not delay the loading of the page by including
other scripts synchronously. So I'm back to cut and pasting "large" snippets.
August 29, 2010
Upgraded the following development components:
Tomcat : 6.0.10 -> 6.0.29 google-collect : 1.0-rc2 -> none Guava : none -> r06
August 28, 2010
It turns out Guava, strictly speaking, also depends on JSR 305. But I am still able to compile Dependency Finder without it and run the tests.
August 27, 2010
While looking for the latest version of Google Collections, I found out it was now something called Guava. I might consider switching.
August 25, 2010
Upgraded the following development components:
JUnit : 4.7 -> 4.8.2
I also ran JarJarDiff on various versions of JUnit from 3.8.2 to 4.8.2. I
added the results to the Samples page for JUnit.
August 19, 2010
Looked at AddThis as a possible mechanism for coworkers to share interesting Dependency Finder results on the webapp. The default AddThis email button puts the URL in the email message. The URL is enough to recreate the query and see the results. I need to explore further if I can add the query's results to the message.
August 12, 2010
A user asked for clarifications on the behavior of the advanced view in the GUI. From the layout of the interface, in appears the checkboxes govern the use of regular expressions for packages, classes, and features. But they don't. You can think of it as a two-step process:
- Select nodes based on all the regular expressions.
- Summarize the selected nodes based on the checkboxes.
GraphSummarizer does both steps at the same time, but conceptually, this is
what is happening.
I never claimed the UI was very intuitive. There is definitely room for improvement.
July 24, 2010
At ShopWell, we do a lot of design using post-it stickies on foam boards. We have many, many very large foam boards, to the order of 100"x60". We can stand at the foam board and have a hallway chat about things. We can more stickies around and group them and shift things around. We can easily more boards from one room to the next as needed.
On Dependency Finder, I'm a little overwhelmed by all the tasks I've identified and written up over time, in so many places: the Release Plan, Pivotal Tracker, 5"x7" cards, notes, etc. So I figured that if I could get them all on one foam board, where I could see them all and easily manipulate them, it might get me going again. I went out, bought myself a board (a more modest 36"x24"), some stickies, and a bunch of sharpies, and I'll get started running my own board for Dependency Finder.
July 22, 2010
Upgraded the following development components:
Grails : 1.2.2 -> 1.3.3
July 20, 2010
Upgraded the following development components:
IntelliJ IDEA : 9.0.2 CE -> 9.0.3 CE
May 11, 2010
Pushed the grails branch back to the Git origin repository on SourceForge. I
had to dig out the commands, since it had been a while. Roughly, it looked like
this:
git checkout -b grails- ... a bunch of commits ...
git push origin grailsgit checkout mastergit branch -D grailsgit branch grails origin/grailsgit checkout grails
I created the branch locally at first and made some commits to it. I then pushed it to the remote repository. I wanted to change my setup so my local branch would track against the remote branch, so I had to delete the local branch before I could create the mapping I wanted. I have to admit I found this part was a little scary. But it worked just fine.
May 06, 2010
I got an email today from a user who found a bug in Dependency Finder. It turns
out that I implemented the null check in Classfile.isInnerClass() in the wrong
direction. I looked for usages of this method but found none. Not even a test.
The shame.
I also discovered a 2 year old bug report about the access flags for inner classes. Given these classes:
public class Outer {
private class Inner {}
}
The bytecode for Outer has an access flag of 00000000 00100001: ACC_PUBLIC
and ACC_SUPER. The bytecode for Inner has an access flag of
00000000 00100000: only ACC_SUPER because it is not a public class. The
.class file format does not provide for other class-level visibility levels.
The modifiers of the inner class are covered in the InnerClass part of
InnerClasses_attribute. The bytecode for both Outer and Inner include
identical copies of InnerClass with an access flag of 00000000 00000010:
ACC_PRIVATE.
The bug report was trying to copy the InnerClass access flag to the
Classfile instance. This will not work because the meaning of each bit is
different between the two classes. The interfaces in
com.jeantessier.classreader are meant to provide an accurate representation of
the information in the bytecode. It is meant for people who think in terms of
the bytecode, not people who think in terms of the Java language. There is a
subtle difference. If you're dealing with an inner class, you have to get its
access level from the enclosed InnerClasses attribute.
To work on this problem, I fired up a grails shell in a Grails application
where I had copied DependencyFinder.jar. It was really cool to simply use
scripting to manipulate data. Java has so much boilerplate code when compared
to Groovy.
I fixed the link to JSR 202 on the Resources page. The latest .class file
specification includes full description of the StackMap element. At last.
April 28, 2010
Grails already includes JAR files for
Log4J 1.2.15 and
Jakarta ORO 2.0.8, the same versions that
Dependency Finder uses. As an experiment, I created an empty Grails project and
copied only DependencyFinder.jar to its lib/ directory. I then started
grails shell and I was able to run the same operations as
DependencyExtractor by hand. No big surprise there, but it was cool.
I want to redo the webapp as a Grails application. I'm struggling with file
system issues, though. Should I create a directory under the current tree where
I would put the new app, next to web/ and webwork/? That would be
consistent, but the new app would get a name from that directory, which would
most likely be called grails. An alternative is to start a brand new tree
somewhere else, completely dissociated from the current Dependency Finder
development tree. There, the application can be called DependencyFinder or
some such. But I would have to start a new Git repository for it. In either
case, I'll have to be creative to manage DependencyFinder.jar as it evolves.
April 23, 2010
Upgraded the following development components:
IntelliJ IDEA : 9.0.1 CE -> 9.0.2 CE
April 17, 2010
My license for IntelliJ IDEA is about to expire. I haven't been able to work on Dependency Finder since I started working at ShopWell, so I don't know if they'll consider the project active enough to deserve a free license still. But JetBrains has a community edition that is free and does everything I need, so it is not a complete loss. I installed it tonight to try it out.
Upgraded the following development components:
IntelliJ IDEA : 9.0 -> 9.0.1 CE
January 26, 2010
A user was having difficulty accessing the DTDs. After investigating, I
realized SourceForge disabled automatic directory listings ... in 2008. They
left instructions on how to re-enable it, so I added .htaccess in the dtd/
folder to take care of it.
December 17, 2009
Tried to use Dependency Finder to analyze some Groovy code. But the way that Groovy mediates method calls so it can treat getters like properties makes it difficult (impossible?) for Dependency Finder to see the real dependency. Instead, it sees dependencies to Groovy's internal method resolution code.
I installed the latest version of
yEd only to find out
its XML parser cannot read the GraphML files I generate with
DependencyGraphToyEd. Something to do with forward references. I guess I'll
have to rewrite it to process write out all nodes before it writes edges.
November 19, 2009
I've been setting up another development on a new laptop. I couldn't find the
version of FitLibrary that I'm
using with Dependency Finder. I'm using FitLibraryRunner20060116, but the
oldest version available is FitLibraryRunner20070217. There were some API
changes, starting with this version, that are incompatible with my code and I
have not found a workaround. I am going to have to include my copy of the
2006-01-16 version with the source for Dependency Finder if people want to run
the Fit tests.
November 07, 2009
I'm thinking of replacing the web app with a Grails app instead.
October 09, 2009
Found some useful instructions on tying Git and SVN at the
online documentation for Git
for the
git-svn
command.
October 08, 2009
Fixed the WebWork-based web app, somewhat. It turns out that if I want to use Spring IoC, I need to add a few JAR files to the application and an empty Spring config. But maybe I just don't need Spring IoC.
Now, the web app starts, but nothing happens when I try to run extract.action.
I know the right method gets called because start and stop get assigned, but
ExtractAction does not look at the resources listed in source.
I tried to update the SVN repo first, in the hopes of copying the change to Git afterwards. This is probably a bad idea if I don't have access to the original Git client where I first fetched the SVN repo.
October 06, 2009
Converted the Subversion repository to Git, hosted on SourceForge. I'll try to keep them in sync for a while, but I might eventually switch only to Git and cancel the SVN repo, just like I did for CVS a while back.
October 01, 2009
Added sample data files for 1.2.1 beta releases.
Added build.cobertura.xml for computing code coverage using
Cobertura.
September 30, 2009
Worked on backlog of data files from 1.2.1 beta releases.
September 27, 2009
Released version 1.2.1 beta3.
Updated the release instructions.
September 23, 2009
Added missing flag values on Classfile parts when rendered in XML. I also
added comprehensive tests for all flag values.
ClassfilesyntheticannotationenumFieldenumMethodbridgevarargsInnerClassannotationenum
Updated the DTD too.
September 21, 2009
Found a bug with the latest release. When I added Google Collections, I forgot to update some of the Unix launch scripts. I'll probably cut a new release with the fixed scripts.
September 17, 2009
Upgraded the following development components:
HttpUnit : 1.6.2 -> 1.7
Added the output of JarJarDiff on
HttpUnit to the Samples page.
September 16, 2009
Going through the Groovy tutorial. It is a
nice scripting language, a cool extension of Java. You can name closure
parameters, just like Ruby, but it also has a default it if the closure needs
only one parameter. I was able to compile to bytecode, using groovyc, and run
Dependency Finder on it. But the code it generates is very hard to read, so
don't try it. Generated code is meant to stay hidden.
Speaking of generated code, I saw a presentation on IxEdit, a tool to generate JavaScript to tie controls on a page. While it is very slick for generating interactions, it generates code that you then cut and paste into the HTML page. I'm pretty sure this is not maintainable. The generated JavaScript is fairly opaque. The demo didn't cover how or if you could re-insert the code in the editor to refine interactions.
September 14, 2009
A friend mentioned the Groovy language. It is a scripting language built on top of Java. It compiles to bytecode and runs on the JVM, so I might be able to run Dependency Finder on it and see what comes out. :-)
Videos on Groovy:
The Groovy site mentions Cobertura to do code coverage. Its sample output looks nicer than what I'm using right now: Clover and Emma. I'll try to run it over Dependency Finder when I have a moment.
September 11, 2009
Released version 1.2.1 beta2.
The distribution file management has changed a lot since the last release. I need to update the release instructions. See release instructions on SourceForge in the meantime.
September 09, 2009
Pushed the logic for separating fully qualified class names into package name
and simple class name to the Class_info class, with tests. Added tests for
Classfile.locateField() and Classfile.locateMethod(), including proper
handling of inherited package-visible methods.
Added LoadAdapter, a no-op implementation of LoadListener, so
implementations don't have to duplicate no-op methods just to fulfill the
interface.
Started Google Collections in spite of my reservations regarding JSR 305. Next, I want to start using Guice too.
September 04, 2009
Added JarJarDiff output for EasyMock and its class extension.
August 31, 2009
I'm still debating whether interactions between visitors should use double
dispatch or not. Double dispatch is useful when you don't know the exact type
of the element being visited, so you cannot know which visit() method to use.
But when the decorating visitor is ready to dispatch to the decorated visitor,
it knows the concrete type of the visited element, so there is no need for
double dispatch. I'm still tempted to keep using double dispatch nonetheless,
since it is the normal mechanism for passing control to a visitor and it makes
the interactions with the decorated visitor seem more natural.
I have produced an alternate sequence diagram that shows the flow of control between three visitors composed visitor to render a dependency graph as text.

I also produced a matching version of the dependency graph for rendering a dependency closure as a call graph.
I really like sdedit for creating sequence diagrams.
August 28, 2009
Tried to used
Google Collections in
Classfile. I was hoping that Iterables.find() would simplify methods like
getField() and getMethod(), even with the added boilerplate for the
anonymous inner class for the Predicate. But find() throws an exception
if it doesn't find a match whereas my code has been returning null. Once I
throw in the exception handling, the methods is much harder to read than the
simple for() loop I had before.
Google Collections uses the @Nullable annotation from
JSR 305. But the project doesn't have
any binaries, so I had to steal the JAR file from the
FindBugs project. It doesn't feel as
clean as I would want it. Maybe I need to let Google Collections to bake for a
little while longer.
August 27, 2009
Refactored Classfile to rework locateField() and locateMethod(). I now
have a special constructor to allow testing. I marked it with a comment while I
decide whether or not I want to pull
Google Collections into the
project so I can use its @VisibleForTesting annotation.
August 22, 2009
Finished a possible test for Classfile, using a test-only constructor. I
marked it @Deprecated until I figure out how I want to introduce the Google
Collections API.
I should rewrite Classfile.locateField() so it is similar to
Classfile.locateMethod(). For consistency.
August 19, 2009
Looked at how I'm using MaximumCapacityPatternCache and how its capacity()
method returns a hard-coded 20. This capacity serves to seed the expression
cache in ORO's Perl5Util. I'm thinking that most of the time, 20 is overkill.
And when I need more than 20, I need a lot more than 20. So it's never quite
the right number, but I cannot refine it without lots of experimentation. At
least, ORO's GenericCache.DEFAULT_CAPACITY is also 20, so somebody thinks
it's a sensible value. Maybe I should reference it instead of hard-coding a
mysterious 20.
August 18, 2009
Changed dependencies on java.io.DataInputStream to java.io.DataInput
instead.
Looked at Classfile.locateMethod() and I found something that seemed strange at
first glance: it will return a method defined on the class regardless of its
access privilege, but will only return one that is inherited if it is public or
protected. This makes sense, since otherwise it would not be inherited. But it
is missing the case of a package-level method from a superclass or interface in
the same package. The expected behavior is not documented and there are no
tests to tell me what I had in mind when I first wrote it. So I tried to write
a test for it, but the constructor for Classfile does way too much work. It
reads a lot of data from the DataInput, including the constant pool and
interfaces and fields and methods and attributes. Specifying all of these in a
test is too brittle, I'd much rather supply mocks for all these collaborators.
If I used the
Google Collections, I could
have a special constructor and mark it @VisibleForTesting.
August 17, 2009
Tweaked tests to use is() matcher with assertThat() consistently.
August 14, 2009
Refactored com.jeantessier.metrics.TestMetricsGatherer so it uses mostly the
new assertThat() syntax from JUnit 4.5 instead of the various assertTrue()
and assertEquals() and so forth. I was able to simplify the tests drastically
with judicious uses of helper methods and Hamcrest's hasItems() matcher.
It is still more an integration test than a pure unit test. It is somewhat
brittle since it depends on an actual compiled class and lots of internal
details of com.jeantessier.metrics, but there is only so much I can do in one
pass. At least, it is very readable now that I have removed all the
duplication.
August 13, 2009
Upgraded the following development components:
JUnit : 4.6 -> 4.7
The new JUnit introduces a new concept called
rules.
They are essentially interceptors for tests and a new extension mechanism for
JUnit, now that tests don't have to derive from TestCase anymore. This looks
promising. They re-implemented expected exceptions and you can now supply
matchers for more precise matching of exceptions thrown by the test methods.
Rules appear much more flexible, but they are still poorly documented. It is
unfortunate that the javadocs bundled with JUnit 4.7 do not include the
documentation of already provided rules.
Extracted styles from the Resources page.
August 07, 2009
Another example sequence diagram for the call flow across composed visitors to, this time to render a dependency closure as a call graph in text. Click the image for a better view. See also the source file.

I wanted to completely separate the textual rendering from the traversal of the
graph, but I may not be able to do that. The current TextPrinter makes
assumptions on the nature of the graph so it can remove "empty nodes". I am not
sure in this logic belongs in the rendering or the traversal or somewhere else
altogether. If it belongs somewhere else, this complicates the setup to do a
simple printout to text.
August 05, 2009
Found sdedit for creating sequence diagrams. Here is an example for the call flow across composed visitors to render a dependency graph as text. Click the image for a better view. See also the source file.

Adjusted the yEd transformation so it renders unconfirmed nodes a different color from the confirmed nodes.
August 03, 2009
Found some references to StackMap in the release notes for JDK 1.6. They
point to JSR 202, which itself points
to JSR 030 and JSR 139. It appears
StackMap is used to simplify class verification by splitting the process
between the compiler and the runtime. JSR 139 has an early specification where
the attribute is named "StackMap" instead of "StackMapTable". JSR 202 has the
full specification, so I will be able to use it to parse "StackMapTable"
attributes fully in com.jeantessier.classreader.
July 30, 2009
Had a discussion with Russ Rufer, Tracy Bialik, and Gene Volovich on my recent
experiment combining decorator and visitor patterns. Russ recommended that I
look at the code for ASM where he saw a way to
combine visitors and graph traversal that he liked. This might be inspirational
when I try to apply the same model to com.jeantessier.classreader.Visitor.
They also suggested that I could migrate Dependency Finder to ASM. This way, I wouldn't have to keep up with language developments. I vaguely remember taking a glance at ASM some time ago and finding it rather ugly. Maybe it's worth another look, if only to properly document why I don't like it. :-)
Found instructions for switching my MacBook Pro to JDK 1.6.
I was looking at CodeDependencyCollector and I noticed that some of the
visit...() methods were not calling their superclass counterparts like the
others. They were:
visitClass_info()visitFieldRef_info()visitMethodRef_info()visitInterfaceMethodRef_info()visitExceptionHandler()
I couldn't think of a reason they should not call to super, so I fixed them.
They all end up calling to VisitorBase which has all no-ops anyway. Strange,
nonetheless. This brings me back to a paper I wrote years ago for my M.Sc. on
what I called
Inherited Behavior
at the time.
Upgraded the following development components:
JUnit : 4.5 -> 4.6
I also noticed that the new SourceForge layout has a large download button on the project's home page and that it points to version 1.1.0-beta2, which is about 5 years old. It took a while to track down how to change it to the latest version, 1.2.1-beta1, and I don't know how long it will take for the change to propagate all the way to the project's home page. I don't know how long it's been this way. The download statistics at SourceForge show nothing for the last week. I hope it's just that their stats are down and not that nobody is downloading Dependency Finder!
July 29, 2009
Refactored SelectiveTraversalStrategy to create an actual
ComprehensiveTraversalStrategy to use in defaults instead of an unconfigured
SelectiveTraversalStrategy. I figure the indent is more explicit this way.
Changed SelectiveVisitor to reuse the superclass implementations when it is
appropriate. This meant changing the tests because the superclass was using
double dispatch to pass control to the delegate visitor and the original
implementation of SelectiveVisitor was calling the delegate directly.
July 28, 2009
I don't know what I was thinking when I first wrote VisitorDecorator. It was
calling the counterpart method on the delegate directly instead of using double
dispatch like I originally wanted to. I fixed the tests, mocking more things
along the way, and then fixed the code.
Cleaning up the interface, I added traverseInbound() and traverseOutbound()
to the Visitor interface. Almost all implementations already had them already
and the others ended up being no-ops.
I wrote a BasicTraversal visitor that uses a TraversalStrategy to do some
filtering, but I was not happy with it. It was not clear where scope versus
filter selections should happen. I felt like I needed a separate class to do
the scoping and the filtering, but the composition of decorators would become
non-trivial. Finally, I found a way to make it work and I got BasicTraversal
and SelectiveVisitor to be just the way I wanted.
I changed my IntelliJ IDEA configuration to use JDK 1.6 on my MacBook Pro. My shell is still stuck on JDK 1.5. I wonder how they will interact, when I happen to compile in IDEA and try to run some tool from the command line.
July 27, 2009
Started down the path of composite visitors. Wrote
com.jeantessier.dependency.VisitorDecorator to start composing visitors for
dependency graphs.
July 24, 2009
Fixed some tests. Some of the Fit tests needed better explanations. There was
one broken test in com.jeantessier.classreader.TestXMLPrinter. This last one
was checked in broken, after I made a last minute change to the XML format. I
need to be better disciplined at running all the tests before I check in code.
July 23, 2009
Fixed a typo in the web app's style.css.
Finished adding the label to the web app pages, complete with HttpUnit tests.
July 22, 2009
Adding a secondary title to the web app pages, called "label", and which can be
set from load.jsp or extract.jsp. The goal is to let automated graph
updates tack a label to the current data set, such as a revision number or a
timestamp. This lets users know which data their queries are running against.
July 21, 2009
Fixed CodeDependencyCollector to correctly track dependencies on classes and
enum values referenced in annotation values.
Found a bug: when CodeDependencyCollector visits the attributes of a class, it
attaches dependencies to the last method it visited instead of to the class
itself. Luckily, there is a handy hook called
VisitorBase.visitClassAnnotations() that lets me intercept control and restore
the current node right after visiting fields and methods and before visiting the
annotations.
July 15, 2009
Spiked on printing the call graph for closures as a chain of calls instead of a flat dependency graph.
Back on 2008-11-05, I toyed with the idea of using composition to deal with
sharing behavior in the com.jeantessier.classreader.Visitor hierarchy. At the
time, I was thinking of wrapping a TextPrinter inside a TraversalVisitor,
where the outer visitor would be responsible for traversing the structure and
would call on the inner visitor for specific processing at each node. This
created problems for XMLPrinter which needs to do both pre- and
post-processing on each node.
But what if the Printer was the outer visitor and the traversal was done by
the inner one? Then, the printer would have free reign in doing all the
"around" work it wants. It would call in to the inner visitor when it is ready
to traverse a nodes subsequent structure. The inner visitor would still have to
call out to the outer one whenever it moves to a new node, though. Reminds me
of cross recursion, somehow.
The code for visitMethod_info() would look something like:
public abstract class VisitorDecorator implements Visitor {
private Visitor delegate;
public Visitor getDelegate() {
return delegate;
}
public void setDelegate(Visitor delegate) {
this.delegate = delegate;
}
}
public class TraversalVisitor extends VisitorDecorator {
public void visitMethod_info(Method_info method) {
for(Attribute_info attribute : method.getAttributes()) {
attribute.accept(getDelegate());
}
}
}
public abstract class Printer extends VisitorDecorator {
...
}
public class TextPrinter extends Printer {
public void visitMethod_info(Method_info method) {
append(" ").append(method.getDeclaration()).append(";").eol();
method.accept(getDelegate());
}
}
public class XMLPrinter extends Printer {
public void visitMethod_info(Method_info method) {
indent().append("<method>").eol();
raiseIndent();
indent().append("<declaration>").append(method.getDeclaration()).append("</declaration>").eol();
method.accept(getDelegate());
lowerIndent();
indent().append("</method>").eol();
}
}
Notice how the printers call method.accept(getDelegate()) to get further
processing of the current node. The TraversalVisitor instead calls
attribute.accept(getDelegate()), moving the processing further along the
structure.
The flow of control would constantly pass back and forth between the two visitors. It all pretty much depends on which one starts the ball rolling.
The reason I'm revisiting this issue is because I find myself in need of a
com.jeantessier.dependency.Visitor that would traverse the graph depth-first
along inbound and outbound dimensions, instead of a the current shallow
traversal.
The code to use this would look like:
Printer printer = new TextPrinter(...);
Visitor traversal = new TraversalVisitor(...);
printer.setDelegate(traversal);
traversal.setDelegate(printer);
printer.traverseNodes(factory.getPackages().values());
And I could use it to print transitive closures, based on the start criteria.
July 14, 2009
I have been running an experiment to launch Dependency Finder as an instance of
Jetty with the web app UI. But Jetty seems flaky. It runs fine at first, but
after a while, it starts throwing messages that can cannot find classes that
are obviously in the JAR. I don't get it. I've reverted to using Tomcat for
now. I removed all the applications in its webapps folder and deployed
Dependency Finder as ROOT so I don't need a path element to access it.
July 09, 2009
Found another example of an annotation that takes array and class values even
closer to home in org.junit.Test and org.junit.runners.Suite.SuiteClasses.
And even better, TestAll has both of these, so all I need to do to find an
example is analyze TestAll.
I did a quick spike to try to track annotations as part of
com.jeantessier.classreader.MetricsGatherer. Early results are promising,
but this was just a spike so I will have to throw away that code and redo it
properly, test-first.
July 08, 2009
Found a nice example of an annotation that takes array and class values in
org.testng.annotations.Test. Though, looking closer to home,
java.lang.annotations.Retention takes an enum value and
java.lang.annotations.Target takes an array of enum values. I can play with
these manually to validate the XML format for annotation information.
Fixed XML rendering of AnnotationDefault_attribute to remove the extraneous
<element-value> node around the actual element value.
July 07, 2009
Played with filtering out files directly from DependencyExtractor. I had
forgotten about FileFilteringLoadListener and
ClassfileFilteringLoadListener. At first, I thought of using
FileFilteringLoadListener to short-circuit even the parsing of unwanted
.class files, but that didn't work. It only filters the beginFile() and
endFile() events. It does not remove any of the logic that happens between
them, nor any beginClassfile() and endClassfile() event.
At the very least, I need to augment the tests for GroupFilteringLoadListener
and FileFilteringLoadListener so they at least suppress all events with
matching group or file names respectively. Not just their own begin ... end
events, but also those that happen in between. After that, maybe I'll consider
turning the begin event into something closer to a VetoableChangeListener,
where I can suppress processing between match begin and end events based on
the handling of the begin event.
The javadocs for LoadListener and LoadEvent are dreadfully out of date.
July 02, 2009
Fixed CodeDependencyCollector to correctly track dependencies on annotations.
For now, it only captures dependencies on the annotation itself, not on any
element values that it might contain. This will come next.
I implemented support for rendering elements of runtime annotations in
XMLPrinter.
I also modified EnumElementValue.getTypeName() and
ClassElementValue.getClassInfo() so they convert class names in path
notation to a proper class name. Internally, these class names are stored as
UTF-8 strings, not ClassInfo_attribute structures, so these classes have to
take care of converting strings containing encoded class names such as
"Lfoo/Bar;" to proper class names such as "foo.Bar".
Jens Dietrich uses Dependency Finder in his gpl4jung project.
Removed dependencies on toString() when getting the names of elements of
Classfile. It is much better to be explicit about which piece of data is
needed rather than rely on what an object's string representation is. Also, it
is impossible to mock toString() using jMock.
July 01, 2009
Happy Canada Day!
Someone asked why Dependency Finder was not picking up dependencies on runtime
annotations. The answer is simple: I haven't implemented that part of Java 1.5
support yet. The code is there to read in annotations from the .class file
and include them in the Classfile structure, but I don't do anything with it
just yet.
I implemented support for rendering runtime annotations in XMLPrinter. It's
a start. I didn't get around to handling all the different types of element
values, though.
June 29, 2009
Tweaked the CSS used when converting dependency graphs to HTML (with XSLT).
June 25, 2009
Verified site ownership with Google Webmaster Tools by adding a meta tag on the site's home page.
June 23, 2009
Found out about the Google Visualization API.
June 15, 2009
Changed Classfile to track methods with a simple Collection instead of a
Map. This way, bridge methods don't trample each other. But I use a
LinkedList internally, so methods are no longer sorted by signature. All the
tests are passing for now, but suspect it will impact the logic in OOMetrics
and/or JarJarDiff.
I also tried to resurrect the WebWork web app, with limited success. I want to move it squarely into Struts2 instead of clinging to WebWork 2.2.6.
June 11, 2009
One user asked:
i have a project P that contains in some package Z a class C.
I want to know all of C's dependencies....
If all you want is C's direct dependencies, you can get them from analyzing the
compiled code in C.class. If you want the transitive closure, you sill need
to analyze all the classes along the way too. You can point Dependency Finder
to a folder and it will scan it and all its subfolders for possible Java code,
be it in JAR files, zip files, or loose .class files.
Here is how you would do it using the CLI. Start by extracting all dependencies
for project P and saving them in df.xml. You can add third party JARs to the
command if you want to drill into their dependencies too.
% cd [to P's output directory]
% DependencyExtractor -xml -out df.xml . [add third party JARs too]
Then, reduce all the dependencies in df.xml to class-to-class dependencies and
save them to c2c.df.xml.
% c2c -xml -out c2c.df.xml df.xml
Now, use DependencyClosure to list the first and second degree dependencies
from Z.C in the graph in c2c.df.xml. "Inbounds" are classes that depend on
Z.C whereas "outbounds" are classes that Z.C depends upon.
% DependencyClosure c2c.df.xml -class-start-includes /Z.C/ -maximum-inbound-depth 0 -maximum-outbound-depth 1
% DependencyClosure c2c.df.xml -class-start-includes /Z.C/ -maximum-inbound-depth 0 -maximum-outbound-depth 2
If you want to use the GUI instead, use the "Closure" tab and the
File >> Closure menu command. First, use
File >> Extract to extract dependencies for project P. Then
select the "Closure" tab. In the "Select programming elements" group of
controls, check "classes" and put /Z.C/ in the "including" box. In the "Show
dependencies (stop for closure), select "classes" but leave the textboxes empty.
Set "Follow inbounds" to 0 and set "Follow outbounds" to 1 to first degree or 2
for second degree dependencies. Click File >> Closure and
see the results in the large results area.
June 05, 2009
Looking at JavaCC as a potential help in
parsing Signature_attribute values. While looking for possible books on
JavaCC, I stumbled upon
Decompiling Java
quite by accident. It came out in 2008, so it might even be up-to-date, but the
reviews give me pause.
June 04, 2009
Reading up on Guice 2.0.
Wrapping my head around signatures. I based SignatureHelper on
DescriptorHelper, but that may not be enough. The structure of signatures is
much more complex and has a recursive nature. I may need a number of classes to
handle all the production rules in the JVM specification section 4.4.4.
June 03, 2009
A colleague pointed me to DepAn, another dependency analysis tool for Java. It seems to be built on the Eclipse platform and uses ASM for decompiling Java bytecode. It is distributed as a binary for the Linux platform. It won't work on my Mac and I couldn't get it to start on my Linux box either.
Looking into running DependencyFinder on Google App Engine or Amazon EC2. Users would have to upload their JAR files to the server, though.
May 27, 2009
Found a misnamed method. VisitorBase.visitClassfileAnnotations() should
have been called VisitorBase.visitClassfileAttributes().
Worked on Method_info.getSignature() to use the generic signature of a
Signature_attribute when it is available. In the process, I realized that I
never finished SignatureHelper.
May 26, 2009
Found out about Crap4J, but I'm having a hard time fine
tuning the sample build.xml file so I can run it on Dependency Finder. I
should add it to the Resources page.
I want to redo ClassList to simply use a LoadListener to collect class names
as they are being read in. Coupled with a lightweight Classfile, it would
reduce its memory footprint. Right now, it uses an AggregatingClassfileLoader
and parses an entire JAR completely before simply writing out class names. This
is a waste of time and memory and it hurts when dealing with really large JAR
files.
May 18, 2009
Someone found a typo in the documentation: -csv was written -cvs. It's
all fixed, now.
I fixed com.jeantessier.metrics.MetricsGatherer to use
Classfile.isSynthetic() to determine if a class is synthetic or not. It used
to look onl for the presence of a Synthetic_attribute, but in Java 1.5 the
synthetic property can be set in the ACCESS_LEVEL field of the .class file.
I will need to fix it for methods and fields too.
The deprecation level is computed the same way, by looking for the
Deprecated_attribute. But in Java 1.5, it can also be set via an annotation.
This will require more work.
May 13, 2009
Refactored CodeDependencyCollector.visitClassfile() so it calls
super.visitClassfile(classfile) to traverse the parts of the Classfile
instead of doing it explicitly. This means that it will now visit the
attributes of the Classfile in addition to its fields and methods. For now,
CodeDependencyFinder ignores the attributes that can be attached to a file,
but I'm tempted to collect dependencies from attributes such as:
EnclosingMethod_attributeInnerClasses_attributeSignature_attribute
EnclosingMethod_attribute is particularly interesting because it would be
the first time we have an explicit dependency going from a class to a feature.
I also noticed that com.jeantessier.metrics.MetricsGatherer only looks for a
class' Synthetic_attribute and does not look at the class' ACCESS_FLAG. I
need to fix this so it calls Classfile.isSynthetic() instead. The same
probably goes for other visitors and for other properties of things with
attributes.
I have been doing a lot of thinking about large projects that run out of memory
to hold the dependency graph. In one case, I have a very large JAR file with
all the project classes in it and even if I give DependencyExtractor over
1.5GB of memory, it still runs out. I could add scoping to the extractor, but
this feels like piling too many responsibilities on one tool, specially when it
is already the purview of DependencyReporter. I could partition the graph
across many machines. I can already merge graphs, so the client could ask all
partitions (in parallel) and merge the results together. But now I'm facing
the problem of how to partition the graph and how to prevent parsing the
.class files multiple times. I am exploring the possibility of having
lightweight implementations of Classfile and its constituents to help with
deciding how to partition the graph, and how this plays with the notions of
group and file in a loading session.
May 11, 2009
I've been thinking about how to deal with very large projects that Dependency Finder cannot fit into memory. I could partition the dependency graph between multiple servers, query them in parallel, and merge the results together. I already have the merge logic. Next, I need a way to partition the graph efficiently.
I could do preprocessing of the codebase to determine the partitions automatically. I could use a variation on LCOM4 for this. Well, not really LCOM4, but more of a general graph partitioning algorithm. I could generate a directed package-to-package graph with a weight on each edge that tells how many classes are involved in that edge. Then, I do a normal graph partitioning but I only consider edges with weight greater than N. By varying N, I can find the optimal partitions, including which packages are in each one.
To do the preprocessing, I could simply have a DependencyListener listen in
and tally the dependencies. But CodeDependencyCollector, which triggers the
listeners, is way too tightly coupled to NodeFactory. I would like to run
CodeDependencyCollector without a NodeFactory so it would only generate
DependencyEvent messages, and those would have enough information to
distinguish between different kinds of dependencies. I could use some kind of
non-caching NodeFactory, or rather have some other class create the
dependencies so I can have a very lightweight graph in the factory while I just
tally information about the dependencies but not the dependencies themselves for
this specific analysis.
See also graph partition algorithms at The Stony Brook Algorithm Repository.
May 05, 2009
Fixed com.jeantessier.classreader.TextPrinter so it does not put a ";" after
a class' static initialization block.
May 04, 2009
Fixed bug 2663753 which deals with the signature for a class' static initializer.
I wrote a test (using JUnit 4) which exposed that Feature_info.getName() and
Feature_info.getSignature() were calling UTF8_info.toString() instead of
UTF8_info.getValue(), which tripped the mocks created by jMock. It also
forced me to change the signature of the Feature_info constructor to depend
on DataInput, an interface, instead of DataInputStream, a concrete class.
Because the new test is a JUnit 4 test, I switched all TestAll suites to use
the JUnit 4 mechanism for constructing suites. It lets me compose suites from
JUnit 3 and JUnit 4 suites and test, all mixed and matched. I was bring back
com.jeantessier.metrics.TestMetricsGatherer into a single test target for all
tests. The Fit tests are still in JUnit 3 suites. I will need to take a good
look at them to upgrade them too, but I am too tired for this right now.
April 17, 2009
Finally got around to fixing
bug 2663688
where com.jeantessier.classreader.TextPrinter might encounter a null
Code_attribute on abstract or native methods.
March 31, 2009
Tried to get a simple example of Guice working with Struts2 in Tomcat, but no matter what I tried, I couldn't get it to work. It's like it cannot find my bindings, for some reason. I would really love to use Guice and WebWork (now Struts2) in the webapp.
March 19, 2009
Got a presentation on FindBugs by Bill Pugh, the author himself. It is a really cool tool that uses bytecode analysis, just like Dependency Finder, but in a much more targeted way to find patterns in the code that are likely to be bugs.
March 11, 2009
Refactored the way APIDifferenceStrategy collects field names and method
signatures. I extracted a method that takes a function object, a poor cousin
to blocks in Ruby. At first, I used an inner interface inside
APIDifferenceStrategy and anonymous inner classes at the call sites. But
then I thought I might reuse it elsewhere, so I pulled everything out as
stand-alone classes in com.jeantessier.classreader: interface FeatureMapper
and implementations NameMapper and SignatureMapper. Don't confuse them
with PackageMapper which is completely different.
March 10, 2009
Considering moving the behavior from CodeDifferenceStrategy.isCodeDifferent()
to Code_attribute.equals() instead. This way, if I introduce a Null Object
pattern for Code_attribute, I can make sure that nothing equals the null
object. And the code in CodeDifferenceStrategy would become a simple:
public boolean isCodeDifferent(Code_attribute oldCode, Code_attribute newCode) {
return oldCode.equals(newCode);
}
This code assumes that oldCode is not null, or you'd get a
NullPointerException. I checked all the call sites for isCodeDifferent()
and they all verify that neither oldCode nor newCode is null, so this new
version should be perfectly safe.
March 09, 2009
Tried to replace MockDifferenceStrategy with jMock, but some of the tests are
too involved with real Classfile instances to make it practical. I will need
to rewrite those tests to use mock Classfile and associated structures
instead, which will take some time.
March 06, 2009
Minor changes to phrasing in the Tools page.
Added a link to Pivotal Tracker for Dependency Finder as one of the menu items on the site's left-hand panel. I also tried to make the "Download" link stand out more by using a <strong> tag (I wanted to use <b> but IntelliJ IDEA complained that it was deprecated and suggested <strong> instead), but the effect may be too light still.
March 04, 2009
I made the Pivotal Tracker project public so everyone can see how it's doing.
Also, today, I found a
bug
in ClassReader. In text mode, when it encounters an abstract method, it
would throw a NullPointerException. The code in =TextPrinter] blindly calls
entry.getCode().accept(this) without checking that getCode() returned
something. I could use the Null Object pattern, but I'll have to check
everywhere I call getCode() first.
March 02, 2009
Playing with Jetty, I managed to make it serve a complete web app straight from the WAR file. This simple program takes a port number as the first parameter and a WAR file as the second.
public static void main(String[] args) throws Exception {
Server server = new Server(Integer.getValue(args[0]));
WebAppContext webapp = new WebAppContext();
webapp.setContextPath("/");
webapp.setWar(args[1]);
server.setHandler(webapp);
server.start();
server.join();
}
For now, the web app takes its configuration from the web.xml file that is
buried in the WAR file. I'll have to figure out a way to pass in the values
for the source and file context parameters.
February 24, 2009
Created a project on Pivotal Tracker to try and manage my effort on Dependency Finder. I know a few people at Pivotal Labs and they introduced me to Tracker a few years ago. It's a pretty cool tool, but I'm not sure how useful it will be on a single-person project with a very irregular schedule.
February 19, 2009
I am toying with the idea of using Jetty. With it, I could embed a webserver in the application instead of using Swing. This way, I can provide the user experience entirely from the web application instead of maintaining a separate Swing version.
Documentation on configuring Jetty with an existing web application is sketchy at best. I was hoping for a simple, fool-proof recipe, but it looks like I might have to do actual work to get this to work.
Reading a little more about this, it looks like Jetty already ships as part of WebWork. WebWork's QuickStart uses Jetty to provide a quick starting point for development. This QuickStart may not be the best approach for deploying an application, though.
February 13, 2009
Upgraded the following development components:
IntelliJ IDEA : 8.0.1 -> 8.1
January 26, 2009
Upgraded the following development components:
JUnit : 4.4 -> 4.5
I still haven't started converting all the test cases to JUnit 4.
January 23, 2009
Fixed targets in build.tomcat.xml that were not getting the right paths
because they were not depending on the init target.
January 14, 2009
Found a minor bug with ClassReader where it does not reset the internal
counter it uses to print a constant pool in text mode. If I ask it to print
two classes, the indices of the second class pick up where the first one left
off.
I tried to write an integration test first, but there is so much indirection
involved between TextVisitor and Classfile that it would have required quite
a bit of setup and would have ended up fairy brittle. So I settled for a small
unit test of VisitorBase.visitConstantPool() instead.
Fixed a constant duplication in data2atom.cgi where it was referencing
Journal.cgi directly instead of the more generic $DOCUMENT.cgi.
January 08, 2009
Updated the copyright notice to 2009.
December 02, 2008
Better escaping of & in Atom feed. Fixed some broken entity references in the Journal.
December 01, 2008
Looked at generating an Atom feed based on the Journal. In the process of
turning data2html.cgi into an Atom generator, I found a bug in data2html.cgi
when generating links to dated entries.
November 27, 2008
Upgraded the following development components:
IntelliJ IDEA : 8.0 -> 8.0.1
Added CodeFinder to replace the explicit iteration in Method_info.getCode().
November 26, 2008
Cleaned up how XMPrinter deals with instructions that have a value embedded in
them, such as bipush and iconst_1. Also made it show the destination
address of goto and jump instructions.
Augmented TextPrinter so it also shows the bytecode, similar to what
javap -c does, including the exception handling.
As I was looking at coverage reports to make sure I covered all the cases in
printing instructions, I was reminded that some ExceptionHandler structures do
not have a catch type, meaning they trap everything and apparently that is the
bytecode presentation of finally blocks.
I also realized that I was reading offset values for goto and branch
instructions as unsigned values, when they are actually signed. The same goes
for embedded values in bipush and sipush instructions.
November 25, 2008
Fixed the use of id attributes in classfile.dtd to use index instead. The
attribute id has special meaning in XML.
I realized that local variables can be active for only a portion of a method's
execution and that the VM can reuse positions in the local variable table for
different variables whose scope does not overlap. That significantly
complicated LocalVariableFinder. It had to take into account the position of
the instructions trying to locate a local variable and what local variables are
active at that position in the code. To complicate matters further,
instructions that set local variables, such as istore, are such that the
variable does not really exist at that instruction position but starts
immediately after. Couple that with the wide instruction and things get
pretty nasty pretty quickly.
Minor refactoring.
November 24, 2008
Added Instruction.getIndexedLocalVariable(), Instruction.getOffset(), and
Instruction.getValue() to help with text rendering of instructions. Used them
to make traces in Code_attribute and instruction data from XMLPrinter more
useful.
Simplified Instruction tests by using jMock and putting many of the tests
methods in one test class.
Bad news for Dependency Finder: I just got Tomb Raider: Underworld! >:-)
November 20, 2008
Wrote LocalVariableFinder to help find the LocalVariable of a
Code_attribute from its index in an Instruction.
Removed getCode() from the Instruction interface. The implementation can
still hold on to the Code_attribute, but that's an implementation detail, and
does not need to be part of the exposed interface.
November 19, 2008
Modified journal entries to turn dates into hyperlinks.
Extracted the implicit index from instructions xload_<i> and
xstore_<i> to be the value of <i>. Those values point
to entries in the local variable array of the current frame. I could use them
to provide better text rendering of instructions by naming the variable (when
there is a LocalVariableTable present in the Code_attribute).
November 18, 2008
Modified data2html.cgi to render dates as URLs to the corresponding journal
entry.
November 14, 2008
Simplified build.test.xml by grouping all JUnit tests under one target. With
junit-4.4.jar in $HOME/.ant/lib, it can run JUnit 4 tests too.
com.jeantessier.metrics.TestMetricsGatherer is a JUnit 4 test and it cannot
run as part of a JUnit 3 test suite.
November 13, 2008
Back on 2008-11-03, I simplified some constructors at the cost of less
useful debug traces. I was looking at traces from ClassMetrics to see how
Dependency Finder was dealing with annotations in the wild and I realized that
echoing only constant pool indices is not very helpful. I really need to
look up those values in the constant pool and include them in the trace
message.
Found a bug! It turns out that the constructor for AnnotationElementValue
was not passing the ConstantPool to its Annotation. Now that the
constructor for Annotation calls getType() for its debug trace, it forces
a constant pool look up, which exposed the problem. Hurray for tests!
Since Java 1.2, you can deprecate a programming element with the javadoc tag
@deprecated. It adds a Deprecated attribute to the programming element.
Since Java 1.5, you can deprecate a programming element with the runtime
annotation @Deprecated. I wrote a special Visitor, named
DeprecationDetector, that traverses the Classfile structure looking for
either one. I will use it to rewrite Deprecatable.isDeprecated() in
Classfile and Feature_info. This is part of a larger effort to reduce
dependencies by parts of the Classfile structure upon their containing
structures.
As I was working on DeprecationDetector, I realized that Annotation did not
expose its type property through its interface. It is odd that I did not
notice it earlier. And, I must admit, a bit scary. What else might I have
missed?
As I was trying ClassReader -xml, I realized that the elements of the constant
pool have an attribute id that gives their position in the pool. This is
unfortunate since id has a very specific meaning in XML. I should definitely
think of changing it to something more like index.
November 11, 2008
Upgraded the following development components:
IntelliJ IDEA : 8.0 Milestone 1 -> 8.0
November 05, 2008
Added visitor hooks for the substructures in *Annotations_attribute.
I've been thinking to move the com.jeantessier.classreader.Visitor hierarchy
to use more composition. I could have one class handle traversal of the
Classfile structure and delegate processing to another class that would just
focus on what needs to be done.
For instance, the visitMethod_info() methods would look like:
public class VisitorDecorator implements Visitor {
public void visitMethod_info(Method_info method) {
delegate.visitMethod_info(method);
}
}
public class TraversalVisitor extends VisitorDecorator {
public void visitMethod_info(Method_info method) {
super.visitMethod_info(method);
for(Attribute_info attribute : method.getAttributes()) {
attribute.accept(this);
}
}
}
public class TextPrinter extends Printer {
public void visitMethod_info(Method_info method) {
append(" ").append(method.getDeclaration()).append(";").eol();
}
}
But it does not work for XmlPrinter, which must generate output both before
and after processing the method's attributes.
public class XmlPrinter extends Printer {
public void visitMethod_info(Method_info method) {
append(" <method>").eol();
append(" <declaration>").append(method.getDeclaration()).append("</declaration>").eol();
// Attributes go here, somehow
append(" </method>").eol();
}
}
I could have hooks for pre- and post-traversal, but that's what led to all the
complexity in com.jeantessier.dependency.VisitorBase. So, I'm going to stick
with the inheritance-based design:
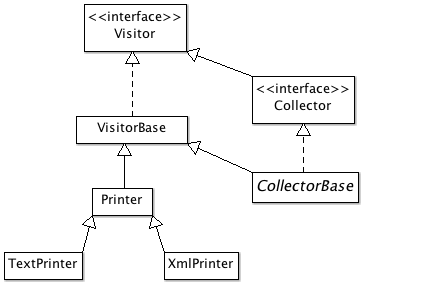
Now, the code looks like this:
public class VisitorBase implements Visitor {
public void visitMethod_info(Method_info method) {
for(Attribute_info attribute : method.getAttributes()) {
attribute.accept(this);
}
}
}
public class TextPrinter extends Printer {
public void visitMethod_info(Method_info method) {
append(" ").append(method.getDeclaration()).append(";").eol();
super.visitMethod_info(method);
}
}
and for XmlPrinter:
public class XmlPrinter extends Printer {
public void visitMethod_info(Method_info method) {
append(" <method>").eol();
append(" <declaration>").append(method.getDeclaration()).append("</declaration>").eol();
super.visitMethod_info(method);
append(" </method>").eol();
}
}
Maybe I should revisit com.jeantessier.dependency.VisitorBase, now.
November 04, 2008
Fixed a problem with IntelliJ IDEA. I am
using version 8.0M1 on a MacBook Pro. My laptop wouldn't wake up after going
to sleep yesterday, so I had to do a hard reboot. After that, IntelliJ
wouldn't recompile my classes. It kept clearing the classes directory and
then couldn't find classes to run the tests. I completely erased
~/Library/Caches/IntelliJIDEA80 and restarted IntelliJ and that seemed to do
the trick.
Added tests for Custom_attribute.
Added visitor hooks for *Annotations_attribute and
AnnotationDefault_attribute, but I did not get to their substructures, yet.
November 03, 2008
Removed ConstantPool from the public interface of *Annotations_attribute
components. The fact that some of them hold on to the constant pool and do
lookup at runtime is an implementation detail.
Fixed Parameter so it actually reads its annotations from the byte stream. I
also simplified its interface to remove the back reference to
RuntimeParameterAnnotations_attribute.
Added getAttributeName() to all attributes. I had to simplify some of the
constructors that were echoing the data as they read it in order to keep the
tests simple.
ConstantValue_attributeEnclosingMethod_attributeSignature_attributeSourceFile_attribute
But after trying it out on some sample code, I realized that it
hampers usability, so I will have to put them back in. I also removed
dependence on the behavior of toString() in a few places.
Added AnnotationDefault_attribute.
November 02, 2008
Exclude abstract base classes for test classes from Ant target to run all tests.
October 31, 2008
More support for annotations.
Removed the back-reference from Annotation back to its containing
RuntimeAnnotations_attribute because it did not make sense in the case of an
annotation as an element value.
Rigged ElementValueFactory the same way I did for AttributeFactory.
I realized that most attributes hold on to a reference to the Classfile only
so that they can get the ConstantPool from it. So I changed the code to
inject the ConstantPool directly instead of the Classfile. This
refactoring touched 84 files.
October 30, 2008
More support for annotations.
I've built support for some of the annotation attributes and pretty much all
types of element value. Now, I need to figure out how to instantiate element
values based on the tag in the byte stream. Once I have that, I will be able
to finish ArrayElementValue and write ElementValuePair so I can then
finish Annotation. Then, I will have to rig it all up into
com.jeantessier.classreader.Visitor.
Added some tests for some structures that were not covered before:
InterfaceMethodRef_infoDeprecated_attributeSynthetic_attributeSourceDebugExtension_attribute
jMock is really helping create a stage where I can exercise the classes very easily.
October 29, 2008
More support for annotations. The way the class hierarchy in
com.jeantessier.classreader.impl shadows the interface hierarchy in
com.jeantessier.classreader is very tricky.
October 28, 2008
Started writing support for annotations, TDD-style. I found a cool way to use
jMock to mock the input stream from which data structures are read. This way,
I don't have to create an arbitrary bytestream, all I have to do is mock the
calls to readInt() and so forth on the data stream.
While I was trying to mock a DataInputStream, in which all methods are
final, I found out about the DataInput interface, which is much better
(and I can mock it, no problems).
October 24, 2008
Paired with Nicolas Wettstein to add filtering capability for LoadEvent
listeners. It was nice to pair program with someone on Dependency Finder for a
change.
The hierarchy looks like this:
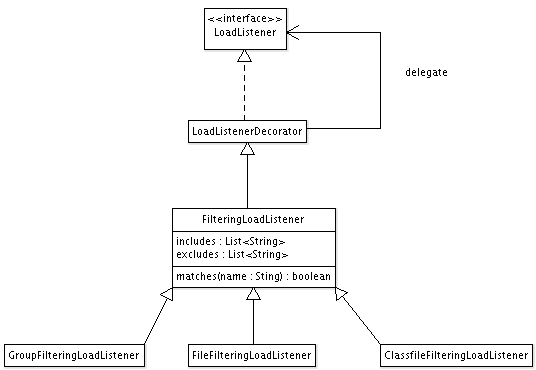
This will help with filtering certain classes based on regular expressions.
The filters extend the decorator so they can be composed with other
LoadListener implementations, such as LoadListenerVisitorAdaptor, for
example.
October 23, 2008
Removed redundant field com.jeantessier.metrics.MetricsGatherer.projectName
and associated getter and constructor parameter. The MetricsFactory inside
MetricsGatherer already has the project name. Nobody was using this field on
MetricsGatherer.
October 18, 2008
Upgraded the following development components:
Testability-Explorer : 1.10RC1-r34 -> 1.2.0-r85
I have to rewrite the <testability> tasks in
build.testability-explorer.xml to bring it in line with their latest Ant
task.
October 10, 2008
Worked on logging from the webapp. I instrumented extract.jsp and load.jsp
to log progress both to Log4J and to the servlet container logs. But maybe
this logs too much data, so I will not submit this change just yet.
October 08, 2008
Cleaned up the command-line validation in Fit tests.
I was hesitating between check and reject and ensure rows, but I came up
with a system. I use ensure rows to show good, valid command-lines and
reject to show broken command-lines. I ended up using check for switches
-echo, -help, and -version because while they are allowed command-lines,
they do not lead to running the application but short-circuit it instead.
I've been having trouble with OOMetrics lately. When I use the -csv switch
and save the output with the -out switch, the value of the -out switch is
taken as the prefix for the multiple output files, one for each of project,
group, class, and method metrics. Since the output stream is opened by the
Command superclass, it doesn't know that it has a special meaning in
OOMetrics and creates a file named after the prefix during application
startup. But that file is never used and ends up being empty.
I encapsulated Command.out behind a getter and a setter so I can do lazy
initialization on it. This way, since OOMetrics never calls
Command.getOut(), the empty file is never created.
Amended the tech docs to add Google Docs to the list of possible consumers for CSV files.
October 03, 2008
Found a way to update the project website on SourceForge. I cannot SSH into SourceForge anymore, but I could upload files with SFTP. This is annoying. I was used to updating the project webpage directly from Subversion. I remember a long time ago when I had it as a cron job that ran automatically at 3am. Now, I need to maintain a client and then upload files to the site. Some of the documentation on SourceForge about the new tools for administrators hint at a new cron-like service, so maybe there is still hope.
September 18, 2008
Added JarJarDiff report for jMock to the Samples area of the website.
September 17, 2008
Released version 1.2.1-beta1. It's been long overdue and I had to update the instructions on making a release.
September 15, 2008
A user contacted me asking how to collect the transitive closure of classes from some starting point so they could build a single JAR file with only what's needed. Here's my recipe.
Suppose you want to package the tools for the CLI together with all the classes
they require, but no other. First, get the total dependency graph for all the
JAR files in lib/ and save the graph somewhere convenient:
DependencyExtractor -xml -out dependencies.xml lib
Next, compute the outbound transitive closure from the
com.jeantessier.dependencyfinder.cli package:
DependencyClosure -xml -out closure.xml -start-includes /cli/ dependencies.xml
Next, reduce the closure to classes only, eliminating java.* and
pseudo-classes like array types. This step also removes the dependencies,
since we don't really need them anymore.
c2c -scope-excludes /^java/ -scope-excludes /\\[\\]/ -filter-excludes // closure.xml -xml -out closure.c2c.xml
Finally, extract the class names from the output from the previous command.
DependencyGraphToFullyQualifiedNames -in closure.c2c.xml -out classes.txt
Replace lib with your own JARs, and /cli/ with your own starting point, and
you should be well on your way.
Bear in mind the tricky behavior around computing closures. So you might want to reduce the dependency graph to class-to-class dependencies before you compute the closure.
September 10, 2008
Used the new jMock scripting feature
for custom actions in TestCodeDependencyCollectorUsingMocks.
Added named anchors to the entries in the Journal so I can create hyperlinks to specific entries.
September 09, 2008
Upgraded the following development components:
jMock : 2.4.0 -> 2.5.1
jMock's a() matcher is now deprecated, so I used any() instead.
September 02, 2008
Spiked to try out SLOC2, based on the minimum and maximum line numbers in a method and in a class. Running it on Dependency Finder, it yields estimates that are about 60% higher than SLOC. This is due in part to blank lines and comments, which it counts. Interestingly, it finds nothing for interfaces and abstract methods.
In the process, I got the idea to split the different concerns in
StatisticalMeasurement: collecting a bunch of values and running statistical
analysis on those values. To compute SLOC2, I needed a collection measurement
where I could collect the different line numbers and get the minimum and
maximum values. I used a SumMeasurement to compute max - min + 1. With
separate measurements for collecting values and doing statistics, it would make
the metrics config even more complex, so it may not be a win for the user.
August 27, 2008
I was using ListDiff and ListDiffToHTML for diff'ing lists of symbols when
I noticed ListDiffToHTML.xsl and ListDiffToText.xsl have template text made
explicitly for diff'ing published documentation lists. I will have to move
that text to another name and make these templates more generic.
I also have problems, under Linux, passing multi-word project names into
ListDiff. Somewhere between all the shell script invocations, I lose the
fact that more than one word makes a switch value and the tool ends up only
using the first word in the name. I have the same problem with the other tools
that take an arbitrary project name, such as OOMetrics.
August 26, 2008
Fixed tech docs for OOMetrics.
August 22, 2008
Looked into the possibility of estimating SLOC by looking at the minimum and
maximum values in LineNumberTable_attribute instances in a given class. One
problem I have, and this is true for the current SLOC calculation too, is that
fields that are initialized in initialization blocks (including constructors)
are counted twice. Also, looking at overall minimum line number versus maximum
line number takes into account vertical space as well and comments.
August 17, 2008
Spiked to adjust CodeDependencyCollector to filter parents in the dependency
graph too. If a parent does not match the filter criteria, it is not included
in the graph. I'm not sure this is the right thing to do. What triggered the
spike is that the tests around the filtering in CodeDependencyCollector were
broken when I started extracting inheritance information. The dependency on
the parent gets filtered correctly, but there is still an empty node for the
parent. I could leave it there to preserve the parent-child relationships or I
could leave it out because the filter expresses an intent to ignore it.
August 15, 2008
Fixed ListDiff so the -old-label switch defaults to the value of the -old
switch, the way it does for JarJarDiff. And the same for -new-label and
-new. Added tests for the Ant task versions of ListDiff and JarJarDiff
Refactored the changes to the CLI version of JarJarDiff by pulling them up to
the base class DiffCommand so they can be shared with ClassClassDiff.
Fixed tech docs accordingly.
August 13, 2008
Upgraded the following development components:
IntelliJ IDEA : 7.0.3 -> 8.0 Milestone 1
Added tests to CodeDependencyCollector to capture that exception handling
generates a feature-to-class dependency.
For a moment, I had the crazy idea that I could use raw class-to-class
dependencies instead of storing inheritance information separately in the
dependency graph. By inheritance, I mean both generalization (extends) and
realization (implements). But that is not going to work because there could
be other reasons besides inheritance to have class-to-class dependencies, such
as collapsing the graph with DependencyReporter -c2c.
August 12, 2008
Changed FeatureResolver so it is no longer limited to unconfirmed features
but handles all overwritten features.
August 11, 2008
First pass at FeatureResolver. Added functionality to ClassNode and
FeatureNode to navigate the inheritance hierarchy to resolve feature names.
Fixed a typo in the Fit tests for LinkMaximizer and LinkMinimizer, but
checked them in the same commit as the FeatureResolver work by accident. Oh!
and I had the wrong commit message for that, to make matters worse.
August 10, 2008
Added Fit tests for LinkMaximizer and LinkMinimizer. This is in
preparation to writing a Visitor that attempts to resolve unconfirmed nodes
in the dependency graph by walking the inheritance hierarchy.
August 08, 2008
Store class hierarchy information in the dependency graph as part of
CodeDependencyCollector.
August 07, 2008
Upgraded the following development components:
Log4J : 1.2.14 -> 1.2.15
August 06, 2008
Extracted the regular expression parsing logic out of
RegularExpressionSelectionCriteria and put it in its own class,
RegularExpressionParser, so I can reuse it the Ant version of ListSymbols.
Added FilteringSymbolGatheringStrategy to the Ant task version of
ListSymbols.
August 05, 2008
More clamping down on non-private fields, this time in MetricsReport.
Fixed some broken URLs for images in the Journal.
Still can't update the website because SourceForge's Shell service still cannot talk to the Subversion service. Grrr!
August 04, 2008
Fixed TestSymbolGathererStrategyDecorator so it tests the right class, and
not one of its descendants.
The fields of MaximumCapacityPatternCache were package-level instead of being
private for some reason. I suspect that a manual refactoring was the cause. I
made them private and neither the compiler nor the tests complained about it.
Finished FilteringSymbolGathererStrategy, including tests, and used it in the
CLI version of ListSymbols.
Normalized the names of tests for SymbolGathererStrategy implementations.
Clamped down on non-private fields, mostly in test classes. I used the new
functionality in ListSymbols.
$ ant -f build.test.xml compile
...
$ bin/ListSymbols -non-private-field-names classes
...
There were a few in test code, mostly oversights from promoting local variables to fields manually. There are still a few public fields in the code to support Fit test.
August 01, 2008
Updated documentation for the ListSymbols Ant task.
Added FilteringSymbolGathererStrategy to support inclusion and exclusion
regular expressions to ListSymbols.
July 31, 2008
Documented the new switches to ListSymbols on the the Tools page.
Fixed tests broken by new switches to ListSymbols.
Streamlined the building of CLASSPATH in junit and textjunit launcher
scripts under Unix.
Switched textjunit to use the normal JUnit 4.4 test runner instead of the old
junit.textui.TestRunner.
I noticed that the graphical UI launched by junit is now broken. It has most
likely been broken since I switched to the JUnit 4.4 binaries back on
2008-06-09 but I had not noticed. I might get rid of the graphical
launcher altogether if I cannot find a suitable replacement to
junit.swingui.TestRunner.
Brought the ListSymbols Ant task to feature parity with its CLI version.
Started to create tests for the Ant version of ListSymbols, but the Ant code
is not very testable. The Ant tasks have many trivial accessors that I do not
want to waste time testing. The interesting business logic is embedded in the
execute() method and I have to pull it out before I can write tests against
it.
The project's website is in SourceForge's Subversion repository and I update it from SourceForge's Shell service. I noticed today that the Shell service couldn't talk to the Subversion service for some reason. Someone else is having the same problem, so at least it's not just me. Apparently, SourceForge is in the process of moving its infrastructure, so maybe it's related somehow.
July 28, 2008
Worked with the CLI ListSymbols to list final methods and classes. I use
this to locate areas in the code that need special attention. I spent some
time around InnerClass to categorize types of inner classes: member classes,
anonymous inner classes, local classes. I still have to update the Ant task
and update the documentation.
Found interesting descriptions of the various types of inner classes on Gamelan.
July 23, 2008
Back from a lengthy vacation break.
Found and fixed a bug in load.jsp where it was setting the load timestamp and
duration in the application context using one name and reading it back using
another name. A reminder of the dangers of using explicit strings to save and
lookup values.
July 02, 2008
Fixed a bunch of URLs in the Journal.
July 01, 2008
Cleaned up straggling -all switches in sample code in the documentation.
Fixed some of the tools so they can read from standard input:
c2cc2pClassCohesionDependencyClosureDependencyCyclesDependencyMetricsDependencyReporterf2fp2p
This way, I can chain them on a command-line so the output of one becomes the input of the next one, just like typical Unix tools.
Found a bug with com.jeantessier.metrics.MetricsGatherer where it is not
accounting for final classes correctly. Filed it as
bug 2008537
Fixed it and added more tests.
While I was testing MetricsGatherer, I noticed some measurements are being
gathered both at the project and at the group level separately. I wanted to
remove the duplication because I could compute the one at the project level
from submetrics at the group level. This would work as long as groups matched
packages exactly. But it would breakdown if someone used group specifications
to add groups besides packages. This is why there is this duplication.
June 30, 2008
Added a CLI tool for computing class cohesion as per the LCOM4 metric. The current output is still a work in progress. It will need to ignore unconfirmed classes and possibly sort the output by LCOM4 value, both ascending and descending.
June 27, 2008
Fixed LCOM4Gatherer so it ignores constructors, as per LCOM4. I used
Perl5Util to match the feature name to a pattern, but I'm debating using
java.util.regex instead.
Code with Perl5Util:
private static final Perl5Util perl = new Perl5Util();
private boolean isConstructor(FeatureNode node) {
return perl.match("/(\\w+)\\.\\1\\(/", node.getName());
}
Code with java.util.regex:
private static final Pattern CONSTRUCTOR_PATTERN = Pattern.compile("(\\w+)\\.\\1\\(");
private boolean isConstructor(FeatureNode node) {
return CONSTRUCTOR_PATTERN.matcher(node.getName()).find();
}
For this check, I find the Perl5Util code easier to work with, and I already
use Perl5Util everywhere. But I feel java.util.regex might actually be
more efficient by using a native implementation in the JVM itself.
Maybe this logic belongs in FeatureNode instead of being replicated in a lot
of places. I guess I answered my own question.
Changed the signature of TraversalStrategy.order() so it returns the exact
same type that was passed in, using generics.
June 26, 2008
Found a better way to test for components from LCOM4Gatherer that is not
order-sensitive. Right now, the components are stored in a HashSet, so the
iteration order during tests would change depending on the implementation of
HashSet. The previous checks in the tests were assuming a specific order, so
the tests were brittle.
June 25, 2008
First attempt at computing LCOM4 from the dependency graph. Right now, the
data structure to store components of a class is simply
Collection<Collection<FeatureNode>> as I don't really have any
metadata that is not represented just as well by Collection.
June 20, 2008
Added support for inheritance data in the dependency graph. ClassNode will
point to its parents (classes and interfaces) and children. Other tools will
be able to use this information to navigate the inheritance tree when trying
to resolve dependencies.
June 19, 2008
Looked at capturing class hierarchy information in the dependency graph as part
of CodeDependencyCollector. It needs to keep track of the superclass as well
as interfaces the class implements, but maybe it does not need to distinguish
between the two.
June 18, 2008
Found a problem with my list of non-final fields and the methods that depend on them. A field may be protected and used by a subclass, but Dependency Finder will not flag it.
For example:
public class Superclass {
protected int count;
}
public class Derived extends Superclass {
public void increment() {
count++;
}
}
yields this dependency graph:
Derived
--> Superclass
Derived()
--> Superclass.Superclass()
count *
<-- Derived.increment()
increment()
--> Derived.count *
Superclass
<-- Derived
--> java.lang.Object *
Superclass()
<-- Derived.Derived()
--> java.lang.Object.Object() *
count
Here, Superclass.count is clearly a non-private field. But
Derived.increment() depends on Derived.count, not Superclass.count. The
dependency graph does not contain information about the class hierarchy, so
there is no way to discover that Derived.count is really Superclass.count.
June 16, 2008
Refactored SymbolGatherer to use a Strategy pattern when deciding which
symbols to gather or not. I want to write a custom strategy for collecting
non-private fields, which I couldn't do with the code before I extracted the
decision-making process into another object. I'm debating if SymbolGatherer
shouldn't use a collection of strategies instead, collecting symbols that
match at least one strategy.
Created a custom SymbolGathererStrategy for detecting non-private,
non-static, non-synthetic fields.
Added <synthetic> tags to fields, methods, and inner classes in the XML
representation of Classfile.
Refactored com.jeantessier.commandline.TestAliasSwitch and
com.jeantessier.classreader.TestVisitorBase to use jMock instead of custom
mocks. I was able to get 100% code coverage for
com.jeantessier.classreader.VisitorBase. I was also able to get rid
of com.jeantessier.commandline.MockVisitor.
With this in place, I was able to used Dependency Finder on another project to find dependencies on non-private fields.
$ DependencyExtractor -xml -out df.xml [JARs ...]
$ ListSymbols -non-private-field-names -out names.txt [JARs ...]
$ DependencyReporter -scope-includes-list names.txt -class-filter -show-inbounds -show-empty-nodes df.xml
I could then use these results to track where one class accesses the fields of another class and replace them with accessors.
June 12, 2008
Wrote an Ant build file for running Testability Explorer against Dependency Finder. I know the guys who work on it and it has some interesting ideas about testability behind it. I might start publishing its report along-side the coverage reports with the next release of Dependency Finder.
June 09, 2008
Upgraded the following development components:
JUnit : 3.8.2 -> 4.4
I haven't changed any of the test classes yet. I just upgraded the JAR file
that I use in compilation. Everything should still work with older versions of
JUnit, except junit.bat and textjunit.bat which refer to the JAR file by
name explicitly.
June 06, 2008
Found a way to run my tests with JUnit 4.4 from the command-line. I found
[[http://www.devx.com/Java/Article/31983/0/page/3][this article on JUnit4] on
the web and modified textjunit accordingly, and it worked just fine.
Essentially, it is this command-line:
java org.junit.runner.JUnitCore $*
With a CLASSPATH that has all the right JARs on it.
June 04, 2008
Tried to compile and run the tests with JDK 1.6. Some of the tests fail
because of the new attribute StackMapTable, but other tests in
com.jeantessier.diff were also failing. It turns out that
APIDifferenceStrategy uses HashMap internally to accumulate symbols when
looking for differences. The iteration order is different between JDK 1.5 and
JDK 1.6, which results in the strategy using different code paths to decide
that two classes are different. This throws off MockDifferenceStrategy and
therefore breaks the test. APIDifferenceStrategy could use a TreeMap
instead, which would guarantee the iteration order. While I'm at it, I should
probably re-write those tests to use jMock instead of a hand-rolled mock and
data read from disk.
May 30, 2008
Replaced the explicit name of CLI commands, set in the constructor, with a call
to Class.getSimpleName(). This allowed me to get rid of all constructors
across the entire Command hierarchy. For some obscure reason,
Commnad.Command(name) declared throwing a CommandLineException, but none of
the constructors did anything other than set the command's name. It must have
been some leftover from ancient times. I removed cruft, yeah!
May 28, 2008
Extracted the default indent text of " " (four spaces)
to constants on the various Printer classes. I can now use these constants
to set the default value for all the -indent-text switches.
May 02, 2008
Wrote a better attempt at distinguishing inner classes of the current class from mere references to inner classes of other classes. Wrote more tests for inner classes.
April 29, 2008
In an effort to better understand the InnerClass structure in .class files,
I wrote a quick XSL transform that extract just their content from the XML
output of ClassReader. It's still a mess, though.
April 28, 2008
More test for MetricsGatherer using jMock in
TestMetricsGathererAccumulators, trying to cover InnerClass. But the logic
surrounding InnerClasses attributes and their InnerClass structure is
pretty convoluted. Each inner class has seems to have an InnerClass
structure referencing itself. In enum members, they also seem to reference
the first value in the enum. Then, the enclosing class has an InnerClass
structure for each inner class in contains. It is proving difficult to
understand what I am looking at when processing an arbitrary InnerClass
structure.
April 27, 2008
More test for MetricsGatherer using jMock in
TestMetricsGathererAccumulators, covering Synthetic_attribute on classes
and Deprecated_attribute on classes, fields, and methods.
April 26, 2008
Started rewriting TestMetricsGathererAccumulators using jMock. I got through
dealing with fields and most aspects of methods, so far.
April 25, 2008
Started modifying MetricsGatherer in a test-driven way. I will need to use
jMock if I want to get through this one. I started with some precompiled
classes, but there is just too much noise. Plus, the ones I have so far don't
exercise some of the corner cases that interest me.
April 24, 2008
Looked at a subset of metrics to compare how many final elements are in a
given codebase. I will need to list elements (fields, methods, etc.) in order
to make sense of it all. Right now, MetricsGatherer simply keeps counters
for all of these measurements and simply increments them by 1 as it traverses
the code. I will need to change MetricsGatherer to send the name along to
the measurements so I can start using NameListMeasurement to get a list of
element names.
April 18, 2008
I had to change my SourceForge password because I had forgotten it. A little while ago, my password expired on SourceForge and I had to pick a new one. Now, it's been a few weeks since I last used it and I couldn't recall what it was. So I changed it again to something new. Hopefully, I will remember it this time.
April 17, 2008
Figured out how to log from JSPs with Log4J while limiting the log contents to
only the JSP code, not all of Dependency Finder. My conversion patterns in
log4j.properties have "%c{2}", limiting class names to their last two
components. This was keeping me from seeing the fully qualified class names for
the generated JSP classes, and therefore I couldn't define loggers with the
right filtering level. I took out the "{2}" momentarily, long enough to see
the full package name (org.apache.jsp), and put it back along with a new
logger definition.
April 16, 2008
Played with better logging in the webapp. Right now, the application does not
log anything. I cannot get any usage statistics from Tomcat's logs, since they
are essentially empty. In a JSP, I can use applicationContext.log(), but it
writes no information about the context of the call. Each page would have to
identify itself in the message it's trying to log. I tried to use Log4J
instead, but I'm struggling with how to specify a package that only gets the
JSPs and not all of Dependency Finder.
April 10, 2008
Updated documentation for OOMetricsGUI to account for new
-enable-cross-class-measurements switch.
April 08, 2008
Modified OOMetricsGUI so it can use a TransientClassfileLoader to process
large code bases that don't all fit in memory. This is to bring it to feature
parity with the CLI equivalent.
April 04, 2008
Modified the Ant task for OOMetrics so it can use a TransientClassfileLoader
to process large code bases that don't all fit in memory. This is to bring it
to feature parity with the CLI equivalent.
April 03, 2008
Modified the CLI OOMetrics so it can use a TransientClassfileLoader to
process large code bases that don't all fit in memory.
March 26, 2008
Fixed the Fit test for ClassFinder. A colleague suggested that rather than
getting Fit to parse four spaces as four spaces for the expected value, I try
rewriting the actual value in the fixture instead. Now it works fine, even if
it is kind of an ugly hack. At first, I tried to have the replacement text as
"<em>four spaces</em>" so that it would render in the Fit HTML
page as "four spaces". But that didn't work on MacOS for some reason. So
I switched to the less pretty but also less controversial
"****four spaces****" instead.
March 24, 2008
Fixed some Fit tests that were missing the fit.Summary at the end.
Looked further into why Fit ignores a cell with only spaces in it. This is
causing the Fit tests for ClassFinder to fail because the -indent-text
switch has " " (four spaces) as its default value and Fit keeps thinking
the expected cell value is the empty string. It turns out that somewhere deep
inside Fit, it decides to use a ResultValueAdapterByStringCompare for this
column (getDefaultValue() returns Object), and it uses fit.Parse.text()
to parse the table cell, and text() calls String.trim() before returning
its value. Darn it! Now, I'll have to find a way to supply a custom
ValueAdapter instead that knows how to keep a cell value as explicit spaces.
Simplified CommandFixture.switches(). It does not need to wrap its return
value in an ArrayFixture, FitLibrary will take care of it for you.
March 20, 2008
Added -compact and -indent-text switches to ClassFinder. -indent-text
has four spaces as its default value, and it's throwing off the Fit test.
Changed ClassMatcher so that it uses the group information from the
endClassfile event instead of relying on the group stack maintained by
LoadListenerBase.
Back on 2006-03-13, I had put up "Related links" banners powered by Google to some of the pages. They stopped working a while back and they were only showing an empty box. But today, I noticed that they started saying "Error". So I took them down.
March 12, 2008
Upgraded the following development components:
IntelliJ IDEA : 7.0.2 -> 7.0.3
March 05, 2008
There are only a few dependencies from com.jeantessier.classreader to
com.jeantessier.classreader.impl:
com.jeantessier.classreader
AggregatingClassfileLoader
AggregatingClassfileLoader()
--> com.jeantessier.classreader.impl.DefaultClassfileFactory.DefaultClassfileFactory()
AggregatingClassfileLoader(com.jeantessier.classreader.ClassfileLoaderDispatcher)
--> com.jeantessier.classreader.impl.DefaultClassfileFactory.DefaultClassfileFactory()
TransientClassfileLoader
TransientClassfileLoader()
--> com.jeantessier.classreader.impl.DefaultClassfileFactory.DefaultClassfileFactory()
TransientClassfileLoader(com.jeantessier.classreader.ClassfileLoaderDispatcher)
--> com.jeantessier.classreader.impl.DefaultClassfileFactory.DefaultClassfileFactory()
These constructors use concrete classes for the default value of parameters. They should let the caller decide what to inject. Then, the caller is free to hardwire specific values or use a dependency injection framework to supply them to the loader.
Looking at production code, I see the following instantiators of these loaders:
com.jeantessier.classreader
AggregatingClassfileLoader
AggregatingClassfileLoader()
<-- com.jeantessier.dependencyfinder.ant
<-- com.jeantessier.dependencyfinder.cli
<-- com.jeantessier.dependencyfinder.gui
AggregatingClassfileLoader(com.jeantessier.classreader.ClassfileFactory)
AggregatingClassfileLoader(com.jeantessier.classreader.ClassfileFactory, com.jeantessier.classreader.ClassfileLoaderDispatcher)
AggregatingClassfileLoader(com.jeantessier.classreader.ClassfileLoaderDispatcher)
TransientClassfileLoader
TransientClassfileLoader()
<-- com.jeantessier.dependencyfinder.ant
<-- com.jeantessier.dependencyfinder.cli
TransientClassfileLoader(com.jeantessier.classreader.ClassfileFactory)
TransientClassfileLoader(com.jeantessier.classreader.ClassfileFactory, com.jeantessier.classreader.ClassfileLoaderDispatcher)
TransientClassfileLoader(com.jeantessier.classreader.ClassfileLoaderDispatcher)
<-- com.jeantessier.dependencyfinder.gui
<-- com.jeantessier.dependencyfinder.webwork
But a lot of the tests call them too. This is not going to be trivial.
March 03, 2008
Tried to generate GraphML where class-in-package and feature-in-class relationships were modeled using subgraphs instead of simple edges, but the resulting graph didn't look too good in yEd.
For example, take this simple dependency graph:
p1
C1
f1
--> p2.C2.f2
p2
C2
f2
<-- p1.C1.f1
Using edges to represent containment, I get this picture:
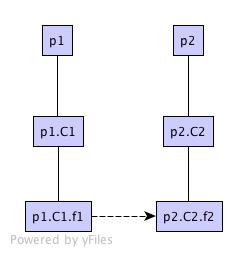
Whereas using subgraphs, I get this picture:
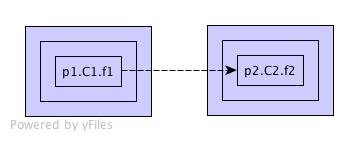
Clearly, this second form will not scale to classes with many features, or to packages with many classes.
A co-worker asked for means to determine what JARs are needed by a given JAR.
While Dependency Finder does not store the source of a class, such as its JAR
file, there are ways to get close to the answer. You can get the dependency
graph for a JAR with DependencyExtractor, roll it up to package-level
dependencies with p2p, and then list the unconfirmed packages from p2p's
output. Dependency Finder doesn't have a tool for this last step, but I was
able to put together an XSL stylesheet to do just that.
I also realized I did not document DependencyGraphToGraphML nor
DependencyGraphToyEd on the Tools page. So I took care of it at the same time
as I documented the new stylesheet for unconfirmed symbols:
DependencyGraphToUnconfirmedFullyQualifiedNames.
March 02, 2008
Added edges for class-in-package and feature-in-class relationships to the stylesheet for yEd. I want to experiment with subgraphs too and see which will autolayout best.
February 29, 2008
Added a variation on DependencyGraphToGraphML.xsl for
yEd:
DependencyGraphToyEd.xsl. It can put labels on the nodes and uses dashed
arrows for dependencies using yWorks-specific extensions to GraphML.
February 28, 2008
Added a very early version of DependencyGraphToGraphML.xsl. It turns out
producing XML from XSLT is a non-issue (as you'd expect). Just use
<xsl:output method="xml"/>, which is kinda the default if the top
result node is not some variation of <html>, according to the
XSLT spec.
I cleaned up the XSL templates. I removed explicit
<xsl:output method="html"/> tags because these templates make it
obvious that they produce HTML. I wanted to remove <xsl:strip-space>
too, but that caused memory problems for large documents, so I kept them in. I
inlined unnecessary <xsl:variable> tags all over the place.
One issue I have with all of this is that I don't have any kind of automated tests for these XSL templates. I could run a transformation and use XPath to verify its output, but that would be tedious and brittle and hard to maintain. I could record golden outputs and compare the output of transformations to them, but that would also be brittle. This latter solution would nearly be the only way to test XSL transforms that produce text.
February 24, 2008
Tried to write an XSL transformation to convert a dependency graph from the XML
format of Dependency Finder to GraphML. So far, XSLT doesn't like for me to
define another <?xml?> tag inside the XSL template. So unless I can
find a way to circumvent this, I will have to create a full-blown Printer
instead.
February 22, 2008
Someone pointed me to Google Singleton Detector, a static analyzer that looks for singleton and produces nice graph output. They use GraphML to render the graphs and yEd to view them.
The same people that offer yEd also have a UML tool called yDoc, but you have to pay for that one.
February 21, 2008
Fixed MartinConfig.xml to remove extraneous value selectors. Both Ca and
CaComp aggregated class names from IEPM with these regular expressions:
IEPM /^(.*)\.[^\.]*\(.*\)$/
IEPM /^(.*)\.[\^.]*$/
The first one matches the class name portion of method names thanks to the
parentheses at the end. The second regular expression (forget the typo for a
moment) does not include the parenthesized argument type list, so it can only
match field names. But IEPM can only contain method names, never field names,
so this second regular expression is totally superfluous. So I removed it.
With just the first regular expression, Ca and CaComp end up collapsing
IEPM to a list of distinct class names, which is what they need.
February 20, 2008
Ran testability-metrics
against Dependency Finder for fun. With no surprise, the biggest cyclomatic
complexity culprits were com.jeantessier.dependencyfinder.gui.DependencyFinder
and com.jeantessier.dependencyfinder.gui.OOMetrics because of Swing. The
class with the biggest global state cost was Instruction because it stores so
much data in the static context.
February 16, 2008
Adjusted vocabulary in Fit tests to reflect Four-Phase Test pattern from the book xUnit Test Patterns.
February 15, 2008
Someone referred me to a Danny Diggs, from UIUC, who has a tool to detect
refactorings that are done to a library and can then replay them on client code
when new version of the library gets released. This goes one step further than
JarJarDiff who can tell you if the API you relied on got changed; it can
actually modify your code to bring it in line with the new version of the
library. A quick Google search didn't find any obvious matches for this tool,
though.
Someone pointed me to testability-metrics, a tool that looks at cyclomatic complexity as a way to estimate the cost of testing any given method. It works off of compiled bytecode, just like Dependency Finder, but uses ASM for decompiling bytecode.
February 14, 2008
Added a Fit test for MartinConfig.xml.
Replaced the names of basic measurements in Metrics with an enum called
BasicMeasurements.
Simplified the Measurement interface by using autoboxing for numerical values
instead of explicit add(*)
and *Value() methods.
Replaced dependencies on Collections.EMPTY_* to their corresponding
Collections.empty*() instead for stronger type checking.
February 13, 2008
Found a possible bug with MartinConfig.xml that was the result of a typo in a
regular expression. Where it says [\^.] (a caret or anything), it should have
said [^\.] (anything but a dot) instead. I will have to write some conclusive
tests to verify the behavior of this config before I can go ahead and fix it.
February 04, 2008
Worked on getting access to Signature_attribute information in relevant
programming elements (Classfile, Method_info, and Field_info, forgot
about possible InnerClass).
Added tests for index attribute of LocalVariable and LocalVariableType
and to make sure XMLPrinter renders it, using jMock.
Added information (and tests) about varargs methods.
January 29, 2008
Dependency Finder is now seven years old.
Adjusted the copyright notice for 2008. I found a few files whose copyright notice still said 2004!
January 28, 2008
Minor clean up: removing trailing spaces.
There was a feature added to JProgressBar in JDK 1.4 where you could put it in
an indeterminate state when you didn't know how long a task would be. Back in
January 2003, I commented out the calls to JProgressBar.setIndeterminate() in
OpenFileAction and MetricsExtractAction. I think it is safe to uncomment
them now.
January 27, 2008
Played a little bit with JUnit 4.4. It is perfectly backwards compatible, so
I could just upgrade to it and keep on writing tests like with the 3.8.2
version. The are moving to a new syntax that uses
Hamcrest Matcher classes, like jMock
so you can write assertions like assertThat(actualValue, is(expectedValue)).
While it makes the code closer to English, it also makes it farther from Java.
I'm not totally convinced this is a good thing. It is more expressive, that's
for sure. What I would really like to see is an automated way to build test
suites, without me having to hard-code which tests are in a given suite. I
haven't found the mechanism to do this in JUnit 4.
January 24, 2008
Looking for a specification of the StackMapTable attribute.
Found some interesting parallels to com.jeantessier.classreader in
Javassist. There might
inspiration on how to deal with annotation-related structures. See their
documentation for
AttributeInfo.
January 23, 2008
Add jMock libraries to CLASSPATH for JUnit launch scripts (junit and
textjunit, both on Windows and Unix).
January 19, 2008
Used jMock to rewrite TestLoadListenerVisitorAdapter.
January 18, 2008
Finished separating the classes that make up Classfile into interfaces and
a implementation classes in a sub-package.
Next, I want to break the visitor hierarchy in com.jeantessier.dependency to
use composition instead of inheritance for separating graph traversal from the
specific functions. A wrapper will take care of traversal and delegate to
another visitor for the work to do. This way, I will be able to test traversal
logic with jMock instead of relying on a subclass.
January 17, 2008
Started separating the classes that make up Classfile into interfaces and
a implementation classes in a sub-package.
January 16, 2008
Clamped down on public constants for access modes in .class files structures.
I am very tempted to extract interfaces from all the classes that make up the
Classfile structure and put their implementation into a separate package. I
could possibly rewrite part of the tests with jMock and
have more control on what gets tested without having to jump through hoops to
create test classes that expose specific behavior.
January 15, 2008
Played with Ashcroft to see how
well-behaved my unit tests really were. Out of 1403 unit tests, 1224 did not
pass the test. This is not totally surprising since most tests get their data
from reading .class files. Also, I couldn't run the tests with Ant because
Ant tries to write test reports to files and Ashcroft won't let it open the
output file.
January 14, 2008
Ran Dependency Finder through FindBugs and found a
few quick fixes, including one clear bug in
com.jeantessier.dependencyfinder.cli.ListDiff where I was not closing a stream
when reading in a file. Twice. And two constants in TransitiveClosure that
were not marked final. But there were quite a few false positives too.
January 07, 2008
Finally got back to working on SignatureHelper to process the signature of
generics. For starters, I simply copied the code from DescriptorHelper and
modified it slightly. I will need to figure out how to extract common code
to a shared superclass. I also added Fit tests for DescriptorHelper and
SignatureHelper, to eventually replace the JUnit tests. It is easier to
test multiple operations on a given string using Fit tests than with JUnit,
which would require a certain amount of code duplication.
January 03, 2008
Upgraded the following development components:
WebWork : 2.2.4 -> 2.2.6
I also changed web.xml for both webapps to use JSP 2.1 with EL support. Not
that I'm using any of it yet, but just keeping up-to-date.
December 28, 2007
Played with JSTL to see if some of the tags in there could help with i18n for the webapp.
December 27, 2007
IntelliJ has really awesome support for making internationalized resource bundles. Makes me want to build one for the webapp so I can i18n it.
December 13, 2007
Upgraded the following development components:
IntelliJ IDEA : 7.0.1 -> 7.0.2
I looked into WebWork's OGNL stack and expression language. I cleaned some of the WebWork webapp files.
December 12, 2007
Upgraded my development machine to MacOS X 10.5 "Leopard".
November 28, 2007
Took a quick look at XRadar and how it uses
Dependency Finder. Interestingly, XRadar is implemented as a series of Ant
tasks and XSL stylesheets. One of the Ant tasks uses DependencyExtractor
and its output is processed by a specific XSL stylesheet. They are well
insulated from any API changes on my part.
November 26, 2007
Found out Dependency Finder is shipped as part of XRadar. Cool! I should check which part of the API they are calling. They are shipping a pretty old version: 1.1.0 dated December 2004.
A user contacted me because they are using Dependency Finder from behind a
firewall and the doctype of generated XML documents points to a SYSTEM DTD
that they cannot reach. They suggest using a PUBLIC DTD instead. I will
have to look into how that works and what the implications would be.
November 19, 2007
Added version information for Clover.
October 30, 2007
Fixed
bug 1822770
where a missing switch value on the command-line was throwing
CommandLine.parse() into an infinite loop. Thanks to
monperrm for reporting the issue.
October 25, 2007
Finished tests in TestClassReport for non-ASCII characters.
October 24, 2007
Unit tests for escaping [ and ] in HTMLPrinter.
October 23, 2007
Unit tests for escaping [ and ] in HTMLPrinter.
October 22, 2007
Unit tests for escaping [ and ] in HTMLPrinter.
October 18, 2007
More work on bug 1800017.
In the process, I made the error reporting for bad regular expressions a little
more user-friendly. I tried using a checked exception at first, but the change
quickly spread everywhere. The exception class was in
com.jeantessier.dependency and as a result, every package suddenly depended
on it, including com.jeantessier.classreader, creating a circular dependency.
So I went back to an unchecked exception for the time being.
October 09, 2007
Added a test to TestQueryBase to check for properly escaped [ and ] in
order to fix
bug 1800017.
September 24, 2007
Code cleanup.
September 21, 2007
Found a bug in the web app where elements with [ or ] in them, like
main(String[]) for example, are not escaped correctly when creating likes to
them to refine queries and generate exceptions.
September 19, 2007
Moved the Tutorial from MS PowerPoint-generated HTML to the new Google Docs presentation.
August 30, 2007
Fixed the documentation for OOMetrics to remove references to the old -all
switch in the CLI.
Changed the path in the distribution archives so Dependency Finder extracts to
a folder that include the release label in its name. Distributions used to all
extract themselves to DependencyFinder and would overwrite each other. Now,
they extract to DependencyFinder-<version> instead, like
DependencyFinder-1.2.1 for instance. The previous naming scheme worked well
when I was developing on a Windows platform and changing the PATH was
tedious. But now that I work mostly on Mac and Unix, I can use a simple
symbolic link.
I also modified the installation instructions to include the current version number directly in the text. I was already injecting it to label the instructions at the top of the document. It was easy enough to replace the reference throughout the document.
August 29, 2007
Created some test data and a FIT test for tracking extra-package dependencies
using OOMetrics. Right now, it can control access to methods, including
constructors, but it does not handle fields. That would require a bigger
change in OOMetrics.
I'm also considering adding a filtering function similar to the one in
OOMetricsGUI. If I can find a way to extract symbols at a given access
level, I could then use them to filter the metrics report.
August 28, 2007
Someone was asking for a tool to track public methods that are not used outside
their package. They could use such a tool to narrow down the exposed interface
of a library. I started thinking how I could do this using Dependency Finder.
One problem is that most tools don't record the access level of programming
elements. JarJarDiff does it, but it doesn't know about dependencies.
OOMetrics keeps a count by access level, but does not keep track of the access
level of individual methods. One possibility would be to get a list of public
and protected methods, maybe with ListSymbols, and pass them to OOMetrics
somehow. The -scope-includes-list switch to OOMetrics controls which
dependencies it tracks, not which metrics are reported. With the
-show-empty-metrics switch and a
<lower-threshold>1</lower-threshold> in the
configuration for the IEPM measurement, any method without any extra-package
dependency would stand out, but right now that includes private and package
methods.
August 27, 2007
Played with DOM and JAXP to try and figure out how non-ASCII characters get encoded by the platform. So far, they don't. I can generate an XML document using DOM that cannot be parsed back in.
August 24, 2007
I've started by renaming Report.toString() to Report.render(), just like I
did for ClassReport. Again, I am still not completely satisfied with it, but
it will do as a stop-gap measure.
I also took care of escaping special characters in <modified-fields>
tags. This introduced an interesting twist. When the value is changed,
ClassReport includes it in the content of the tag where it may need to be
escaped too. But in tag content, I don't need to escape '"' or '''. In fact,
the content is more human-readable if I don't. So I split
ClassReport.escapeXMLCharacters() into
ClassReport.escapeXMLCharactersInTagContent() for tag content and
ClassReport.escapeXMLCharactersInAttributeValue(), a more thorough version
for attribute values.
Replaced of dependency on com.sun.org.apache.xpath.internal.XPathAPI, which
is internal and was giving me compiler warnings, with javax.xml.xpath. The
code is just as clear and this time uses supported interfaces.
August 23, 2007
Redesigning the Classfile hierarchy is proving more complex than I even
thought. For now, the easiest thing to do is for me to just add constants with
values that need escaping in ModifiedPackage.ModifiedClass in the
JarJarDiff test data folder and write tests that read .class files from the
filesystem. I'll revisit jMock or EasyMock for something else at some other
time.
I modified ClassReport to be a com.jeantessier.classreader.Visitor so I can
use double dispatch to escape string values but not numeric values. It makes
more sense to have a specific visitor choose the proper rendering based on the
output format than to blindly assume one. Still, Report and ClassReport
both join two responsibilities: organizing differences and rendering them in
XML. These should be split into separate classes, which would open the door to
rendering the reports in something other than XML without the need for XSLT.
Refactored the RemovableDifferences hierarchy. The concrete classes used
protected setters to save values in the state of the superclass. Instead, I
made the getters abstract so each subclass can implement it based on its own
state instead of polluting the state of the superclass. This way, I could get
rid of the setters altogether. Some of these getters, such as
ClassDifferences.get(Old|New)Declaration() and
FeatureDifferences.get(Old|New)Declaration(), are now slightly less efficient
but I hope it won't impact overall performance too much.
Refactored com.jeantessier.classreader.TestXMLPrinter to use XPath
expressions to test the contents of the generated XML. Since it already loaded
and processed the test data folder for JarJarDiff, it indirectly tests the
proper escaping of special characters. I find that I don't need to encode '"'
or ''' since all string values are in the body of tags and never in attributes.
The only exception is the name of custom attributes and I doubt these will use
quotes or apostrophes.
August 22, 2007
Tried to use EasyMock instead of
jMock. Whereas jMock can infer decent default return
values for methods, such as false for a boolean or "" for a string, I have
to specify everything explicitly with EasyMock. And it seems to have issues
with toString() too. I might as well stick with jMock for now.
Lessons learned:
Lesson 1: don't put overly complex logic in toString(). Tools like debuggers
rely on it to display feedback, so if there is a bug in toString(), it will
cripple your debugger. ClassReport.toString() does all the XML formatting,
and that is a bad thing.
Lesson 2: mock object frameworks like jMock and EasyMock are of no help when
the path you are mocking uses double dispatch in the middle of it. I haven't
found a way to tell the mock to call some other method when it receives a given
call. In my case, I am testing part of a Visitor where the graph it is
visiting has mocks in it. When the visitor calls accept() on a mock, that
mock should call visitX() back on the visitor. There seems to be no trivial
way to specify this on the mocks.
Lesson 3: I built the classes in com.jeantessier.classreader with the
assumption that they would read well formed .class files. This makes it hard
to test small portions of the structure in isolation. All the constructors
take a DataInputStream and expect valid bytes on the stream. Setting up unit
tests is extremely hard. I cannot create a custom mock by subclassing. There
are no interfaces for me to implement. The structure is too complex for jMock
or EasyMock. I'm stuck.
Action items:
- Move rendering logic out of
ClassReport.toString()andReport.toString(). - Create constructors for
Classfileand its dependants. - Don't rely on
toString()for rendering logic.
That should make things easier to work with and speed up some of the tests. I
would be able to build a graph of model objects for the tests instead of
reading dummy .class files from disk.
I've started by renaming ClassReport.toString() to ClassReport.render(). I
still not completely satisfied with it, but it will do as a stop-gap measure
for now.
August 21, 2007
Tried to use jMock to mock parts of an API difference
structure so I can test that ClassReport.breakdownDeclaration(Field_info)
does the proper encoding of XML characters in values of string constants. I am
struggling quite a bit. The method I want to test is private, so I have to go
through a path inside ClassReport that calls it, and that path makes quite a
few calls on other structures around the Field_info. Setting up the mocks is
a little ugly and takes over 75% of the test method. Plus, it looks like jMock
never mocks calls to toString(). Maybe there is something that I don't quite
get.
August 16, 2007
A short while ago, someone filed a bug against JarJarDiff because it doesn't
encode special characters in its XML output, like '<' embedded in string values.
I got a case of that today as I was comparing two versions of a library and one
of the strings contained a non-ASCII character that was not getting escaped.
I started by writing a test against com.jeantessier.classreader.XMLPrinter
and the '>' character, only to find out that this one XML generator actually
escape certain characters already. But it's the only one to do so and it only
handles '<', '>', and '&'.
The person who filed the bug proposed using an XMLUtil class copied from some
other open source software. I'm not a big fan of utility classes so we'll see
how it all turns out. Because of the way the printer hierarchy is organized,
I might have to duplicate the escaping code between them if I don't want to use
a utility class.
August 08, 2007
Played with Doxygen to generate UML diagrams. The documentation it generates looks nice and includes where symbols are referenced from. The diagrams are rather busy because they tend to include everything. If I want to make it part of the normal documentation build, it would require people to include Doxygen too. I'm not sure I want to take it that far just yet.
Refactored NbSubMetricsMeasurement to remove some duplication.
August 03, 2007
Added SourceDebugExtension_attribute.
Added counts for the various attribute types in ClassMetrics.
August 02, 2007
Played with JDK 1.6. It screwed up some of the tests because of changes in the
language and the .class file format. For instance, there is a new
StackMapTable attribute for which I could not find any description on the
Internet. Of course, the JDK 1.6 compiler puts one such attribute in the
bytecode for test.main(). Right now, Dependency Finder represents it using
Custom_attribute, but it threw off
TestVisitorBase.testVisitCode_attribute() which wasn't expecting custom
attributes. The few bits of text I could find on Sun's website that talk
about StackMapTable also refer to a StackMap attribute, which I had never
heard off before. Makes me wonder what else is lurking in the shadows.
Since I do most of my Dependency Finder development on a Mac these days, it will still be a while before I can deal with JDK 1.6 issues.
Someone found a bug with the XML generated by JarJarDiff. When it breaks
down the declaration of constants, it shows the value for that constant if it
can, which, in the case of strings, can contain characters that should be
escaped in XML. I suspect it might be an issue for other XML generators too.
July 31, 2007
Fixed an error in metrics.dtd. members was defined as a list of members
when it is actually a list of member elements, with no 's' at the end.
July 26, 2007
Finished reading the last Harry Potter book: Harry Potter and the Deathly Hallows. Now I can get back to Dependency Finder. :-)
July 21, 2007
Started reading the last Harry Potter book: Harry Potter and the Deathly Hallows. Won't be working on Dependency Finder for a little while.
July 19, 2007
Back from vacation.
July 12, 2007
Leaving for vacation in Cancun, Mexico. Won't be working on Dependency Finder for a little while.
July 04, 2007
Monitor is too aggressive when multiple versions of a class show up in a
codebase. This can happen on large projects that depend on many third-party
software that each depend, in turn, on some popular package. For example, both
GWT and HttpUnit come with their own version of Xerces; if my project uses
both, Monitor is going to see Xerces classes twice when I try to analyze my
project. When I designed Monitor, I was assuming that it wouldn't see the
same class name twice within a session. Now, I probably want to merge
dependencies within a session and still remove everything between sessions,
regardless of whether Monitor is setup for open or closed sessions.
Refactored Monitor to use parameterized generics. Removed code duplication
in TestMonitor.
June 29, 2007
I noticed that the mnemonic() column in Instruction.html was not turning
green or red as tests passed or failed. I was using an HTML class attribute
on the cell to give it a monospaced font, but that interfered with Fit's
coloring scheme, which also uses a class attribute on the cell. The browser
was using only the first class attribute and ignoring the one from Fit. I
took mine out; it doesn't look as pretty now, but it is much more useful this
way.
In OO, a signature is something that uniquely identifies a method, typically
it is its name and the type of each parameter, in order. But Java 1.5
introduced a different meaning to the word signature: the generic information
around a class, field, or method declaration. Java in general uses the work
descriptor to refer to the combination of return type and parameter types of
a method. The object model in com.jeantessier.classreader uses signature
in the OO sense and builds it from the method's name and descriptor information.
But I feel this may get confusing as I expose the Java 1.5 Signature_info
data. I am debating whether I should rename all my *Signature methods to
*Descriptor instead; maybe even going as far as leaving the method name out
of them and let callers combine them as appropriate. I'll need to look into
this more closely.
Feature_info already has a getDescriptor() method that returns the raw
string that describes the descriptor (in the Java sense).
June 28, 2007
Refactored classes in com.jeantessier.classreader to encapsulate knowledge of
field types and method signatures in the appropriate classes. I want to better
encapsulate use of DescriptorHelper. This is a little hairy because this
package has rather poor coverage from the tests.
June 26, 2007
Added a test generic method where some parameters are not generic and some are
simple types. I think I can use the optional Signature attribute in lieu of
the descriptor, instead of trying to merge them somehow.
June 25, 2007
Extracted common code from DependencyCycles, DependencyClosure, and
DependencyMetrics and put it into DependencyGraphCommand. They load and
merge all the graphs before they can start processing. DependencyReporter
benefited also, but to a lesser degree because it optimizes the processing of
graphs as they are being loaded instead of waiting for one big graph of
everything.
June 24, 2007
Extracted common code from ClassList and cie into DirectoryExplorerCommand.
June 22, 2007
Found a bug with DependencyExtractor. If I don't give it any parameters, it
is supposed to start exploring the current directory. Instead of that, I am
getting a UnsupportedOperationException in Collection.add() when the tool
adds "." to the parameters when the parameter list is empty. I opened a bug
against it:
Bug #1741810.
This impacts quite a few tools:
ClassFinderClassListClassMetricsDependencyExtractorListDeprecatedElementsListSymbolsOOMetrics
I also found a similar somewhat similar problem with ClassReader, but this
tool uses an AtLeastParameterStrategy and requires at least one parameter.
So it makes no sense to have a special case for when there are no parameters,
since this will never happen. I looked at previous versions of the tool and
this duality has been present for a long time, so I kept the
AtLeastParameterStrategy. ClassReader is not meant to run against a large
set of classes, it is intended for use against a small set so we can inspect
their internals.
The Tools page refers to two scripts that do not exist yet: CyclesToHTML and
CyclesToText. Either I never wrote them or I somehow forgot them in some
Subversion client somewhere. I will have to dig around for them or write them
from scratch eventually.
June 18, 2007
Plugged into Google Analytics.
June 14, 2007
Fixed tests so they could run without a network connection.
MetricsConfigurationLoader takes an optional boolean as to whether or not
validate XML documents against their DTD. When running the tests without a
network connection, you can set the DF_VALIDATE environment variable to
anything but the string "true" to set the Java property
DEPENDENCYFINDERTESTSVALIDATE which in turn controls what gets passed to
MetricsConfigurationLoader. Some new tests that verify the behavior of
*.XMLPrinter also try to parse the resulting XML and need to turn off the
validation feature of the parser when the network connection is not available.
Fixed the command-line test launchers to account for the latest versions of
WebWork and Tomcat, which have changed the name and/or location of their JARs.
Note that junit and junit.bat require that you pass them -noloading for
the HttpUnit-based tests to work. They don't seem to like the classloader that
JUnit uses to reload classes between tests.
May 30, 2007
Fixed documentation.
May 25, 2007
Added isSynthetic(), isAnnotation(), and isEnum() to InnerClass. I was
even able to test isEnum()!
Rev'ed up the release number to 1.2.1 (-beta1) and adjusted the Release Plan.
May 23, 2007
Renamed SignatureHelper to DescriptorHelper. I used the word signature
in its non-java sense of a method's identifier and argument types and order.
But Java 1.5 has a specific structure in the .class file named signature to
represent information about type parameters of generics. Since my previous
SignatureHelper was manipulating descriptor constructs, I renamed it
DescriptorHelper to prevent confusion. I will introduce a new
SignatureHelper later to deal with the new signature constructs.
I took this opportunity to move some of the functionality that only dealt with
class names to the new helper ClassNameHelper. I suspect that
SignatureHelper will need it too, so it makes sense to have it in some shared
location instead of tying DescriptorHelper and SignatureHelper together
somehow.
May 22, 2007
Fixed the copyright notice that was missing from some of the newest files.
Added Signature_attribute, LocalVariableTypeTable_attribute, and
LocalVariableType to support generics.
May 15, 2007
Got a new IntelliJ license from JetBrains. Thanks Jetbrains!
May 14, 2007
Removed extra-class dependencies on access level constants in Feature_info
and Classfile and used accessors instead.
Used specialized generics in ClassMetrics.
Asked JetBrains to renew my open source license for IntelliJ.
May 13, 2007
Added Field_info.isEnum().
Fixed Feature_info to account for the new "synthetic" access flag for fields
and methods.
May 11, 2007
Moved ClassfileLoaderDispatcher actions to a first-class enum instead of an
inner class.
May 10, 2007
Implemented EnclosingMethod_attribute to handle "EnclosingMethod" attributes
of classes. Changed the classfile DTD to reflect the new attribute.
Fixed some tests that dealt with the ldc instruction.
May 09, 2007
Added a test for Classfile.isAnnotation(), including a sample annotation
class that the tests can use.
May 05, 2007
Renamed the test data class TestEnum to testenum to highlight that it is
not a regular class but just a construct to test parsing of .class files.
May 03, 2007
Added support for enum and annotation access modifiers for classes. I put
together a test for the ACC_ENUM flag, but not for the ACC_ANNOTATION
flag yet. A lot of this Java 1.5 support work is not going to be tested: it is
just too hard to generate all the possible byte streams for all the structures.
April 30, 2007
Changed AttributeFactory to use a Java enum instead of string constants when
deciding which Attribute_info subclass to instantiate. Right now, the enum
is a public standalone enum and AttributeFactory is only one static method.
I'm thinking of combining them somehow, maybe make the enum a private enum of
AttributeFactory.
April 27, 2007
Made Code_attribute implement Iterable so I can use Java 1.5's for-each
loop to iterate over instructions.
Moved processing of Instruction in XMLPrinter out of visitCode_attribute()
and in to where it belongs: visitInstruction().
April 26, 2007
Modified com.jeantessier.classreader.XMLPrinter so it shows custom attributes
and their contents.
April 17, 2007
Fixed the documentation for JarJarDiff (both CLI and Ant task) and
ClassClassDiff. I also realized I had not updated the documentation of the
Ant tasks that is on the website, so I fixed it too.
April 13, 2007
I have been using jMock at work and it is very interesting. The syntax takes some getting used to, but I might actually consider using it on Dependency Finder.
April 11, 2007
Fixed Ant build files to place the WebWork webapp WAR file in the dist
directory, next to the other distribution files.
April 10, 2007
Added a Fit test for the merging behavior of NodeFactory.
April 05, 2007
Figured a way to set properties for Ant targets within IntelliJ. On other platforms I've used, Windows and Linux, IntelliJ IDEA gets the environment variables, but not on Mac OS X for some reason. On the Mac, I have to set them explicitly in the project.
Also on Mac OS X, FitLibrary tests have trouble copying some of the images in
the files subfolder, which has a .svn subfolder with Subversion-related
files. Some of these are read-only and subsequent runs of the test suite has
trouble overwriting them again and again. I had to add a <chmod>
task in build.test.xml to circumvent this.
Finally, the Mac OS X has timestamps on files with a resolution to the second. One test was waiting only 50msec and so was failing on this platform. I've raised the sleep time to a full second, but I'm a little concerned at making the tests take even longer.
Released version 1.2.0.
April 04, 2007
Upgraded the following development components:
IntelliJ IDEA : 6.0.4 -> 6.0.5
But it seems IntelliJ IDEA on a Mac doesn't get the environment variables the way it does on Windows or Linux. As a result, Ant targets don't execute correctly.
March 30, 2007
Found a bug with OOMetricsGUI where the names of packages, classes, and
features are all prefixed with "com.jeantessier.metrics.Metrics". It turns out
the cell renderer from Swing calls toString() on the object being rendered, in
my case they are Metrics objects and their toString() method adds a lot of
debug information to the string. I modified OOMetricsTableModel to insert
only the name of the Metrics in the first column instead of the Metrics
itself.
This bug was in Release 1.1.1 and has been around for almost two years before I noticed it.
March 23, 2007
Used an Enum for the actions in ClassfileLoaderDispatcher so test error
messages would be more significant. Previously, they were integers.
Downgraded the following development components:
FitLibrary : 20070217 -> 20060116
March 22, 2007
I'm having a hard time getting all the tests to work with the new FitLibrary. I'm thinking of reverting it for now. I'll figure it out after I've launched version 1.2.0 of Dependency Finder.
Upgraded the following development components:
Log4J : 1.2.13 -> 1.2.14 Tomcat : 5.5.17 -> 6.0.10
March 20, 2007
Accessing fields of other classes is bad. Even those of your superclasses. I
just got bit by this with some of my DoFixture subclasses. They called
setSystemUnderTest() to set it, but were accessing systemUnderTest directly
instead of calling getSystemUnderTest() like they should. Of course, the
latest version of FitLibrary tightened access to this field and now my code is
broken. Luckily, the easy fix is to get it through the accessor and everything
becomes alright.
Upgraded the following development components:
FitLibrary : 20060116 -> 20070217
March 18, 2007
I tried to upgrade Tomcat and FitLibrary as part of setting up my environment
on MacOS X. Tomcat changed its directory structure between versions 5.5.17 and
6.0.10. FitLibrary changed some of its code so my code no longer compiles
against the latest version, FitLibraryRunner20070217.
March 16, 2007
I got a Mac for my next laptop. I'm going to switch development back and forth between my Windows desktop and my Mac laptop.
March 14, 2007
Refactored CycleDetector to have better logging so maybe I can find what's
the problem when looking for cycles in large graphs. I also simplified Cycle
slightly.
March 09, 2007
Finished documentation for ClassClassDiff and DependencyGraphToRDF in Tools
docs.
Refactored common parts of com.jeantessier.diff to use specialized generic
structures instead of unqualified ones.
March 08, 2007
Added documentation for ClassClassDiff and DependencyGraphToRDF to the
Tools docs.
Refactored common parts of ClassClassDiff and JarJarDiff into a new
abstract base class.
March 01, 2007
Fixed DependencyGraphToRDF so at least it runs and generates some output. I
still have no way to verify the validity of its output.
February 28, 2007
Tech docs. Still need to document:
ClassClassDiffDependencyGraphToRDF
DependencyGraphToRDF appears broken and I have no way to verify the validity
of its output.
February 23, 2007
Use the new (in JDK 1.5) Class.getSimpleName() instead of cutting it out
myself as I used to. I also added a similar method on objects that tend to
model classes, like Class_info, Classfile, and ClassNode.
February 22, 2007
I noticed that calling CLI commands with the -version switch when the command
has mandatory parameters or switches resulted in an error message and no
version information. I reorganized the command-line parsing logic so it
collects error messages in a manner that does not prevent processing a
-version or a -help switch.
February 21, 2007
Fixed the ParameterStrategy for ClassReader, DependencyClosure,
DependencyCycles, DependencyMetrics, and DependencyReporter. When I
refactored the CLI into Command subclasses, I inadvertently removed the
constraint that these tools require at least one file to work on. I looked at
the dependencies on ParameterStrategy constructors between version 1.1.1 and
the latest code and I could determine which CLI commands needed a different
strategy from the others.
Created a launch script for Log4J's Chainsaw. Between times that I actually need to look at logs to debug something, I keep forgetting how to start it. This way, I don't have to remember anything.
February 16, 2007
Tech doc for CLI version of DependencyCycles. Changed scope
switches / attributes to start ones instead, similar to DependencyClosure.
Changed CommandLine.getSwitch() to throw an IllegalArgumentException
instead of a checked CommandLineException when it cannot resolve a switch
name. This simplified the signature of many methods that deal with setting up
the CommandLine object in the CLI.
Fixed a bug in DependencyCycles where it was opening its own writer instead
of using the one setup by its superclass. Revised all writer usage across CLI.
February 15, 2007
Minor refactoring in the GUI code to remove warnings.
February 08, 2007
Modified extract.jsp so the webapp can filter out dependencies at extraction
time too. I also changed the default values of showSource and showFile to
true. It makes more sense to show these values while someone is trying to
configure Dependency Finder and hide them later, if needed.
February 05, 2007
Someone raised a problem with JarJarDiff and PublishedDiffToHTML.xsl. I
was able to reproduce their problem, but when I looked how it works in the
latest version, I found some bad text in the Tools documentation as well as
the documentation of the matching Ant task. I want to remind everyone that in
version 1.2.0, you won't use XSLT to narrow down the diff report but do it
right inside JarJarDiff instead with the level switch.
Worked on documenting the new AliasSwitch.
February 02, 2007
Found another competitor, and curiously enough, they're called JarJar. There are even instructions on how to use it to find JAR-to-JAR dependencies.
January 29, 2007
Changed the next version number from 1.1.2 to 1.2.0. The scope of changes warrants a higher version number.
Added package comment to com.jeantessier.dependency to give an overview of
the package hierarchy. Maybe that would better belong in an overview.html
file, I have fully made up my mind, yet.
January 26, 2007
New -echo command-line switch for all CLI commands.
January 25, 2007
Received praise for Dependency Finder from Peter Lenahan, Technical Director, Information Builder, Inc. I've added it to the website.
January 16, 2007
Upgraded the following development components:
IntelliJ IDEA : 6.0.2 -> 6.0.4
January 06, 2007
Updated the copyright notice to 2007.
January 05, 2007
Working on release instructions with Subversion instead of CVS.
January 03, 2007
Added sample graphs as XML documents for one example in the Developer Guide and for the graph used by the webapp tests.
January 02, 2007
Fixed some of the build files so running Clover analysis doesn't clear Emma reports, or vice versa.
December 30, 2006
Finished refactoring the CLI commands. Made some fixed to the tools documentation in the process.
Adapted the build file for Clover for Clover 1.3 and streamlined the flow to generate a coverage analysis report. Emma copies instrumented files to a separate directory, but I can't seem to get Clover to do the same. Since some of the metrics and API difference tests operate on compiled Dependency Finder classes themselves, the instrumentation throws them off. But the resulting code coverage analysis seems close enough just the same.
December 29, 2006
Validate -maximize and -minimize switches to DependencyExtractor, just
like in DependencyReporter, complete with Fit tests.
Clean up Ant targets across build files and clean up documentation. In the process, I found a typo where a '*' was not escaped properly and the HTML generator could not replace the encoded sequence with a '*' in the output.
Listed third-party packages in the Developer Guide, including some tentative version numbers that are known to work with Dependency Finder.
Looked at fixing the Clover code coverage build file. Got rid of the section on jcoverage, since I can't seem to find a version of it that does not require Eclipse.
Added a link to my LinkedIn profile
Jean Tessier on LinkedIn
![]() at the top of my "Jean's Journal" blog.
at the top of my "Jean's Journal" blog.
December 28, 2006
New AliasSwitch to handle command-line switches that are simply an alias for
a collection of other switches. This way, com.jeantessier.commandline can
handle aliases and their rendering in usage messages instead of each individual
CLI command. I modified DependencyReporter and DependencyMetrics to use
the new aliasing mechanism. I had to modify CommandFixture so I could test
command-line parsing and alias configurations as part of the Fit tests.
I refactored the buffer handling in com.jeantessier.commandline.Printer to a
new class com.jeantessier.text.PrinterBuffer. Other printers will be able
to use it too to remove code duplication between them. I already modified
com.jeantessier.diff.Printer and com.jeantessier.diff.ListDiffPrinter.
Other printers will take longer because they are wrappers around PrintWriter
instead of StringBuffer.
Figured out how to exclude sample classes that are only test data from Emma
reports. I cleaned up build.emma.xml and the procedure for running the
coverage report to make it much simpler. I no longer need to invoke a separate
target from build.text.xml to generate the rest of the test data.
December 23, 2006
Unit tests for MultipleValuesSwitch.
December 18, 2006
Refactoring CommandLine to verify satisfaction of command-line switches.
December 16, 2006
Unit tests around command-line parsing to prepare for upcoming support for aliasing.
December 15, 2006
Push isSatisfied() behavior in CommandLineSwitch implementations.
December 14, 2006
Refactored DependencyMetrics as part of the grand CLI refactoring.
Refactored the control flow for parsing and validating the command-line in
Command. One problem I still have is that multiple errors trigger multiple
printing of the usage text.
December 13, 2006
Refactored DependencyClosure, DependencyCycles, and DependencyReporter
as part of the grand CLI refactoring.
Emma recommends that you use an enabled
attribute on <emma> tags to control whether instrumentation is done or not.
The attribute takes its value from a flag property in the build.xml file
under a special target that you put on the command-line, before the instrument
or report targets. This way, the flag gets set in the emma target so that
it enables the <emma> tags in other other targets.
My Emma-related Ant tasks are dedicated to doing code coverage, so I end up
always calling them with emma on the command-line. Since I never turn the
flag off, I removed it altogether and got rid of the emma target. Now, I
will be able to trigger the code coverage targets from within IntelliJ.
Refactored Command to remove duplication when populating groups of related
switches, such as for start and stop criteria and for filtering.
December 11, 2006
Reorganized the build files to get all test reports in one location.
December 10, 2006
Refactored ClassMetrics as part of the grand CLI refactoring.
December 09, 2006
When I reorganized build.xml, I changed the project's name from
"DependencyFinder" to "Dependency Finder" with a space. Now, I use the project
name to build the name of the JAR file when creating a distribution, so now the
JAR file had a space in its name. Yuck! So I changed the name back to
"DependencyFinder", without the space.
Refactored ClassFinder and ClassList as part of the grand CLI refactoring.
Cleaned up dependencies between Ant targets for Emma coverage analysis.
December 05, 2006
Reorganized build.xml into a number of build file. This way, someone can
compile Dependency Finder with a minimum of third-party libraries, namely
the Servlets API and WebWork, instead of needing all the libraries used for
testing like Fit and HttpUnit.
I should get rid of the CVS report tasks eventually, now that everything is in Subversion. I don't know if I will create equivalent reports like Subversion, given that SourceForge already has some statistics on source control.
December 04, 2006
Finally got Emma to run. Looking at the
coverage data, I found some test classes that were not included in the
appropriate TestAll class.
December 03, 2006
Experimented with Emma for code coverage.
December 02, 2006
Tried to run the code coverage analysis with jcoverage, but my version (1.0.5) does not generate valid Java 5 code when it instruments the code. I was not able to find a more recent version; the jcoverage website only mentions Eclipse plugins. I am going to try using Emma instead.
December 01, 2006
Fixed test for ClassClassDiff. Had to move -xml switch out of Command
and back into ClassReader and DependencyExtractor to account for tools that
will not support multiple output formats, namely ClassClassDiff and
JarJarDiff that only output XML.
November 30, 2006
Major refactoring of ClassClassDiff to use common code from Command.
November 29, 2006
Better use of the facilities in FitLibrary to minimize the amount of fixture code and maximize reuse.
Major refactoring of DependencyExtractor and ClassReader to pull common
code into the new base class Command.
November 28, 2006
Started refactoring the CLI classes, with the help of FIT tests. It hints that
more refactoring is needed in com.jeantessier.commandline.
November 19, 2006
Refactored com.jeantessier.commandline to simplify printers for usage and
echo of parsed command-line. The latter still doesn't echo parameters; it
only does switches at this time.
Refactored com.jeantessier.commandline to store parameters in the
ParameterStrategy instances instead of the CommandLine. Just like switch
values are stored in the CommandLineSwitch objects, now the parameters are
also store outside the CommandLine object.
Cleaned up classes in the CLI and Ant tasks packages.
Upgraded the following development components:
IntelliJ IDEA : 6.0.1 -> 6.0.2
November 18, 2006
Added com.jeantessier.commandline.TextPrinter to echo the command-line, as
perceived by a program. Some recent problems with the CLI stemmed from
improper escaping of shell metacharacters. I hope that with some kind of
-echo switch users will be able to see what values made it into the program.
I had to rework CommandLineSwitch so each switch contained its own name.
This gave me the occasion to add unit tests to that package.
November 16, 2006
Added filtering to DependencyExtractor. This came at the suggestion of a
user that it might help deal with very large graphs by removing dependencies
that do not really bring new information, like dependencies on classes in the
JDK for instance. I added the functionality to both the CLI and the Ant task,
but I will also need to do something about the webapp and the GUI.
November 13, 2006
Simplified the command-line switch processing for DependencyFinder,
DependencyCycles, and DependencyMetrics. I need to build aliasing support
in com.jeantessier.commandline instead of handling aliases in each CLI tool's
main() method.
I also adjusted the output form DependencyMetrics so it does not show NaN or
infinity when ratios involve a zero.
I am seeing again the case where the report from DependencyMetrics shows
strange numbers. The number under "outbound link(s)" is the sum of the
breakdown under "inbound link(s)" and vice versa. I remember looking into this
a while back and somehow convincing myself that this was right, but I am still
confused, which probably means I need to fix these sections so they are more
intuitive.
I also removed the -all switch from the CLI OOMetrics.
November 12, 2006
Removed -all and -show-all switches from DependencyReporter,
DependencyMetrics, and DependencyCycles. I also removed their equivalent
in the matching Ant tasks (DependencyCycles doesn't have an Ant task yet).
Now, they act as if -all is on unless the user explicitly specifies at least
one of the scope or filter switches (-package-scope, etc.). The same logic
applies to -show-all: DependencyReporter will show everything unless the
user explicitly requests only certain things. This means that if you give now
switches to DependencyReporter, it will print out the input graph as is (but
in text instead of XML). I believe these defaults make more sense than the
previous ones that would print nothing unless you remembered to actually ask
for something.
November 11, 2006
I want to write tests for the improvements I did to XMLPrinter for
Instruction and to CodeDependencyCollector, but the classes in
com.jeantessier.classreader were among the first I wrote for Dependency
Finder and they are not easy to test. Their constructor takes a
DataInputStream with the binary data for a complete class. This makes it
very hard to get test data without building actual Java classes and compiling
them. Especially when trying to test specific instructions. I will need to
change all of them so I can construct temporary structures in tests, but that
will take a while and I don't want to delay the upcoming release more than I
have to.
November 09, 2006
I have half a mind to unify the HTML styles for dependency graphs in the webapp versus the XSLT transform used by the CLI and the Ant tasks. I think the style in the webapp looks better in the end.
November 08, 2006
It turns out the problem with closures comes down to Windows batch files strip
'^' characters from parameters. So if you want to filter out java.* with a
regular expression /^java/, the Java program only gets /java/ and filters
everything with "java" anywhere in it. I filed a
bug report (1592817) for it.
For now, the best solution is to enclose regular expressions in double quotes,
such as "/^java/", so the shell and script don't strip anything. Similarly
under Unix, if you regular expression contains many meta-characters like '\',
'(', or '[', you need to escape them properly. Maybe there is no fix for it
besides education. I should add a note on this in the documentation.
November 07, 2006
Came upon an interesting consequence of using JDK 1.5+. Take this simple class:
package test;
public class Test {
public void test() {
Class[] array = new Class[1];
array[0] = String.class;
}
}
If I compile it using JDK 1.4 and then run DependencyExtractor on it, I get:
java.lang *
Class *
<-- test.Test.class$(java.lang.String)
<-- test.Test.class$java$lang$String
<-- test.Test.test()
forName(java.lang.String) *
<-- test.Test.class$(java.lang.String)
ClassNotFoundException *
<-- test.Test.class$(java.lang.String)
getMessage() *
<-- test.Test.class$(java.lang.String)
NoClassDefFoundError *
NoClassDefFoundError(java.lang.String) *
<-- test.Test.class$(java.lang.String)
Object *
<-- test.Test
Object() *
<-- test.Test.Test()
String *
<-- test.Test.class$(java.lang.String)
<-- test.Test.test()
test
Test
--> java.lang.Object *
Test()
--> java.lang.Object.Object() *
class$(java.lang.String)
--> java.lang.Class *
--> java.lang.Class.forName(java.lang.String) *
--> java.lang.ClassNotFoundException *
--> java.lang.ClassNotFoundException.getMessage() *
--> java.lang.NoClassDefFoundError.NoClassDefFoundError(java.lang.String) *
--> java.lang.String *
<-- test.Test.test()
class$java$lang$String
--> java.lang.Class *
<-- test.Test.test()
test()
--> java.lang.Class *
--> java.lang.String *
--> test.Test.class$(java.lang.String)
--> test.Test.class$java$lang$String
The compiler created synthetic features to store the reference to
String.class. All this machinery adds a lot of complexity to the dependency
graph.
In JDK 1.5, they expanded the VM instructions to handle this case and now the
compiler can generate much simpler bytecode. If I compile the class with JDK
1.5 and then run DependencyExtractor on it, I now get:
java.lang *
Class *
<-- test.Test.test()
Object *
<-- test.Test
Object() *
<-- test.Test.Test()
test
Test
--> java.lang.Object *
Test()
--> java.lang.Object.Object() *
test()
--> java.lang.Class *
Notice the conspicuous absence of java.lang.String from the graph. This is
because Dependency Finder does not understand the Java 1.5 features of the
bytecode, yet.
I make a quick change to CodeDependencyCollector so it could at least
account for the new behavior of two VM instructions (ldc and ldc_w) in
Java 1.5. With this change, DependencyExtractor now gives this much simpler,
yet accurate graph:
java.lang *
Class *
<-- test.Test.test()
Object *
<-- test.Test
Object() *
<-- test.Test.Test()
String *
<-- test.Test.test()
test
Test
--> java.lang.Object *
Test()
--> java.lang.Object.Object() *
test()
--> java.lang.Class *
--> java.lang.String *
While working on ldc and ldc_w handling, I also realized the XML output for
instructions wasn't descriptive enough to let me know which entry they are
referencing in the constant pool. In the case I was looking at, the
instruction could point to a class_info structure or to a Utf8_info
structure and I couldn't tell which one it was. So I added an index
attribute to the <instruction> tag so whoever reads the file can see
exactly what the instruction is referencing.
Someone contacted me with an issue regarding closures. Apparently, filtering is not working correctly. I tried to recreate the problem, but it worked just fine for me. These kinds of bugs are always annoying to work on since I cannot reproduce it to examine it.
November 03, 2006
Tried to convert the tutorial to HTML using OpenOffice instead of PowerPoint. The resulting HTML works in more browsers, but the embedded images look crappy.
October 31, 2006
Did a quick study of the download rates for Dependency Finder, based on the statistics from SourceForge. It's nice how downloads flow from one release to the next, except that every once in a while, some of the old releases still get downloads even when there are multiple new releases after them. I wonder what could motivate someone to fetch an old release. Release 1.1.1 is holding up at over 300 downloads per month; I'm happy.
Cleaned up HTMLCyclePrinter.
October 29, 2006
More closure functional tests to test hyperlinks in the HTML. Also created
some functional tests for cycle detection and metrics. I added an HTML
implementation of CyclePrinter to provide hyperlinks for the cycle detector
portion of the webapp.
October 24, 2006
Someone complained that the Tutorial only works on Microsoft products and I should move it to open source technologies. I'll try OpenOffice when I have some time.
October 23, 2006
More closure functional tests.
October 20, 2006
Upgraded the following development components:
WebWork : 2.2 -> 2.2.4
October 19, 2006
Clean up extraneous logging in TestQueryBase.
October 18, 2006
Clean up warnings in JSPs.
October 11, 2006
Created preliminary tests for closure.jsp.
Upgraded the following development components:
IntelliJ IDEA : 6.0 -> 6.0.1
October 09, 2006
Added hyperlinks on scoped node names in HTMLPrinter for the web app so the
user can narrow down the scope to a single package, class, or feature. It is
not perfect, and sometimes behaves in surprising ways, but it is as good (or
bad) as the hyperlink on dependency names. Note that each link simply forces
the scope-includes field to a certain prefix; it does not change the flags
for what is in scope, whether it's packages, classes, and/or features.
Suppose a query result has lots of packages, classes, and features. You can click on a class name reduces the scope to elements prefixed with that name. In the query result, if you click on the package's name, it will expand the scope of the query back to all elements in the package.
Modified advancedquery.jsp so it uses HTMLPrinter. Refactored TestQuery
to share tests between query.jsp and advancedquery.jsp. I also added tests
that actually follow the hyperlinks to verify they do the right thing.
October 06, 2006
Fixed bug where if the scope was reduced to an inferred feature of a confirmed
class, the class and its package ended up unconfirmed in the resulting
sub-graph. GraphCopier and GraphSummarizer were using the current node's
confirmation status when copying a node a propagating it to its parent nodes
instead of creating accurate copies of the parent nodes in the first place.
Fixed the webapp's CSS stylesheet to treat visited links to inferred nodes
correctly. The rules for a:visited and a:hover trump an explicit style
assigned via the class attribute. I had to create explicit descriptions for
a:visited.inferred and a:hover.visited.
October 05, 2006
Adjusted dependency printout in HTMLPrinter so the '*' for inferred
dependencies is not inside the <a> tag. Also used CSS to highlight
scoped node names and subdue inferred nodes (both scoped nodes and
dependencies).
October 03, 2006
Upgraded the following development components:
IntelliJ IDEA : 5.1.2 -> 6.0
October 01, 2006
Fixed CLASSPATH in the launch scripts for JUnit to include WebWork libraries.
September 29, 2006
Changed classes in the com.jeantessier.dependency.Printer hierarchy to use
separate methods for printing scoped node names from dependency node names.
This lets me put scoped nodes in bold in the HTML output and leave dependency
names in regular font. I should probably use CSS instead of hard-coding the
bold using <b> tags, though.
Fixed CLASSPATH in the launch scripts for JUnit to include all the libraries
needed by HttpUnit. For the Windows batch file, I had to list all JARs
explicitly because I don't have a good way to detecting *.jar like I have in
Bash shell scripts.
There is a weird interaction between the JARs that breaks Commons-Logging when
using the Swing UI of JUnit. If I don't use the automatic class reload
feature, it works just fine. I tried playing with
tests/junit/runner/excluded.properties so JUnit would not reload the obvious
candidates (Commons-Logging, Jasper, even ServletUnit), but to no avail.
September 27, 2006
Added an id attribute to <a> tags from HTMLPrinter to help with
testing.
September 20, 2006
Made some progress with ServletUnit. It really helped to read through the
tutorial.
Step 3
had the piece I was missing to correctly submit forms and navigate between
pages.
September 19, 2006
I starting to lose patience with ServletUnit. This is a case where I can do
something in 10 minutes, but it is taking me weeks to get it under test. This
is frustrating. If I don't find a way to get ServletUnit to work soon, I
will have to drop it and go without test for the outermost layer of the UI.
I took a look at JUnit 4.1. It uses annotations to mark the test methods and the fixture setup and tear down code. It would be a significant effort to switch to JUnit 4. Plus, I hear that support in IntelliJ and Ant is still behind. I think I'll stick with JUnit 3.8.2 for now.
September 15, 2006
I tried to fix the broken test with ServletUnit, but to no avail. Instead of
navigating to the page I want by following links, I tried setting the request
parameters directly from the test, but that doesn't seem to work either. I log
the HTML that comes back in the response, and it is as if I hadn't set any
parameters. Something still escapes me when it comes to using ServletUnit.
September 07, 2006
Minor fix to data2html.cgi to remove target attribute from generated
<a> tags.
September 06, 2006
Got my first ServletUnit tests to pass. As long as I just request a single
page, it works fine. But when I use the controls on a page (submit button) to
navigate to another page, I get a strange NullPointerException from deep
within the framework. Sigh.
August 31, 2006
Started writing tests using ServletUnit, but I can't seem to get it right.
August 30, 2006
Searched the web for examples of how to use ServletUnit.
Good news for Dependency Finder: I finally finished Half-Life 2! >:-)
August 29, 2006
Downloaded HttpUnit and checked the
documentation for ServletUnit. It doesn't seem as trivial to use as I would
have hoped.
August 25, 2006
I want to finish putting web links in the results of the webapp, but how am I
going to test them? I searched for "testing servlets" and "testing jsp out of
container" and found references to ServletUnit, a part of
HttpUnit.
August 05, 2006
Investigated a little more the problems with closure.jsp, but I cannot seem
to reproduce the original problem. I tried simple graphs, I tried working from
com.jeantessier.dependency.NodeFactory.createClass(), they all seem to work
just fine.
August 04, 2006
Played a bit with TeamCity, by the
makers of IntelliJ IDEA. While I was trying to set it up for Dependency
Finder, I was confronted with the fact that I create the distribution files in
the same folder as the build.xml file. I should really put them in their
own folder, like dist/, so TeamCity can recognize them as build artifacts.
It would also align my build better with the best practices out there.
July 19, 2006
Fixed HTMLPrinter to properly escape the '$' in inner class names. Since '$'
has special meaning in Perl regular expressions, it must be escaped otherwise
the regular expression does not match anything and you get empty results.
July 10, 2006
Came back from a three-week vacation.
Upgraded the following development components:
IntelliJ IDEA : 5.1.1 -> 5.1.2
June 16, 2006
Looked at fixing closure.jsp so that it always match packages and also match
classes when looking for features. It's not quite there yet; I will need to
think harder about this problem and why closure.jsp is sometimes unresponsive
or plain wrong.
June 15, 2006
Use specialized collections in package com.jeantessier.dependency.
June 14, 2006
Looked a little at closure.jsp and tried to figure out why it returns an
empty closure when I give it a perfectly valid starting point. The classes
involved with TransitiveClosureEngine are not instrumented with Log4J, which
hinders me a little. I will have to take care of that before I can
investigate further. I also need to come up with sample data that reproduces
the problem. I tried a trivial graph a.A.a() --> b.B.b() --> c.C.c() but
that one worked just fine.
I was discussing the com.jeantessier.dependency.Visitor hierarchy with a
colleague and complained about the complicated contract for children of
VisitorBase, especially for the printers. During the discussion, it dawned
on me that I could try composition instead of inheritance. The visitors would
delegate traversal to a strategy, the way they do now, but they could also
delegate processing of each node to another collaborator. The contract with
the processor would still be fairly complex to preserve flexibility, but
might be easier to manage.
A user raised an issue with DependencyClosure as they were trying to compute
a class-level outbound closure. Some classes at the edges were missing unless
they used -maximize during extraction. Without looking, it looks
suspiciously related to some
tricky behavior
I documented in the Manual already.
June 10, 2006
Functional tests for com.jeantessier.dependency.MetricsGatherer.
June 09, 2006
I decided against having CycleDetector summarize the graph to do
class-to-class cycle determinations. For the CLI and Ant users, they can use
DependencyReporter to reduce the graph explicitly. For the GUI and web app
versions, I will hard-code the reduction in the commands themselves. I'll have
to see if it takes too long, maybe I can cache the reduced graph instead of
recomputing it for every call.
June 08, 2006
For some reason, I cannot compute closures with the web app anymore. I will
have to investigate further. query.jsp finds the node I'm interested in and
shows dependencies in and out of it. metrics.jsp also sees it and can
compute measurements about it. But when I try the same regular expression in
closure.jsp, I get an empty result.
There is a problem with DependencyMetrics. The sub-heading under outbound
add up to the total for inbound and vice versa. Sure enough, that's what the
code is computing. I'll have to study my own code again to figure out what was
the original intent. Maybe I can write some tests, this time around, to
document what it is supposed to do.
June 06, 2006
Today is 6/6/6!!!
Wrote a functional test to investigate finding dependency cycles at the class
or package level with a graph that goes down to the feature level. The fact
that CycleDetector extends VisitorBase, with all its baggage, will not make
it easy to sort it all out.
June 02, 2006
Opened a ticket (1499643) with SourceForge about my commit problem. Apparently, I am not the only one. I found at least one other ticket (1499575) with the same problem and others are also having trouble commiting but get different error messages.
Fixed my issue with table width in the new webapp pages for dependency cycles.
I tried to load the webapp with the dependency graph for Dependency Finder and
find class-level cycles starting at com.jeantessier.classreader.Visitor,
specifying it a maximum cycle length of 5. The CPU went to 100% for over two
hours and never came back. In the end, I had to kill Tomcat. I'll have to
investigate why this happened and if it is a bug or just that CycleDetector
is not really useful in real life.
Found out SourceForge added a new permission on user accounts for Subversion access. I granted myself permission but it didn't work right away. I guess there is a propagation delay between the user management system and the permission system. It's all better now.
Upgraded the following development components:
Tomcat : 5.5.15 -> 5.5.17
June 01, 2006
Wrote a page for dependency cycles in the webapp. I still have only a minor issue with the layout of a table.
Cannot commit to SourceForge's Subversion for some reason. I am getting a
403 Forbidden error code.
May 31, 2006
Wrote an Ant task for dependency cycles.
May 27, 2006
Added code to specify the indentation text on CyclePrinter classes and stream
data to a Writer.
Wrote a CLI tool for dependency cycles. Next will be an Ant task, a webapp page, and a GUI tab, not necessarily in that order.
May 26, 2006
Wrote a quick XML renderer for Cycle and an initial DTD.
May 25, 2006
Fixed a bug with name length-related metrics. It was assuming method names with parentheses in them and some of the tests were using plain names like "foo". I reworked the name computation so it is more reliable, for features and for classes alike.
May 18, 2006
Re-did the text rendering of Cycle from scratch. This time, I created unit
tests around TextCyclePrinter. Getting Fit to process text somewhat properly
was more difficult than I expected. At first, I tried using check rows, but
it got confused by \r\n versus \n line terminations. Then, I tried using and
ArrayFixture to break down the lines of the text, but when Fit reads in the
expected cells, it strips the leading whitespace, which again breaks text
comparison. For now, I check indentation in unit tests and general order of
the lines in Fit.
May 17, 2006
Added the IntelliJ logo on the website, at the request of JetBrains. They asked for it as a small favor and I like IntelliJ so much that it was a no-brainer to put it up. I really think it's the best Java IDE around at this time.
Started working on text representation of Cycle.
May 13, 2006
Added Structure 101 to the Resources page. I think this might be the latest incarnation of reView. Both come from the same company and reView is no longer on their website.
May 12, 2006
Use specialized collections in com.jeantessier.dependency.Cycle and related
classes.
Added acceptance tests and code to pass a SelectionCriteria to
CycleDetector so I can use scope specifiers when looking for cycles.
May 10, 2006
More Fit tests to show how closures behave in the presence of a stop condition.
May 06, 2006
Created initial acceptance tests for dependency closures.
My license for InteliJ IDEA will expire soon. I must renew it. I hope they still give out free licenses to open source projects.
May 04, 2006
Someone complained that the behavior of the closure engine was not intuitive. I think I will write some acceptance tests to nail down the current behavior and consider some of the improvements they suggested.
April 20, 2006
Added character count and word count for method names. I added all the word
and character count measurements to the default OOMetrics configuration.
April 19, 2006
The online documentation of the Ant tasks had fallen behind. I updated it to version 1.1.1.
April 18, 2006
Reduced the scope for version 1.1.2 so I can get it out the door sooner, and maybe even soon.
April 17, 2006
Started working on WordCounter to count the number of words in identifiers,
including package names. Adjusted MetricsFactory to use it in computing the
number of words in package and class names. I still need to deal with method
names.
I might have to start creating metrics for individual fields. That might be quite a bit of work.
Cleaned up MaximumCapacityPatternCache and its tests to remove unused imports
and use specialized version of collections.
April 13, 2006
Fixed JUnit run scripts to have correct FitLibrary in their CLASSPATH.
April 11, 2006
Upgraded the following development components:
IntelliJ IDEA : 5.1 -> 5.1.1
April 07, 2006
Finished converting all my development environments to Subversion.
Fixed TestDirectoryExplorer to use dedicated temporary files instead of some
arbitrary folder within the project. The tests would break everytime that
folder would gain or lose files. With the switch to Subversion, there was an
explosion of ancillary files that finally decided me to do something about this
test.
April 05, 2006
Got FitLibrary's FolderRunner to run under JUnit.
Tried Subversion for version control. With TortoiseSVN, a Windows Explorer plug-in, I can checkout the project just fine. With the official, command-line client, it kept dropping the connection. I tried the integration in IntelliJ and SmartSVN, but they were having difficulties too. Strange, and annoying. Now, I wonder if I wouldn't be better staying with CVS.
Moved Fit test images to files folder so FolderRunner can copy it to the
reports folder.
April 04, 2006
SourceForge's CVS is back online. Time to merge the development lines I've been taking on three different computers.
Worked on the name character count and word count for packages and classes.
Upgraded the following development components:
Fit : 1.1 -> none FitLibrary : 15Feb2005 -> 20060116
April 03, 2006
Use specialized collections in com.jeantessier.metrics.
Worked on MetricsGathererFixture, trying to find a good way to represent
metrics in a fixture.
I tried to use FitLibraryRunner20060110, which seems to be the latest version
of FitLibrary, but it eludes me. DoFixture has changed package. The HTML
pages now use CSS to manage colors and state and it seems I have to copy the
stylesheet myself between the folder with the input files and the folder with
the output files. And apparently, DoFixture now works differently, because
I can many complaints about methods not being found, whereas it used to find
them just fine using introspection on my classes.
I tried FitLibraryRunner20060110 because there was an incompatibility between FitLibraryForFit15Feb2005 and the latest fit-java-1.1. I was able to do a small change to FitLibrary and recompile it against Fit 1.1, but I'm not sure how the versioning of FitLibrary works. The new FitLibraryRunner20060110 has all the Fit classes inside of it, so I only need one JAR file. But it seems some of the semantics have changed along the way and I haven't seen any documentation so far. I'll have to dig some more.
March 31, 2006
SourceForge's CVS repository was down yesterday and today.
I signed up for a migration to Subversion. I have been heading some good about
it and it looks like the switch is easy. Even though SourecForge's CVS is
down, they were able to migrate my project and I could browse it using ViewVC.
But when I tried to check it out, it failed. IntelliJ did not report any
error, but didn't create the project either and the checkout only had website
and was missing DependencyFinder. I tried with SmartSVN, but didn't get any
further, except that it complained about a bad socket read at some point.
Maybe if I have them migrate it again, after CVS is operational again, it will
work better. Subversion would be nice: it has atomic checkins and it knows
about folders, so you can move or rename parts of the filesystem and retain the
history.
Started working on Fit tests for metrics for identifier length. I want to compute the length of package names, class names, and method names, both in number of characters and number of words.
March 30, 2006
I want to add metrics to find long identifiers. I could have length, in characters, of class names, package names, and feature names. With some clever parsing, I could also compute length in number of words.
Modified code using ClassfileLoader and CommandLine to use the generics
version of Collection classes so they can use the new for() loop to iterate
over collections.
March 27, 2006
Created a Fit test to try to capture the dependency cycle in the Visitor
pattern. Adjusted CycleDetector to drill down packages and classes in its
search for cycles.
Added CycleComparator to order cycles within a detector to ease testing.
Short cycles come before long ones. Cycles of the same length are ordered
according to the lexical ordering of the nodes in their path.
March 26, 2006
Augmented CycleDetector to detect cycles at the class level.
Added Fit tests for cycles at the class or feature levels. Next, I will need to look for cycles that span levels, like in the Visitor pattern.
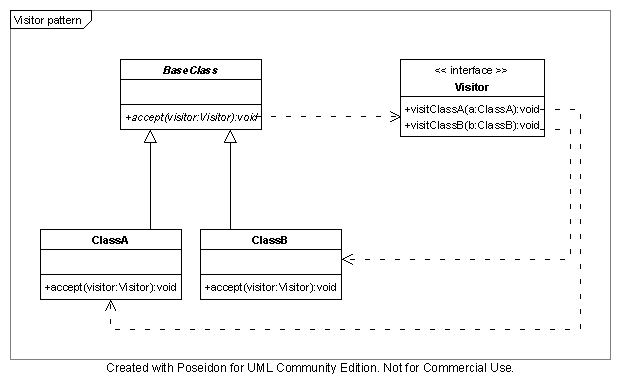
BaseClass
accept(Visitor)
--> Visitor
ClassA
--> BaseClass
accept(Visitor)
--> Visitor
--> Visitor.visitClassA(ClassA)
ClassB
--> BaseClass
accept(Visitor)
--> Visitor
--> Visitor.visitClassB(ClassB)
Visitor
visitClassA(ClassA)
--> ClassA
visitClassB(ClassB)
--> ClassB
These cycles go from some feature to a class and continues through the features
of that class. For this to work, CycleDetector would have to look at lower
levels when seeking cycles from a node. It would have to drill down from
PackageNode to ClassNode and from ClassNode to FeatureNode as
appropriate.
I also fixed the image links in the Journal. Since I switched to a CGI script,
the URL is no longer a prefix of the images/ folder where the images are.
Links to images must now be prefixed with .
March 25, 2006
Added Fit tests to the all tests suite. I don't know why I had not done it before.
March 23, 2006
I figured out how to test each individual path for cycles in Fit tests.
Added more tests.
March 22, 2006
Created a Fit test for detecting dependency cycles. I think I got the basis
for a simple fixture to trigger the CycleDetector. But I still need to work
on verifying the cycles it detected.
March 14, 2006
Wrote a little more explanation around Perl regular expressions in the Manual.
March 13, 2006
Added new experimental "Related links" banner from Google to selected pages on the website. It does not pay like Google's AdSense, but it might provide useful links to people who visit the site. I added it to the following pages to start with:
- Introduction (between main text and quotes)
- Resources (at the top)
- Journal (at the top)
I also added a copy of the open source license for Dependency Finder on the website. Someone was inquiring and they couldn't find it on the web. It has always been included in the distributions, but it can't hurt to have it posted visibly too.
Upgraded the following development components:
JUnit : 3.8.1 -> 3.8.2
March 11, 2006
Fixed ModifiedOnlyDispatcher to only ignore .class files and delegate
everything else, including JAR and ZIP files. This fixes the problem I had
been having when pointing the webapp to a collection of JARs instead of
unbundled .class files.
March 10, 2006
A user was asking questions about Monitor and how to reload a graph and pick
up new classes. I augmented the Developer Guide to describe how you would use
a Monitor and a ModifiedOnlyDispatcher with a ClassfileLoader to support
reloading the graph and picking up changes.
As I was writing this, I realized that the monitor and the dispatcher are not linked to one another. This means that if the dispatcher decides to ignore a JAR file that hasn't changed, the monitor will not know about the classes in it and will remove them from the graph if it uses closed sessions.
I had experienced this behavior before, when using the webapp with a collection
of JAR files instead of the loose .class files I was used to. I'm thinking
that if I let the dispatcher travers collections of classes, like JAR or ZIP
files, it would let the monitor know about all the .class files and the
monitor would not remove them from the graph. That's already what
ModifiedOnlyDispatcher does with directories.
March 06, 2006
Augmented DependencyMetrics to report the number of confirmed packages,
classes, and features in the graph.
A friend of mine brought Structure 101 to my attention. They have a really nice user interface. Maybe some day I'll have something just as nice.
March 03, 2006
Wrote a long Fit test to check name, length, and index calculation for every instruction in the VM's instruction set.
I fixed a misspelling of dup_x2 (0x5B) and the reserved opcode breakpoint
(0xCA).
I also added the new Java 1.5 instruction invokedynamic (0xBA).
March 02, 2006
Updated dependencies.dtd on the website. It appears I had forgotten to do so
when I released 1.1.1.
March 01, 2006
Tied Instruction more closely to Code_attribute so that some of the
instruction processing could be centralized there. Instruction is now a
Visitable and VisitorBase automatically traverses them when processing a
Code_attribute. So I was able to pull the code for iterating over bytecode
from the various visitors into the abstract base class. Also, now that
individual Instruction instances know about their corresponding
Code_attribute and its Classfile and its ConstantPool, those that
represent opcodes with indices into the constant pool can retrieve the correct
ConstantPoolEntry themselves, instead of relying on client code to do it.
These two changes together simplified greatly the various operations that walk
the bytecode.
Instruction knows whether or not it holds an index into the constant pool.
For now, I simply used the list from CodeDependencyCollector, but I will need
to take a close look at the entire instruction set to make sure I have a
complete solution.
I also take this knowledge into account when comparing instructions in
Instruction.equals() and in computing Instruction.hashCode(). If the
instruction actually refers to a ConstantPoolEntry, equals() and
hashCode() will use the entry's equals() and hashCode() as part of their
computation. Otherwise, they just do a byte-to-byte comparison of the
instruction's data.
With these new tools, I revisited the case a user had brought to my attention
on 2006-02-21. At the time, JarJarDiff only did byte-to-byte comparison
when checking for code changes in methods. The user complained that they had
changed only one method but JarJarDiff was flagging them all as different
after a recompile. It turns out the constant pool was reordered between the two
compilations, resulting in different indices and therefore different bytes in
the bytecode. Now, instructions are isolated from any shuffling in the constant
pool, so I expect that only the modified method will show up in the JarJarDiff
report.
There were three. One was the method that had been modified, it had extra
instructions. I was able to run ClassReader on the classes to compare
the actual instructions for the other two. In both cases, the reordering of
the constant pool had pushed the index of a reference beyond 255 and required
an ldc_w instruction of 3 bytes instead of a simple ldc instruction of 2
bytes. I could introduce special treatment to equate ldc with ldc_w, but
I feel this could lead to fairly convoluted comparison rules.
February 28, 2006
Cleaned up some dead or duplicated code.
February 26, 2006
Upgraded my wireless LAN from 802.11b to 802.11g. Larger bandwidth and somehow a larger range too.
February 24, 2006
Changed CodeDifferenceStrategy to compare instructions instead of the raw
bytes. The next step will be to make instruction comparison smarter.
Also added Hex.toString(byte[]) to make it easy to log byte arrays.
Previously, Hex could only write to OutputStream or Writer, which
forced traces to write bytecode to a StringWriter in order to log it. Now,
Hex uses a StringBuffer instead, which should speed things up a bit.
February 23, 2006
Played a little with smarter code difference determination, using the
CodeIterator and Instruction classes. Instruction is not tied to its
Classfile, so it cannot access the constant pool and lookup indices in the
bytecode. I will have to tie it tighter to the object tree if I want it to
compare the actual parameter to an instruction when deciding if something is
different or not.
I found something interesting. In the compiled code I received from a user
yesterday, there is and ldc_w instruction that points to a
CONSTANT_class entry in the constant pool. Now,
the spec clearly says
it has to point to a either an int, a float, or a string. I wonder if
maybe they used a non-compliant compiler or something.
Instrumented more debug info in the processing of bytecode from methods, when
reading it and when comparing it in JarJarDiff.
Did a massive refactoring to use the new Java 5 for() loop in
com.jeantessier.classreader, which meant using specialized versions of the
Collections API. I'm not madly in love with generics, but the new for() is
really cool.
February 22, 2006
A user complained that JarJarDiff flagged all methods as having code changes
when only one methods had changed. They sent me the classes so I could
investigate.
I took a quick look. The constant pool is different for the two classes. The
compiler didn't put the entries at the same offset in each case. The bytecode
makes heavy use of references to the constant pool, so the indices in the
bytecode are different because the offsets in the constant pool are different.
The way JarJarDiff looks for differences in the bytecode is a simple
byte-to-byte comparison; it doesn't interpret the bytecode to see if they are
the same instructions with the same parameters. It just compares the byte
arrays for each corresponding method together and makes the method as having
changed if any single byte is different.
I could probably make it a lot smarter, but that would mean it would have to analyze the bytecode and understand each instruction and its parameters and compare entries in the constant pool to see that they are the same even though they have different offsets. That could take a while, as there are many instructions. I have other tasks that I must finish first before I can think of tackling this one.
If this is critical for you, I might reconsider... Code-level differences is a new feature and I wouldn't want it to start in a useless state. At the same time, I'd like to ship at some point, so if this is not critical, maybe it can wait a future point release. I guess I'll sleep on it for a while...
February 18, 2006
Fixed default value for level in the Ant version of JarJarDiff. Somebody
brought to my attention that it wasn't initialized and caused a
NullPointerException if you didn't specify it in the <jarjardiff>
tag. I also fixed its documentation.
February 15, 2006
Fixed typos in Manual around examples for extracting with the CLI.
February 05, 2006
Cleaned up ExtractAction.
February 04, 2006
Tested actual extraction in new WebWork-based ExtractAction.
January 29, 2006
Dependency Finder is now five years old.
January 27, 2006
I have been wondering how to replicate the current behavior of extract.jsp
under WebWork. A WebWork action
terminates before the JSP tied to its result is even started. The action has
no way to stream data that would end up embedded in the result, the way
extract.jsp streams parsing information to keep the user notified of its
progress.
But I found that the JSP can use the <ww:action> tag to invoke another
action while the JSP is rendered. Maybe I can use this to have a dummy action
launch the extract.jsp and from within it, call the real action that extracts
the graph and stream progress to the output stream.
January 24, 2006
Added a new XSL stylesheet, DiffToFullyQualifiedNames.xsl, to extract symbols
from diff reports generated by JarJarDiff. Someone suggested that they could
use these symbols to start an upstream closure to find which tests would
possibly exercise the modified code. Apparently, their suites take a very
long time to run and this would allow them to quickly run some regression to
see that they haven't broken anything. Sounds interesting, I'm curious to
see how it turns out.
I added start-includes-list and stop-includes-list switches to
DependencyClosure, similar to scope-includes-list on DependencyReporter.
This way, DependencyClosure can work from an explicit set of symbols instead
of regular expressions. In the process, I had to do quite a bit of code
duplication between the two CLI tools, which I don't like very much.
JarJarDiff currently only lists the names of removed/new packages, classes,
and interfaces, without any of their internal details. For this trick to
work, maybe it would help if it listed all the classes and features in a
removed package.
There was already a ListFullyQualifiedNames that operated on dependency
graphs. I renamed it DependencyGraphToFullyQualifiedNames to align it with
the new DiffToFullyQualifiedNames.
January 19, 2006
Edited the Developer Guide to clarify the source of dependency events and how Dependency Finder removes duplicates.
Incremented the date in the copyright to 2006.
Started writing tests for ExtractAction. The WebWork people did a great job
of encapsulating things to make it easy to test. Kudos to them.
January 18, 2006
Started redoing the webapp using WebWork.
Added the following development components:
WebWork : none -> 2.2
January 11, 2006
Played a bit with WebWork. I have been toying with the idea of rewriting the webapp using WebWork, but since it is merging with Struts now, I'm not so sure anymore. I don't want the webapp to bloat just because it needs a whole bunch of infrastructure JARs. Already, the default type of WebWork webapp requires 1MB of JARs before you've even started doing anything.
Upgraded the following development components:
Tomcat : 5.5.12 -> 5.5.15
January 09, 2006
Built a CGI script to rebuild the Journal from the individual text entries. I had to do a fair bit of scrubbing of the text files.
January 05, 2006
Studied the impact of logging a little further. If I remove all
logging in CodeDependencyCollector, I can save about 15%.
Worked at breaking down the Journal into individual wiki-like files. The large, single file HTML was becoming too unwieldy. IntelliJ IDEA was stalling every time I opened a new tag. With the wiki-like notation, it will make writing entries a little easier since I won't have to type all those HTML tags anymore. I still need to figure out how to rebuild the HTML file from the individual pieces.
January 04, 2006
Took another look at the impact of logging. When analyzing Dependency
Finder itself with all logging turned on, some of the lines from
VisitorBase are over 300 KB long! But these logging calls are
guarded by calls to Logger.isDebugEnabled(), so those 300K lines
usually aren't generated.
January 03, 2006
Cleaned up build.xml.
December 30, 2005
Making the switch to Java 5.0. If you're still running it with the JDK 1.4, let me know ASAP.
Trying to compile for Java 1.4 with the 1.5 compiler is just too risky. It catches uses of the new language constructs, but not uses of new API elements. Relying on the compiler to keep me straight is just not reliable. And I'm tired of keeping multiple versions of the JDK just so I can compile Dependency Finder in near-obsolete technology.
Removed JARs for Xalan. I'll rely on the version what ships with
the JDK. It means that dependencies shift from org.apache
packages to com.sun.org.apache packages, which seems a
little fishy, especially since some of those have internal
in their name. I'll have to read some more documentation about how
we're supposed to use those XSL-related classes. On the plus side, I
can now use the default XMLReaderFactory.createXMLReader()
method instead of hard-coding the Apache implementation.
Upgraded the following development components:
Xalan : 2.6.0 -> none
December 18, 2005
Fixed the Manual section on JarJarDiff.
December 17, 2005
Fixed the Manual section on JarJarDiff.
December 16, 2005
Cleaned up build.xml. I had been running the tests
from my IDE for too long and some of the targets had gotten broken.
December 15, 2005
Finally settled to a format for my Fit tests. I got rid of my early experimentations and kept only the most comprehensive ones. I also posted a suggestion for a fix to FitLibrary to bring it in line with Fit 1.1. We'll see how that goes and if it gets incorporated.
Upgraded the following development components:
Log4J : 1.2.8 -> 1.2.13
December 14, 2005
Augmenting the Developer Guide to incorporate the extra explanations
from yesterday's email. I also want to explain how
com.jeantessier.dependency.VisitorBase uses multiple
cases of the Template pattern to present a generic graph traversal
mechanism with multiple extension points. And I do mean
multiple.
December 13, 2005
Sent a long email to a user who was asking how to use the classes in the Dependency Finder library to extract dependencies and how to operate on the graph. I should work that into the Developer Guide.
December 12, 2005
Tech docs around the event-based processing when loading a
.class file using a ClassfileLoader.
Enhanced NodeFactoryFixture so I can test both inbound
and outbound dependencies in a single Fit table.
December 11, 2005
Tech docs to describe the ClassfileLoader hierarchy.
Came up with a new subclass of DoFixture to help me
test dependency graphs as part of Fit tables.
December 07, 2005
Got a bunch of questions from a user on how to use the various
classes in the Dependency Finder library to process .class
files and generate dependency graphs ready for further processing.
December 06, 2005
I finally figured out why Fit behaved differently between my desktop
and my laptop. It turns out they had a different version of Fit. I
must have downloaded Fit 1.0 to my laptop by accident. Anyway, I
tried diff'ing the fit.jar and noticed they were
different. I followed up with a quick run of JarJarDiff, just to be
sure, and there it was, lots of signature and code changes. I copied
Fit from my desktop back onto my laptop and voilà! it
now works like a charm.
Also wrangled DoFixture into doing what I wanted it to
do. It works great for dealing with simple values. Now, I need to
figure out how to call Node.addDependency() and pass
Node values from the Fit tables. I guess I will need one
of those fabled TypeAdapter.
December 05, 2005
Wrote Fit tests using fit.DoFixture so I don't need to
write custom fixture classes. The book and the documentation are a
little sketchy and I need quite a few trial and errors to get it to do
what I want. Or, at least, almost what I want.
Fit still behaves differently between my desktop and my laptop. I am still baffled.
December 01, 2005
Wrote FitTestSuite and FitTest to run Fit
tests with JUnit. I got it to automatically pickup HTML files in a
given folder and to have tests fail when there are failures in one of
the tables in an HTML document. Now, I can subclass
FitTestSuite and give it a folder name in
suite() to have it process a given folder.
Fit automatically compacts phrases like is confirmed into
camel-case identifiers like isConfirmed. It works on my
desktop but not on my laptop. The Fit version is the same, pretty much
everything is the same. Maybe the JVM patch version is different, but
that's it. I am baffled.
November 28, 2005
Started writing Fit tests for creating dependency graphs. I hope that using tables to create test setup will be easier. I still have to figure out how to run them automatically using Ant.
November 27, 2005
Started reading about the Fit testing framework.
November 19, 2005
Refactored the code to instantiate the strategy in
JarJarDiff into private utility methods. This helps
clean up the main code.
Also cleaned up some of the JSPs in the webapp. Now, both
extract.jsp and load.jsp highlight missing
files.
November 17, 2005
For now, I'll treat typed arrays as independent classes. We'll see how it goes.
Continued work on the circular dependency detector. Dealt with comparing and ordering cycles.
November 16, 2005
Added a maximum cycle length to CycleDetector.
Healed tests for
com.jeantessier.dependency.TestHTMLPrinter. It had been
a while since all the tests ran green.
In Java 5.0, some code compiles to strange forms. Enums have an
implicit values() method that attempts to copy the
internal array of the enum's values. It does this copying by calling
the array's clone() method, but the array is typed with
the enum's type, so it looks like a call to
MyEnum[].clone() and I can't seem to decide what kind of
dependency that is. I need to investigate further.
November 15, 2005
Started a new com.jeantessier.dependency.Visitor to look for cycles in the
dependency graph. It seems that many people out there who are interested in
dependencies really want to detect cycles. I still think that not all cycles
are necessarily bad, but maybe at least listing them can be of some use. You
definitely want to avoid circular dependencies between large-scale components,
but one component might be implemented as many, tightly coupled, packages.
Since Dependency Finder is not aware of organizing principles beyond the
package, it's usefulness at detecting unwanted cycles will be limited.
Further refined the webapp's style.css.
Posted Dependency Finder on Google Base.
November 14, 2005
Experimented with the webapp's style.css so hyperlinks
don't stand out too much.
November 09, 2005
Fixed ClassReport so it does not show modified
declarations for classes whose declaration has not changed, according
to the strategy in use.
November 07, 2005
Merged the published_API branch back into the trunk.
Fixed file count based tests.
November 06, 2005
Fixed interaction between DifferencesStrategy and its
DifferenceStrategy so we can overlook class differences
when the strategy dictates that we do. This is to support the case when
a class has a backwards compatible change to its declaration but some
of its features have non-backwards compatible changes. I still want to
report the feature changes, but I want to ignore the class declaration
difference.
November 03, 2005
Fixed JarJarDiff so the -level switch that takes a possible class name can
look for a constructor that takes a DifferenceStrategy before it falls back
on the default constructor. This way, users can specify strategies that extend
DifferenceStrategyDecorator and have them decorate the same basic strategy
that APIDifferenceStrategy and IncompatibleDifferenceStrategy do.
I want to do the same thing for printers, too.
JUnit launch scripts for Unix. I have had the Windows .bat files since
forever, but only got around to writing Unix equivalents last year. I finally
checked them in.
November 02, 2005
Last tests for IncompatibleDifferenceStrategy.
November 01, 2005
More tests for IncompatibleDifferenceStrategy. I am
done with class-level tests and starting field-level tests. Then, I
will have to do constructor and method level tests. It's gonna be a
while, still.
October 30, 2005
More tests for IncompatibleDifferenceStrategy. I had a
little bout of analysis paralysis, but I think I'm out of it now.
October 28, 2005
Refactored of tests for
IncompatibleDifferenceStrategy. Not done yet.
October 25, 2005
Reworked the entire DifferenceStrategy hierarchy. For
a short time, I considered using a chain of responsibility pattern,
but setting it up in a flexible way, from the command-line, was just
too complicated. So I will stay with decorators and some limited
combinations, based on command-line parameters.
October 19, 2005
I'm going to make IncompatibleDifferenceStrategy a
subclass of DifferenceStrategyDecorator.
I read that JDK 1.5 has JMX instrumentation to help with profiling. I should look further into it to help with performance issues with regard to logging.
October 15, 2005
More test data and initial tests for
IncompatibleDifferenceStrategy.
October 14, 2005
More test data and new IncompatibleDifferenceStrategy
to replace PublishedDiffToHTML.xsl.
October 13, 2005
Created some more test data to test the new
DifferenceStrategy to replace
PublishedDiffToHTML.xsl.
October 12, 2005
Reworked the way DifferencesFactory determines code
differences. It is now all done by the strategy and the factory only
sets a flag in the appropriate CodeDifferences instance.
I had to adjust DifferenceStrategy in order to expose
isCodeDifference(). I eventually would like for constant
value and code differences to have their own instance of
Differences instead of just being flags. Objects can
hold information about the nature of the difference.
I had an idea of using a chain of command pattern instead of my
current strategy pattern for DifferencesFactory, but that
would make it much more complicated to insert user-defined strategies.
So I'll stick with my current design for now.
October 11, 2005
Removed obsolete method Differences.isEmpty().
October 09, 2005
Got rid of the Validator hierarchy. The only one that
was used at all was ListBasedValidator which I turned into
a decorator for DifferenceStrategy. The resulting design
is much cleaner and it makes DifferencesFactory that much
simpler. One last strategy for backward-compatibility-breaking changes
and I'll be done with this development item.
October 04, 2005
Changed all the JarJarDiff variations to use the new
DifferenceStrategy. Each has a new level
parameter to tell it which strategy to use. Level can either be a
predefined constant, api for
APIOnlyDifferenceStrategy or code for
ComprehensiveDifferenceStrategy. In addition, users can
set it to the name of a class that implements
DifferenceStrategy and that has a default constructor;
the program will instantiate it and use the instance to analyze
API differences. I might so the same thing for the selection of
printers in many of the tools.
October 03, 2005
Finished APIOnlyDifferenceStrategy. Now, I need a
switch in JarJarDiff to select the strategy at runtime.
October 02, 2005
Introduced APIOnlyDifferenceStrategy to compute API
differences without regard for code-only variations. I also want it to
not show the value of constants, but that will require more tweaking.
At least, I now have tests in place.
September 29, 2005
Tracking value differences for constants via their declaration is too sensitive. I will want cases where I only look at changes that could break backward compatibility and these will show up. I'm back to finding a way to distinguish declaration changes separately from value changes.
I'm seriously considering simply switching to Java 1.5. It will let
me use all the features from the library and also some of the new
enhancements in the language, notably the new for() loop
for iterating over a collection. At a place I used to work, we wrote
software that customers would run as part of their operation. Some
customers were still using Java 1.3, so our build environment was
limited to 1.3 on purpose so we could detect any change that would not
be compatible with 1.3. In order to run Dependency Finder reports as
part of the build, it had to run under 1.3. I figured there might be
other installations with similar constraints, so it would be nice if
they could still benefit from Dependency Finder and I have kept it at
Java 1.3 ever since. But it is starting to hurt, and I don't care
quite as much anymore. Java 1.3 is approaching retirement, so it
should be safe to move up to Java 1.4. But Java 1.5 is even better and
it has been out for a while now. Surely anybody serious about Java
development has moved to it by now!
If you're using Dependency Finder in an environment that requires Java 1.4, let me know. Otherwise, I'm just going to move up to Java 1.5 and ease my own suffering. :-)
September 28, 2005
Implemented equals() and hashCode() in subclasses of ConstantPoolEntry to
help in discovering API differences. It started with the need to compare
constant values to detect when they change between versions. Since those make
up the majority of this hierarchy, I decided to do it all.
One interesting point is when comparing two values of either Float_info or
Double_info, where I need to compare float or double values respectively.
I cannot use operator ==== because rounding errors could make it fail when the
values are otherwise the same. Since Java 1.4, I can use
Float.compare(float, float) and Double.compare(double, double), but not in
Java 1.3. So far, my policy has been to keep the code runnable on a Java 1.3
virtual machine. I used to do it by compiling the release version with JDK 1.3,
but as of 2004-06-18, I use the source and target attributes to the
<javac> Ant task in build.xml. This way, I only need JDK 1.5 on my
machine. But this control mechanism does not guard against calling features
that were not in JDK 1.3, like those compare() methods. The compiler compiles
them just fine, and the code runs fine until JarJarDiff hits a float or double
constant that didn't change and it tries to call my new equals() method to
verify it. It then explodes with a NoSuchMethodError for either
Float.compare(float, float) or Double.compare(double, double).
September 26, 2005
Introduced DifferencesStrategy and started using it in
DifferencesFactory. In the process, I noticed that I
never modified FieldDifferences to take into account the
change in value for constants. I fixed it, but I'll have to also fix
ClassReport and the XSL stylesheet in
DiffToHTML.xsl.
September 23, 2005
Upgraded the following development components:
Tomcat : 5.5.9 -> 5.5.12
September 22, 2005
Started using PackageMapper in
DifferencesFactory.
September 20, 2005
Created PackageMapper to have one place where a
collection of classfiles get mapped to packages. Reworked its use into
ComprehensiveDifferencesStrategy.
September 12, 2005
Renamed JarDifferences to
ProjectDifferences, since it deals with the entire project
and not any single JAR file.
Finished ComprehensiveDifferenceStrategy. Now I have
to use it in DifferencesFactory.
September 11, 2005
Continued work on DifferenceStrategy to encapsulate the
behavior behind Differences.isEmpty(). Got through the
tests for packages. Now, I need to handle entire projects and create a
subclass for backward-compatibility breaking changes.
September 09, 2005
Continued work on DifferenceStrategy to encapsulate the
behavior behind Differences.isEmpty(). Got through the
tests for classes and interfaces.
It turns out that constants have their value embedded directly into their field entry. I adjusted the new difference engine to look at those values too (the old one was ignoring them).
September 08, 2005
Started work on DifferenceStrategy to encapsulate the
behavior behind Differences.isEmpty(). Got through the
simple tests for fields, constructors, and methods.
Ran a quick test with a large JAR file: removing all calls to Log4J reduces extraction time by 50%. I should look into more discretionary use of logging to make the application more responsive, specially for large codebases.
September 07, 2005
After staring at the code for some time, I am finally convinced the
various subclasses of Differences each expose enough
information that I can come up with a strategy object that can look at
each one and determine if it is empty or not. At first, I had
thought of using a visitor, but that would mean either changing the
Visitor interface to have a return value, or make the
visitors stateful. Neither is appealing to me, so I'll stick with my
idea of using the Strategy pattern instead.
Fixed RemovableDifferences that was directly
referencing fields internally instead of going though accessors. Since
the places it was doing the accessing will move to a strategy, it made
sense to go through an accessor instead so the calling code will be
easier to move later on.
September 05, 2005
I am stuck. On two fronts. With JarJarDiff, I can't seem to see a way to insert some kind of strategy in the difference engine to choose between all differences and only those I judge might break backward compatibility. With the HTML-ization of the web app output, I can't seem to find a clean way to go from preformatted text output to hyperlinked HTML. This is frustrating.
September 01, 2005
Fixed a typo in the manual.
August 25, 2005
Tried to create an HTMLPrinter for the webapp so
dependencies can be hyperlinks to further queries. Right now, it is
just a quick hack. It will need more work to make it pretty and
generic enough.
August 24, 2005
Turns out my manual tests for JarJarDiff's filtering
were using the wrong filter files. I am glad to report that the
filtering function is working just fine. And now, I have tests to
prove it.
Upgraded the following development components:
IntelliJ IDEA : 5.0 -> 5.0.1
August 22, 2005
Toyed with the idea of removing deprecation-related entries from
JarJarDiff reports, in addition to the
documentation-related ones I removed two days ago. In the end, I
decided to keep them since they impact the compilation messages you get
when building code.
Further modified JarJarDiff to use
Validator as a filter instead of the two documentation
parameters it had before. Now, it uses a new
ComprehensiveValidator by default but if supplied with
the -filter switch, it uses a
ListBaSedValidator instead to limit the report to
selected elements. I have to modify ListBaSedValidator to
throw an exception when its input file is missing. I am not finished
yet. There are no tests for filtering and when I pass in the switch,
the resulting report is empty. This shouldn't take too long to sort
out.
August 21, 2005
For some obscure reason, my laptop won't let me start SmartCVS anymore. It complains that I don't have Java 1.4 or later installed. I have JDK 1.5! I tried everything, up to and including uninstalling both SmartCVS and JDK and reinstalling them, to no avail. I figured I'd use the CVS support in IntelliJ IDEA, but the branch only exists on the source code and not on the website module, which confused my IDE for a little while.
Upgraded the following development components:
SmartCVS : 4.0.5 -> 4.0.6
August 20, 2005
Started fixing JarJarDiff to remove all the parts that
dealt with the level of documentation as separate entries in the XML
report. The next step will be to use the lists from
-old-validator and -new-validator to trim the
report itself, not with an XSL stylesheet. I will do this work on a
separate branch and merge it in when I'm done. The branch is named
published_API.
Fixed textjunit.bat and junit.bat to allow
for spaces in the JAVA_HOME environment variable.
August 15, 2005
Found more ideas for object-oriented metrics from the works of Kenneth L. Morris. I will have to research it a little further.
August 13, 2005
Thought about my current dilemma regarding what to display in
JarJarDiff reports between entire APIs, published ones
only, and selective display. I thought I could do it with XSL
transformations, but those are becoming too complex. Plus, there is an
issue with using function calls in predicates that I still haven't
resolved. I'm starting to think I'd better generate different reports
from JarJarDiff and have a single stylesheet to render
them in HTML. I might do the same for the stylesheets that narrow
down dependency graphs instead of using
DependencyReporter.
Upgraded the following development components:
JDK : 1.5.0_01 -> 1.5.0_04 IntelliJ IDEA : 4.5 -> 5.0
August 06, 2005
Back from vacation (yeah, it was three weeks).
July 26, 2005
Fixed typos in Manual for UNIX installation instructions.
July 16, 2005
Gone on vacation.
July 13, 2005
Finished support for negative closure.
Checked in a "cleaned up" version of
DependencyGraphToRDF.xsl and associated script.
July 11, 2005
Gave some thoughts to computing negative closures using the tools that are already there. All I really need is a new stylesheet to extract the fully qualified node names from the XML graph without any indentation.
July 06, 2005
I started to reorganize the package
com.jeantessier.dependency (on paper) to separate the
classes that deal exclusively with the graph from those that deal in
terms of dependencies (from those about transitive closures). Maybe
it's not as bad as I think.
Started looking at how Java 5.0 stores some of its more exotic constructs, like variable argument methods and generics. I found some links to the updated JVM specification. I have some work ahead of me. The good news is that its all new special attributes and new access flags, so everything kinds works already. It's just that they are not really accounted for when extracting dependencies or computing metrics.
Moved Hex from package
com.jeantessier.dependencyfinder to package
com.jeantessier.text so classes in other packages can use
it to dump binary data to log files, like Custom_attribute
when logging the content of unknown attributes.
July 05, 2005
Somebody suggested using Dependency Finder to generate data flow
graphs. They asked if inbound dependencies on fields couldn't map to
setting the value and outbound dependencies to reading the value. The
goals are different between dependency graphs and data flow graphs. But
this got me thinking that maybe just having a different collector could
do the trick. The Node class and its related classes are
generic enough to represent any kind of relationships. It is up to the
consumer of the graph to infer meaning from things like "inbound" and
"outbound" nodes.
June 23, 2005
Upgraded the following development components:
Ant : 1.6.2 -> 1.6.5 JDK : 1.4.2 -> 1.5.0 Tomcat : 5.0.28 -> 5.5.9
June 18, 2005
Took one more look at using JDK 1.5 to generate the code for JDK 1.3 instead of JDK 1.3 itself. The differences are very minor, from what I could see. Mostly, it has to do with how JDK 1.3 was resolving method calls to their latest definition, while from JDK 1.4 forward they are resolved to the most specific class of the reference. This has no ill effect on running the code in the JDK 1.3 virtual machine.
June 17, 2005
Worked a little more on SelectedDiffToHTML.
June 16, 2005
A coworker requested that pages from the web app be bookmarkable.
The easy solution is to replace the "method" attribute of
<form> tags in the JSPs. The URLs can get pretty
large. Just the parameter names for advancedquery make it
600 characters long. With web proxies that can truncate URLs at 1K,
that leaves about 400 characters for specifying regular expressions. I
haven't checked it in yet.
June 08, 2005
Added code difference information to the XML reports that come out of JarJarDiff. The XSL stylesheets are giving me trouble. They can't seem to pick up the new XML tags. Strange.
It turns out that my CVS configuration in IDEA missed two test data files the other day. I guess I'll stick to SmartCVS for checkins.
June 06, 2005
Started on computing code differences for methods that have not changed otherwise.
Working with IntelliJ IDEA and all its refactorings is really nice. I still have a little difficulty configuring the project just right, especially with support for JSPs without turning the entire project into a web app.
June 01, 2005
SourceForge stats are back and WOW! they're great. Check it out! Release 1.1.0 got over 1000 downloads and Release 1.1.1 is already past 250 after just two weeks. This is awesome. I'm really happy.
May 29, 2005
Still looking at tracking changes in the bytecode as part of
JarJarDiff report.
A few additional fixes from IDEA's analysis.
May 28, 2005
Started looking at tracking changes in the bytecode as part of
JarJarDiff report.
May 25, 2005
Installed IntelliJ IDEA. Ran the built-in analysis tool and found a few places where signatures included exceptions that were no longer thrown and some unused parameters. I'm used to IDEA on the Mac, so I need to adapt to the key bindings on Windows.
May 24, 2005
Updated the code coverage analyses on the website with runs against Release 1.1.1.
Got my free license for IntelliJ IDEA.
Googled for "Dependency Finder", out of curiosity, and found two interesting hits.
The first one was reView. I had already stumbled on it a while back and I must say the demo on their website was pretty impressive. It has a lot of what I'd want to see in a graphical UI for Dependency Finder. They sell licenses for $1,999 each. Whew! Their brochure has a lot of great arguments for managing dependencies from a financial point of view. And since Dependency Finder is free, it's an even better deal.
The second one was
Hackystat.
This one is a metrics framework that has Dependency Finder as one of
its tools for getting information about a codebase. It is from the
University of Hawaii. They use a dependency graph, which they post-
process, to extract coupling information about programming elements. I
think they might have an easier time collecting their data if they used
OOMetrics instead. I'll have to get in touch with them
and see if see if that is the case.
May 23, 2005
Updated the website with data regarding Release 1.1.1.
Applied for a free license for IntelliJ IDEA as part of their Open Source License program. I may finally move away from Emacs. It does have a lot more refactorings and a lot of smart features. We'll see.
May 18, 2005
Generated some of the data for the Samples regarding Release 1.1.1.
May 17, 2005
Release 1.1.1.
Also found about a new graphics package for rendering graphs: JUNG.
May 12, 2005
Looked at using JDK 1.5 to compile Dependency Finder for the 1.3
runtime. I can use source and target
attributes on the Ant targets, but the .class files are
different from the ones compiled with JDK 1.3. I need to investigate
further to make sure they will run fine with the 1.3 runtime.
May 02, 2005
Tech docs.
Finished release 1.1.1.
Considered merging ClassFinder and
ClassList into a single tool. But in other areas, I have
simple tools that each do one thing only, so I might as well let these
two follow the same pattern.
April 30, 2005
Tech docs.
April 29, 2005
Someone brought Ivy to my attention. It is a package for analyzing dependencies and producing reports with integration into Ant, Maven, Cruise Control, and even Eclipse. I couldn't understand the sample reports on the website, and I don't think it offers the same kind of dynamic interaction capabilities as Dependency Finder. It is good that there is slowly more and more tools to support object-oriented design.
Tech docs.
April 28, 2005
Tech docs.
April 24, 2005
Realized I had mistakenly swapped the current CVSDiff and CVSChangelog reports when I last updated them.
April 19, 2005
Adjusted the JSPs that manage the graph in memory to keep track
of extract, update, and load times separately. This way,
extract.jsp limits itself to extract and update times, as
appropriate, while load.jsp takes care of load times.
April 18, 2005
Dependency Finder: social networking for your code!
Cleared up the documentation regarding the web application and how to get a dependency graph loaded.
Also changed the obscure delta application variable
to the more aptly named duration. It tells how long the
last extraction or loading took. In the case of extracting a graph,
I should probably have separate numbers for the last full extraction
and the last update only.
On my new PC, I can't seem to start Tomcat on port 8080. It keeps complaining that port 8080 is already in use, but I can't figure out by what. I've changed the default config to port 8000 in the meantime and it seems to work just fine.
April 17, 2005
Started working on a new printer for transitive closures. This will
be harder than I thought.
com.jeantessier.dependency.Printer has way too much
machinery geared solely at printing graphs to be useful. I also need
to figure out a way to find the closure's starting point after
the engine has computed it and possibly after the graph has been
reduced possibly as far as package-to-package.
April 14, 2005
Tech docs for closures.
April 12, 2005
Someone is having problems computing closures and finding paths
between components. Can't blame them, the output from
DependencyClosure is very hard to follow.
They claim that in JDK 1.3.1, there is a path from
JTree to Toolkit through
MouseEvent. DependencyClosure found one
through Component and I looked at the source for
MouseEvent from 1.3.1_09 and there is no mention of
Toolkit in there. There is in JDK 1.4 but not in
1.3.
At the time, I didn't have rt.jar handy to repeat the
tests, so I used DependencyFinder.jar instead. At first,
I tried to find a closure from
com.jeantessier.dependencyfinder.cli.DependencyExtractor
to com.jeantessier.commandline.MultipleValuesSwitch. I
thought it called CommandLine.addMultipleValuesSwitch()
and would then find MultipleValuesSwitch from there, but
it doesn't. Of course, DependencyExtractor does not have
multiple value switches, so there is no feature-to-feature path from
it to MultipleValuesSwitch. I will need to document this
situation, in case someone else comes upon it too.
Gave some more thought to a specialized printer for transitive closures.
Finishing the documentation shouldn't take too long. Definitely not long enough to justify having a beta release while we're waiting.
April 10, 2005
Uploaded screenshots to SourceForge.
April 07, 2005
Adjusting wording on the GUI to make it a little more intuitive. Also played with fonts to get something close to Courier in graph displays.
Had a "teachable moment" with a colleague today. I think he finally saw the benefits of using Dependency Finder when dealing with a large, intricate codebase.
I'm going to make a beta release while I finish updating the documentation.
I also need to start working on a new printer for closures. The normal graph printer makes results too hard to read.
April 06, 2005
Talked to a former coworker who is still using
JarJarDiff. He mentioned that having it also report on
methods whose implementation changed without impacting their
signature. This is the same as Request for Enhancement #900448. So
don't despair, it'll come one day.
April 05, 2005
Checked in fix for case where group is a single .class
file.
April 04, 2005
Fixed the ClassfileLoaderEventSource to record the
first dispatch call and use it when dealing with a group of a single
.class file.
April 03, 2005
Wrote a sequence diagram of what happens when you call
ClassfileLoader.load(). This will help me figure out
how to handle the case where processing a group consisting of a single
.class file.
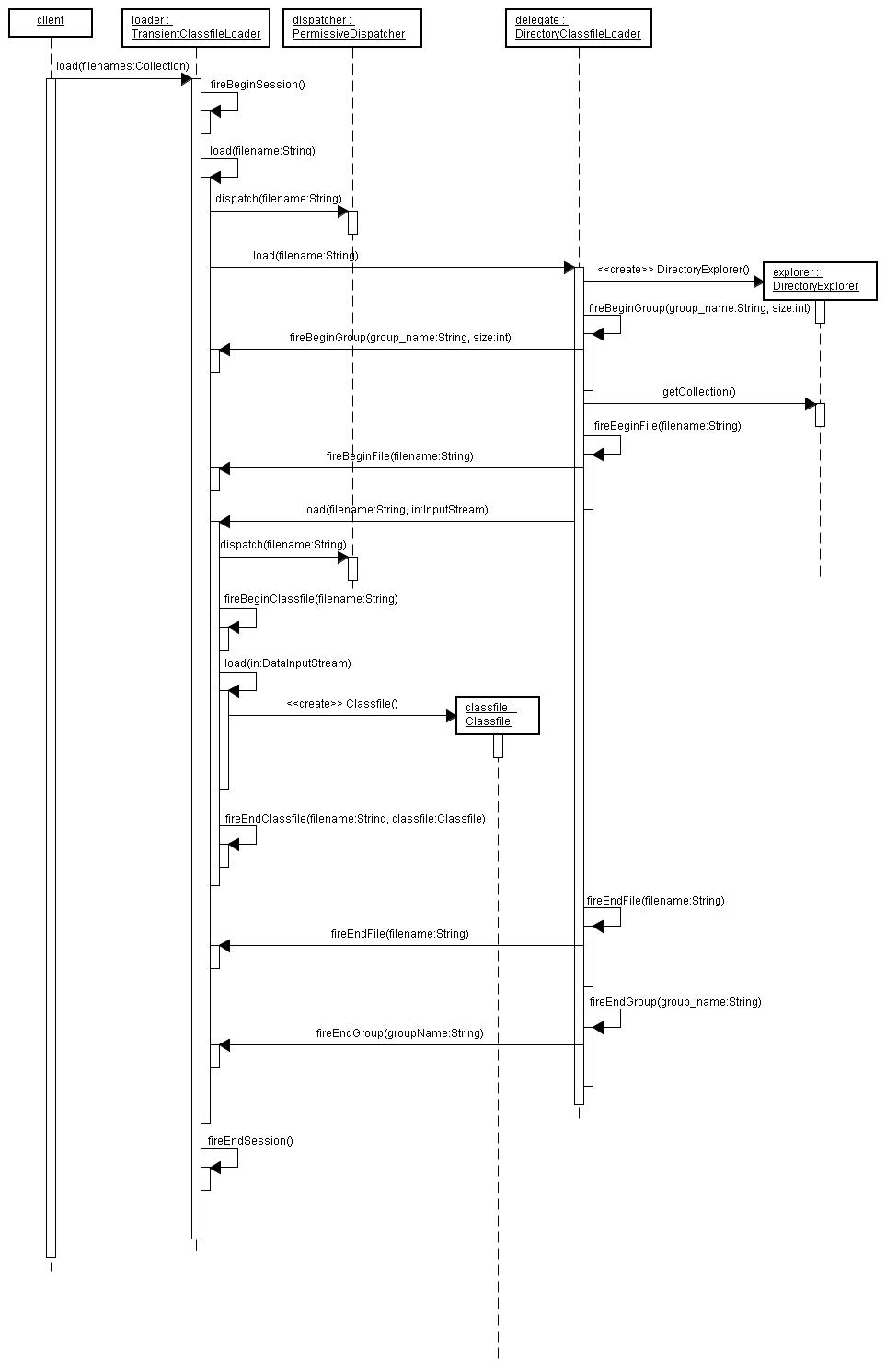
April 02, 2005
Wrote a unit test to replicate the problem with groups of a single
.class file.
March 31, 2005
Found a problem when analyzing individual .class files.
For some reason, the GUI keeps on skipping them. It turns out the
dispatcher gets called twice: once when initiating the group processing
and a second time to deal with the file as part of the group. The
GUI uses a ModifiedOnlyDispatcher, which instructs the
ClassfileLoader to ignore the file after the first time,
so the file is never read. The intricate collaboration between the
various ClassfileLoader subclasses will make this hard to
figure out.
March 30, 2005
There is a problem with DependencyFinder: it ignores
.class files passed in explicitly. Somehow, the
dispatcher seems to think it should ignore the files. This is because
the dispatcher is asked twice about the file: once as a group and once
as an individual file. Since the file hasn't changed between being
looked at as a group and as a single file, the
ModifiedOnlyDispatcher tells the loader to ignore it the
second time around. Maybe ClassfileLoaderDispatcher
needs both a dispatchGroup() method and a
dispatchFile() method instead of the current single
dispatch() method.
March 28, 2005
Looking into setting Font for UI elements in the
GUI.
March 27, 2005
Finished adjusting all the remaining dependency graph-related stylesheets to use the new information about inferred versus confirmed nodes. I took the opportunity to update all the HTML stylesheets to use the CSS styles instead of hard-coded HTML tags.
March 26, 2005
Fixed NodeHandler to use the new confirmed
attribute in the XML description of graphs. In the process, I added
new tests for NodeHandler and NodeLoader,
which will help a little with the code coverage of the test suite.
March 24, 2005
Copied confirmed status when computing transitive closures.
March 22, 2005
Adjusted dependency graph-related stylesheets to use the new information about inferred versus confirmed nodes. More to come.
March 21, 2005
Added support in the dependency graph's TextPrinter and
XMLPrinter to show inferred versus confirmed status of
nodes. I had done most of it during a spike back in January, but I
didn't have any tests for it. Now, I need to fix the DTD and the XSL
transformations. And NodeHandler too.
March 17, 2005
Added windowtitle to <javadoc> target so the Javadocs have a proper
window title when viewed with a browser.
Final clean up for using logoicon.gif.
Since October, I've been struggling for a good term to distinguish nodes in the dependency graph that match elements that were actually extracted versus those that were merely referenced, but not extracted per se. Back on 2004-10-08, I came up with referenced versus concrete. Both are troublesome because they have other accepted meanings in closely related contexts, such as concrete class. Today, I finally came up with a better replacement: unconfirmed references produce inferred nodes until the element is actually extracted, at which point the node gets promoted to confirmed.
Made sure that GraphCopier and GraphSummarizer maintain a node's confirmed
vs. inferred status across graph copies.
March 15, 2005
Finished setting up a favicon.ico for the documentation
and the website.
March 14, 2005
Final checks for switching from TABs to spaces.
March 13, 2005
Switched from using a combination of TABs and spaces for indentation to using spaces only. This way, the code will look the same no matter what is used to view it, especially in SourceForge's ViewCVS.
March 10, 2005
Added a checkbox to extract.jsp to choose between
updating the current graph (using Monitor) or extracting a
new graph from scratch.
Started putting a favicon.ico in the web application
and on the website. I tried to cheat by using
logoicon.gif and using <link> tags in
the HTML. It works fine with Firefox but I couldn't get it to work
with Internet Explorer. I tried to create a .ico file
with some free editor, but I still couldn't get it to work. Maybe it
is a caching problem.
March 09, 2005
Fine tuned spaces in JSPs for the web application.
March 08, 2005
Finished installing Monitor in the GUI. The
Monitor now has a notion of open vs. closed sessions.
An open session keeps accumulating data across load sessions. It never
tries to remove files that were "not visited". A closed session works
like the previous version of Monitor and follows closely
the load sessions, removing classes from files that were not visited in
the latest session.
March 06, 2005
Worked on better integration between Monitor and
DependencyFinder in the GUI.
Someone raised an interesting problem. Say class
MySuperClass defines methods m1() and
m2() where m1() calls m2(),
introducing a dependency m1() --> m2().
Now imagine a subclass SomeSubclass that overrides
m2() and defines a method m0() that calls
m1(). Because m1() depends on
m2(), which is redefined in SomeSubclass,
m0() really depends on SomeSubclass.m2()
and not MySuperclass.m2(). But the dependency graph
does not know about this. It looks at all dependencies from a very
narrow context and does not see the bigger picture. This is
unfortunate, but it will stay that way for the foreseeable future. It
would take a lot of work to have Dependency Finder walk through
the program's logic, almost simulating a program run, and I just don't
have the resources to get into it.
March 04, 2005
Finished revamping of JSPs. I changed the labels around the
controls for showing inbound or outbound dependencies. Instead of
saying "inbounds" and "outbounds", they now show "<--"
and "-->" respectively. Hopefully, this will make it
a little clearer what each one does. I will need to find a way to do
the same in the GUI.
March 03, 2005
Continued revamping of JSPs. Tested using title
attributes to make popup hints; they seem to work great, but the amount
of text I can put in them varies by browser. I'll have to keep it
short and get rid of the sample Perl expressions, I'm afraid.
March 02, 2005
Someone asked how to find which JAR contains a class using
Dependency Finder. I created a new tool, ClassFinder that
uses the group stack from VerboseListenerBase to collect
that information and print it out.
They also asked for the same information for packages.
Found out about using title attributes to make popup
hints in HTML instead of weird Javascript. I'll make it part of the
redesign of the JSP pages.
February 28, 2005
Bad news for Dependency Finder: I just got Half-Life 2! >:-)
February 27, 2005
Bad news for Dependency Finder: I just got Doom 3! >:-)
February 26, 2005
Started to revamp the JSPs in the web application to use
<fieldset> and <legend> tags to
group UI elements, instead of twisted <table>
tags. This is going to take a while and there is way too much
duplication between the JSPs.
February 21, 2005
Fixed DependencyFinder to use the new
Monitor when re-extracting .class file. In
the process, I fixed it so it retains all extracted locations instead
of just the last one, like it used to do. I had to make changes to
many of the action classes, but overall the structure has improved a
little. It still needs more testing.
Adjusted load.jsp to remove the monitor and dispatcher
when loading the graph from XML files.
February 18, 2005
Updated the code coverage reports, both jcoverage and Clover. The last time went all the way back to 2003-07-20. The number have improved a bit but they are still rather laughable. I added the procedure for generating them to the Developer Guide.
Upgraded my testing environment from Clover 1.3_01 to 1.3.4.
February 16, 2005
Fixed build.xml to use <junit> and
<junitreport> tasks to run the unit tests and get a
nice HTML report. It works fine on MacOS, but not on Windows XP, for
some reason. I get an OutOfMemoryError no matter how much
memory I put in ANT_OPTS.
I'm also going to use spaces only for indenting
build.xml. I was using combinations of tabs and spaces,
but it looks very strange in some editors that show tabs as four
spaces. Eventually, I might do the same in Java files, too.
February 13, 2005
Adjusted OpenFileAction so it gets its
NodeFactory from the model instead of creating its own.
This is in preparation to having it use a Monitor
instead.
February 05, 2005
Started to work out how to have DependencyFinder use
the new Monitor. That GUI code is a mess!
February 04, 2005
Compiles and passes all tests with JDK 1.5.0 on Alienware. Compiles in 15 seconds and tests run in 10.203 secs. My laptop, with JDK 1.4.2, would take 31 seconds to compile it and the tests would take 20 secs. to run.
February 03, 2005
Started thinking about reorganizing the build process to compile
everything into a build directory, like many other
projects do. I must investigate further what the current Ant best
practices are like.
February 02, 2005
New hardware: Alienware.
January 29, 2005
Dependency Finder is now four years old.
It turns out the problem with re-extracting graphs had to do with
CodeDependencyCollector not setting concreteness
correctly. That would throw off DeletingVisitor when
rolling back a class during re-extraction. One problem fixed.
Now, I need to get the GUI to use the new Monitor
too.
January 28, 2005
Finally got Monitor to behave properly. But now, it's
the DeletingVisitor that seems to be missing some
dependencies. I extract a graph, change a space in one file,
recompile, and re-extract (just the one file) and all of a sudden, the
graph has different numbers of inbound and outbound dependencies.
Worse, if I remove all .class files and re-extract,
effectively removing the entire graph, I end up with a partial graph
with no outbound dependencies but some inbound ones left. Puzzling
January 26, 2005
Started coding Monitor, but I keep on missing some
aspect of tracking files because the behavior is not quite there
yet.
January 24, 2005
Further design for Monitor (on paper only).
January 22, 2005
Worked on a possible design for an object that could monitor what
files are being read and what classes are in them, so it can roll back
changes to the dependency graph from a class before it is re-read. I
don't have a name for it yet, so I'll just call it Monitor
in the meantime.
January 20, 2005
It's one of those bugs. The moment I put in logging statements, the
ModifiedOnlyDispatcher suddenly starts to work. Well, now
the classfile loader is loading the correct files.
Used ModifiedOnlyDispatcher in
DependencyFinder. But along with
extract.jsp, it does not yet adjust its dependency graph
correctly. I need to make them keep the old graph, remove reloaded
classes, and somehow remove classes that have altogether disappeared.
More work ahead.
January 19, 2005
Tried ModifiedOnlyDispatcher with
extract.jsp. It was a little overeager, skipping
directories without even looking if files in them had changed. So I
modified it to not do anything special with directories and always
delegate to the underlying dispatcher. Somehow, it doesn't seem to
really skip unmodified files, so I'll have to investigate further.
January 18, 2005
Added more tests for DeletingVisitor to make sure that
deleting nodes with inbound dependencies does not remove them from the
graph but only makes them as referenced elements.
Added flags to the web application to control whether or not to
display the source and file parameters on
extract.jsp and load.jsp respectively. This
can help in debugging where a given installation is getting its data
from.
January 17, 2005
Finished te support for removing nodes from the dependency graph.
It turns out the logic was so twisted that I had to resort to using a
visitor in the end. The new class is called
DeletingVisitor. It traverses the graph and removes
specified nodes and cleans up after them.
January 11, 2005
Found a bug in the Unix script for OOMetricsGUI. It
tried to be clever and use a local variable based on the named under
which the script was invoked to determine the class name to start. It
works for all other scripts, but in this case, the class name is
different from the script name. The script OOMetrics
starts com.jeantessier.dependencyfinder.cli.OOMetrics
and the script OOMetricsGUI starts
com.jeantessier.dependencyfinder.gui.OOMetrics.
I fixed the bug and issued patch #1100722.
Fixed the bug using a CVS branch: bug-1100131.
January 08, 2005
The logic to pull out nodes is too complex. I'm getting lost in all the bookkeeping required.
January 06, 2005
Started putting support in NodeFactory to remove nodes.
I still need to handle the dependencies themselves.
January 04, 2005
Stated implementing a ClassfileLoaderDispatcher
decorator to support reloading only .class files that have
changed.
January 03, 2005
Amended the User Manual to have the simpler way of narrowing down an API diff to the subset actually used.
Incremented the date in the copyright to 2005. Incremented the working version number to 1.1.1.
December 30, 2004
Came up with a much better way to narrow down a diff to the API
actually used by some software. I use ListSymbols first
on the library and then use the symbols to extract a subgraph from the
calling software. By using
DependencyReporter -show-empty-nodes, the graph only has
the nodes for used symbols. Converting this subgraph from XML to text
with DependencyGraphToText gives me the subset of symbols
that are used in the software. Pass this shorter list to
PublishedDiffToHTML and that is all there is to it.
December 29, 2004
Finally got around to cleaning up some of the HTML on the website.
The documents say they use HTML 4.01, but I try to follow XHTML as much
as possible. This sometimes yields strange results on some browsers.
For instance, I like to have empty named anchors as
<a name"someName" />= but some browsers won't see
the empty tag but a start tag instead and proceed to underline all text
after it. So I have to write it as
<a name"someName"></a>=. But that doesn't
work for <br> or <hr> because
they do not allow any content and therefore the notations
<br></br> and
<hr></hr> are illegal. For those, I can still
write <br /> or <hr /> because
the browser doesn't expect any content and simply ignores the trailing
/. So my rule has been to write closing tags for elements
that can have content, and the XML empty notation when the elements
cannot have content. That should fix it for most people.
December 28, 2004
Release 1.1.0.
December 22, 2004
Updated CVS diff and change log data.
Generated some CVS statistics using StatCVS.
December 20, 2004
Adjusted tech docs in the User Manual.
Updated version number to 1.1.0. I'm ready for the release.
December 19, 2004
Adjusted tech docs in the User Manual.
December 18, 2004
Reviewed latest additions to the User Manual.
December 16, 2004
Wrote examples of using OOMetrics for tracking usage of
deprecated elements and computing the D' metric in the User Manual.
December 13, 2004
Wrote a section of the User Manual to describe how you can keep
track of usage of deprecated programming elements using
DependencyReporter.
December 12, 2004
Wrote a section of the User Manual to describe how you can limit the API diff report of a third-party library to the subset of that API that you are using in your code.
Found a bug with the CLI scripts. When I generated the template for 1.1.0 beta3, I used an example that lacked the Xerces libraries. This means that all tools that need to read XML couldn't find a proper parser. Since no one has complained yet, I guess they all use the GUI or the Ant tasks. I won't write a patch for this since the official 1.1.0 release is very close and will have the correct scripts.
Had a similar problem with the XSL scripts, but in reverse. Most of
them are straightforward XSL transformations and only require Xalan
JARs. But PublishedDiffToHTML.xsl uses some custom code
and needs Dependency Finder's JARs. I changed the template to include
them all the time, just like the Unix template was doing.
December 11, 2004
Figured out how to detect if a file has changed since it was last
extracted. I'll use the decorator pattern to wrap the
ClassfileLoaderDispatcher of the
ClassfileLoader with a decorator that will remember the
modification date of files and instruct the loader to ignore files that
have not been modified. By using a decorator, I don't have to change
any interfaces and I get to intercept the call to the real dispatcher
before it gets made. Other solutions, like a common super class for
dispatchers, had the problem that the subclass method was being called
first. This would necessitate some kind of communication between the
subclass and its superclass to get the new behavior. A decorator is a
simpler, more elegant solution.
This will not go in the 1.1.0 release, but most likely the very next one.
December 10, 2004
Got an idea for undoing extraction of a single class on the graph. If I can do that, then I can re-extract a single class that I just recompiled and see it's effect on the graph without re-extracting the whole graph. I'm still struggling with detecting if a file has changed since it was last extracted, so I can launch a re-extraction on a whole codebase and have it pick only the files that have changed.
December 09, 2004
Added a section to the User Manual to deal with very large codebase by breaking them up and analysing the pieces separately.
Added version information to the documentation.
December 01, 2004
Fixed binary files for version 1.1.0 beta3 which had been compiled with JDK 1.4 by accident. I recompiled them with JDK 1.3 and uploaded them again to SourceForge. I'm curious if anyone noticed.
Removed some old sample files that dated prior to version 1.0.
November 30, 2004
Updated <cvstagdiff> and
<cvschangelog> reports to account for the release of
version 1.1.0 beta3.
November 28, 2004
Third beta release for version 1.1.0.
November 27, 2004
Finished updating the documentation to account for the Unix
distribution. I also used this occasion to update the documentation
for the web application and explain load.jsp.
November 26, 2004
Tested the Unix distribution on MacOS X. Also changed the
distribution to have .zip files for Windows and
.tar.gz and .tar.bz2 for Unix. I also have
matching archives for source code.
November 24, 2004
I've been struggling for some time with how to deal with start scripts for Unix. I also find it tedious to maintain a large number of scripts that are identical except for one identifier. At first, I thought of having some kind of install program that could link up the right version of the right script, but I was hesitant at making the installation procedure more complex. A friend suggested to generate the scripts at build-time. This solves two problems: maintaining nearly identical files and having start scripts for Unix. Now, I can generate both and select which ones get in the ZIP file for Windows and which ones get in a new compressed TAR file for Unix.
Right now, I'm generating a ZIP file with .bat scripts
only and a separate compressed TAR file with shell scripts with no
extension only. Neither one has all the scripts but they are otherwise
identical. I could have the two files be identical and have both sets
of scripts, and possibly give the shell scripts a .sh
extension. But I hesitate since I don't think this is the standard in
Unix-land yet.
Code contribution!
Joe Fisher submitted a new version of the GUI's
SaveFileAction so it reports its progress to the user. I
have incorporated it into the codebase, it will ship with the next
release. Thanks, Joe. You get to be the very first external
contributor to the project.
November 22, 2004
Moved the detailed dependency-related measurement explanations from the Developer Guide to the Manual. Finalized the documentation for measurements, at least for now.
Renamed SymbolList to ListSymbols.
Finished its documentation and wrote a corresponding Ant task.
Started looking at FitNesse and the FIT framework again. One thing I don't understand is how to set these up as part of an automated build and put the contents under source control. Someone on the FitNesse Yahoo! group gets weird behavior when they put the contents of the FitNesse wiki under CVS and the gurus don't seem to have an easy solution. One option is to use the FIT framework by itself, but how do I run all the tests automatically and have them report that everything went fine or not?
November 14, 2004
Fixed the Unix script for OOMetrics and
OOMetricsGUI. Because they were symbolic links to one
script used by all other tools, they were missing their mandatory
-default-configuration switch. Now, they are their own
scripts, shared by no one else.
Tech docs around metrics and dependency-related measurements.
November 13, 2004
Fixed DependencyMetrics in both the CLI and Ant task.
It used to process each graph input file as it was loaded, which could
result in some nodes being counted more than once if they show up in
more than one file. By reading all graphs beforehand, they get merged
together before the measurements are taken, preventing double
count.
November 11, 2004
I decided not to mess with the UI on the GUI application. It would require massive reorganization to account for the different semantics of the UI elements between closures and the other functions. I will need to rework it anyway when I have a new renderer for closures, I'll take care of it then. I want to finish this release.
Also cleaned up the build file a little more.
November 10, 2004
Adjusted the UI for closure.jsp and
advancedclosure.jsp to use radio buttons when specifying
the degree of summarization to apply to the closure.
Adjusted build.xml to use Tomcat's manager when
deploying the web application. At the same time, I extracted some of
the properties to external properties files, such as those dealing with
Tomcat or CVS tasks.
Added better examples to the documentation of the
dependencyclosure Ant task.
November 09, 2004
Fixed the Tools docs and Ant task documentation to account for new
switches to DependencyClosure. I also started reworking
the UI for closure.jsp and
advancedclosure.jsp, but I'm going to need some more time
to finalize it and apply it to the GUI too.
November 04, 2004
It turns out the problem with the switch
-start-includes /^com.jeantessier.dependency.NodeFactory/
was related to the DOS command interpreter. It somehow stripped the
caret from the regular expression. Putting double quotes around it
fixed it.
November 03, 2004
Fixed the parameters for DependencyClosure in both the
CLI and Ant task. But at least the CLI version seems to still have
problems: the switch
-start-includes /^com.jeantessier.dependency.NodeFactory/
still matches anything with NodeFactory in it, as opposed
to only names beginning with it.
Someone filed bug
#1058905
where PublishedDiffToHTML.xsl still uses the old method
names from before the naming change. I fixed the bug and issued patch
#1060021.
October 28, 2004
Thought of a new feature for transitive closures. I was tracking calls that go through an interface-implementation transition a few times. Because of the dependency severing nature of those transitions, I could not compute the closure for the whole call sequence automatically. This got me the idea that if the dependency graph were to keep track of inheritance and implementation information, the tools would be able to cross the interface-implementation transition and compute larger sequences. This will take some while.
Fixed the broken link to Perl help in the web app.
Fixed extract.jsp where I had forgotten to account for
the fact that CodeDependencyCollector was no longer a
LoadListener.
Fixed a number of setters that were mistakenly named
getXXX() when I changed the naming scheme.
October 27, 2004
Checked in the new version of TransitiveClosure that
uses the new TransitiveClosureEngine. All the unit tests
are now passing, for the first time in nearly two years. I still need
to fix the UI and documentation of the transitive closure tools.
October 25, 2004
Changed GraphSummarizer so it does not create
extraneous dependencies, going from
a.A.a --> b.B.b to
a.A --> b.B and
a --> b unnecessarily.
October 24, 2004
Adjusted TransitiveClosure to use two engines, one for
upstream and one for downstream closures. The two engines share the
same factory, so the results are all in a single graph, like it used
to be with the old processing. Still, a lot of tests are broken and it
will take some time to fix them.
I was able to test my theories about separate summarization on
TestTransitiveClosureWithTestClass. Mostly successful,
but one test ends up with too many dependencies because
GraphSummarizer is a little too eager.
October 21, 2004
Thought up of a way to have TransitiveClosure work on
the raw graph and do the summarization separately. This works fine for
CLI and Ant tasks, but is awkward for the GUI and web application where
the user cannot easily save intermediary results. These last two will
need to include the summarization function internally and rework their
UI accordingly.
October 20, 2004
Retrofitted TransitiveClosure to use the new
TransitiveClosureEngine. Many tests are now broken
because it used to include summarization capabilities that are no
longer there.
October 19, 2004
More tests in preparation for retrofitting
TransitiveClosure to use the new
TransitiveClosureEngine.
October 12, 2004
Found java.net and took initial steps to have Dependency Finder listed there too.
October 11, 2004
Found an interesting article by a group at CERN who built a dependency analyzer for looking at their software: large C++ systems used in high-energy physics. This was really interesting since they had roughly the same motivations I had to come up with Dependency Finder. They have a nice introduction as to why you need to manage dependencies very closely and how painful it can be if you don't automate the whole thing.
October 10, 2004
Build initial support for distinguishing between referenced versus
concrete nodes in the dependency graph. NodeFactory now
has versions of its createX() methods that take a boolean
parameter to mark nodes as concrete. The default is for them to be
marked as referenced only. Marking a node as concrete makes its
ancestors concrete, but not its siblings nor descendants.
October 08, 2004
Came up with a name! Nodes are referenced by default, until the dependency extractor actually encounters them in analyzed code and then marks them as concrete.
October 06, 2004
Thought about categorizing dependency nodes some more. I was
concerned that dependencies on things that are not part of the body of
code under analysis might muddy things up and that everything might end
up in Object somehow. If I find a non-visited feature in
a visited class node, and I start walking up the inheritance tree to
locate where that feature is actually defined (wait a minute, I will
need to store inheritance information too), I might not find the
definition if it is in some third party library.
October 05, 2004
Got an idea to characterize nodes in the dependency graph between nodes that represent elements that are only referenced by analyzed code versus nodes that represent elements that underwent analysis. I was trying to track dependencies in a piece of software and hit a wall when I tried to see if anybody accessed private methods of an implementation class. All the other methods it inherited from superclasses kept showing up too.
Under JDK 1.4, dependencies are resolved to the exact type of the reference. For example, in the case of the Template Method pattern, if the client calls the template method on the concrete subclass, it creates a dependency to a shadow template method on the subclass, not the actual template method in the abstract superclass. This is a new form of interface pollution where a class can have symbols that it does not necessarily define but that it rather inherits from a superclass. These can create false impressions when running dependency analysis because you can miss actual calls to a method that are attributed an hypothetically overridden version in a subclass.
I could have Dependency Finder figure it out, somehow.
October 04, 2004
Finished LoadListenerVisitorAdapter.
I also noticed that I have quite a few tools that do similar things.
I need to align the naming of all these tools.
ListDeprecatedElements lists symbols from compiled code.
It focuses solely on elements marked as deprecated. It uses a
Printer to print elements as it finds them.
SymbolList lists symbols from compiled code. You can
choose between class names and feature names, but it offers no
filtering. It uses a Collector to assemble the output and
prints it as a separate operation. ListDocumentedElements
lists symbols from source code by filtering of special javadoc tags.
October 03, 2004
As I developed SymbolList, I realized that the way it
ties a LoadListener and a Visitor was common
to a few classes and that each one was reimplementing it, always in the
same manner. I decided to get rid of this code duplication by putting
it in a LoadListenerVisitorAdapter. From now on, if you
want a visitor to get called as classfiles are loaded, you will be able
to wrap the visitor in a LoadListenerVisitorAdapter and
then register it as a load listener.
October 01, 2004
For some reason, I thought Log4J had moved to Jakarta Commons as the Logging library. But after a little bit of investigation, I realized that was not the case. And there are no new version of Log4J yet.
Started looking at Maven.
September 30, 2004
Discovered that new versions of Ant have a <war>
task to help creating .war files.
September 20, 2004
Second beta release for version 1.1.0. I opened the developer discussion forum for people who use the API to write extensions or custom processors. Hopefully, the familiarity of Java camel-case names will outweigh the pain of moving their code to the new method names.
September 19, 2004
Generated a few finer-grained CVS reports to show changes between beta releases for 1.1.0.
September 14, 2004
Upgraded the following development components:
Ant : 1.6.1 -> 1.6.2
Revived the CVS diff reports using Ant's CvsTagDiff task. I'm also
trying to have Ant generate change log reports, but the
ssh authentication is getting in the way. I need to use
pserver access but it seems cvs won't let me
use it on a directory that was not checked out with
pserver. So now I have to keep two copies of the
development tree just so I can generate reports. This is annoying.
I also looked at StatCvs from SourceForge. It still
needs its own copy of everything, so it might not help all that much.
But it has nice little charts. :-)
September 12, 2004
Phase IX: assess work to change naming in test code.
Phase X: fixed test code. I'm done.
September 09, 2004
Phase VIII: fix the JSP files for the web app.
September 07, 2004
Wrote a new tool to list all symbolic names in a codebase:
SymbolList. It shows all class names, all methods' full
signature, and all fields' full signature. In addition, if the code
was compiled with -g and retained its local variables
table, the tool can list method parameters and local variables too.
Phase VI: find what previous phases might have missed.
Phase VII: fix what previous phases had missed.
September 06, 2004
Phase V: everything else under src/. Now I have to
deal with tests/ and straggling parameters and local
variables.
September 05, 2004
Phase IV: finished com.jeantessier.dependency.
September 04, 2004
Phase II: finished com.jeantessier.classreader.
Phase III: did com.jeantessier.commandline and started
com.jeantessier.dependency.
September 03, 2004
Looking a little further into renaming symbols. There are over
3,000 methods, but from those I can remove constructors, which will
retain their initial capital, and methods that already follow the Java
convention, such as toString() and
equals(java.lang.Object). But I must also account for
fields, where I use all lowercase with underscore to separate words.
Constants in all caps don't count, and fields with only one word are
just fine. So I wrote a little Perl script to list what's left and
ended up with 2,611 symbols that need renaming.
That still leaves local variable to take care of. I'll need to
tweak com.jeantessier.metrics.MetricsGatherer to find a
way to list them. It currently counts them, but doesn't keep track of
their names. Then again, maybe a simple classfile printer could do the
trick.
Phase I: got started on com.jeantessier.classreader.
I'll check it in, and when I'm done, I'll release beta 2 and see the
reaction it gathers.
September 01, 2004
Toying with the idea of changing the naming convention to adopt the
regular Java convention instead of my beloved C++ convention. This
would mean renaming accessors to getX() and
setX() and renaming all methods and fields so they
start with a lowercase letter and use camel case. That's a lot of
work and will obviously break the code of anyone who's be programming
to the API. Is it acceptable, if it brings the code in line with what
people expect of Java code? And it's quite an undertaking: 239 classes
and over 3,000 methods.
August 24, 2004
Configuring FitNesse and HtmlFixture still eludes me. I need some kind of tutorial on how to set them up together. And once that is done, how do I put the tests under source control? Let alone running them automatically from an Ant script? That includes starting a web container, deploying the web app, and connecting to it.
August 23, 2004
Started looking at FitNesse in combination with its HtmlFixture to test the web app.
August 18, 2004
At work, we're using HtmlUnit to test a web app through a browser. I really like the way it simulates the user connection and allows you to query the resulting HTML, including following hyperlinks and submitting forms. This could be very helpful in testing Dependency Finder's web app.
July 21, 2004
Had a baby boy. Work on Dependency Finder will have to slow down for a little while.
July 12, 2004
Someone pointed out that the HTML in the website have a
DOCTYPE for HTML 4.01 but actually contain XHTML
markup. Things like <br /> and
<a name"..." />=. This last one is specially
troublesome since most browsers start looking for the closing
</a> tag and consider everything past the opening
tag a hyperlink. I should change them to
<a name"..." ></a>= instead. I'll try to fix
them shortly.
July 06, 2004
Some more thoughts about combining selection criteria.
So the target boolean expression is:
(include1 || include2) && (!exclude1 && !exclude2)
Which we can generalize and rewrite as:
(include1 || include2 || ...) && !(exclude1 || exclude2 || ...)
Now, most of the time, there is only a single include clause and a single exclude clause. Especially in the GUI and the web application, where I have limited the range of options and where responsiveness is critical. It does not feel right to have all this overhead for traversing composite lists of one subcriteria. In the case where there is only one subcriteria, I should be able to use it directly and forgo all of the composite overhead. But I will need some kind of builder pattern to get to that point, somewhere I can encapsulate the decision of which classes to instantiate as I figure out what the selection expression is going to look like.
July 01, 2004
I realized that my approach to combining regular-expression-based and collection-based selection criteria is flawed. Each one verifies that a given node matches its include terms and does not match its exclude terms. That is, it satisfies the boolean expression:
(include && !exclude)
But if I combine two criteria with an AND, I get:
(include1 && !exclude1) && (include2 && !exclude2)
That is, the node must match both includes and neither
excludes. What I want, is for the node to match either
includes, so I might try combining criteria with an
OR:
(include1 && !exclude1) || (include2 && !exclude2)
But this fails to ensure that the node matches neither excludes. What I really need is:
(include1 || include2) && (!exclude1 && !exclude2)
That is, I want it to match either includes but none of the
excludes. To do this, I will need to split the current criteria
classes between include and exclude classes. I will
also need a NotCompositeSelectionCriteria.
June 30, 2004
Attended a session at JavaOne on the new annotation mechanism in the
upcoming JDK 5.0. This is going to be interesting, from the point of
view of parsing .class files and defining language
constructs.
June 28, 2004
Attended a session at JavaOne on sorting and filtering in Swing
JTables. They had a nice approach to combine multiple levels of
sorting and filter on multiple columns. I'll try to incorporate it
into OOMetrics when I get a chance.
June 27, 2004
Checked in the new composite selection criteria. Now, I need to put them to good use in the CLI and the appropriate Ant tasks.
June 24, 2004
Extracted common behavior from AndCompositeSelectionCriteria and
OrCompositeSelectionCriteria into a common abstract base
class CompositeSelectionCriteria
Read a white paper on dependency management by Jorn Bettin. It is very formal when talking about dependencies and complexity, but provides some interesting rationales for controlling dependencies. Basically, without strict, mechanized monitoring of dependencies, the project's complexity will spiral out of control and maintainability will go out the door. And what better tool to mechanically look at dependencies than Dependency Finder!
June 23, 2004
Created OrCompositeSelectionCriteria with either / or
logic. I think that's the one I want to use. I'll keep
AndCompositeSelectionCriteria around as a curiosity. It
might come in handy eventually.
June 22, 2004
Created AndCompositeSelectionCriteria so I can combine
regular expression-based and list-based selection criteria. This will
only be useful for CLI and Ant tasks, since the GUI and the web app do
not support list-based selection.
June 16, 2004
Fixed CollectionSelectionCriteria so it has separate
include and exclude lists. This way, I can leave the include list as
null to indicate a wildcard and explicitly exclude names
from a list. The previous implementation applied the the excluded
list to a predefined inclusion list, preventing me from doing
"anything but ..." type of logic.
Next, I'll need to combine regular expression-based with list-based selection criteria for maximum flexibility. This will mean some kind of AndSelectionCriteria.
June 15, 2004
Checked the help discussion on the project page in SourceForge and found a few new messages since the last time I checked. Somehow, I don't receive emails from that discussion anymore, even though SourceForge still says I'm monitoring it.
June 05, 2004
Discussed possible new icons with my friend who worked on Shrek 2. We brainstormed some ideas around a possible theme and made some promising sketches. I'm eager to see what he'll come up with.
June 03, 2004
As I was trying to explain scoping and filtering to someone, I came upon a new way of explaining it. The graph really has two dimensions: aggregation between packages, classes, and features, and dependencies between the nodes as a separate dimension. Scoping select specific nodes along the aggregation dimension, while filtering selects specific dependencies along the other dimension. Maybe that will make it a little easier for people to understand what I mean and how to use regular expressions in either context.
There was also some confusion around the
com.jeantessier.dependency.Visitor classes. Most of them
traverse a graph and leave it intact, but LinkMaximizer
and LinkMinimizer actually modify the graph in-place.
This means that if you run either one of them on the nodes in a given
factory, you can access the maximized or minimized graph through that
same factory. But if you use a GraphCopier to get a
subgraph, you need to go to the copier's internal factory to get at the
subgraph.
May 31, 2004
Fixed documentation for DependencyReporter to include
the switches that control what gets shown in the output graph or
not.
May 30, 2004
Finished moving my office to the next room down the hall. I do have quite a few books!
Someone asked me how to tie additional information to
com.jeantessier.dependency.Node objects for their
application. My answer to them is to use the Node
instances as keys in a java.util.Map. It implements
equals() and hashCode() based on the name of
the node, so comparisons will match just fine. This allows you to
associate any arbitrary data to nodes without introducing any
additional dependencies in the node classes.
May 29, 2004
Started moving my home office to the next room down the hall. Got all the hardware and wiring done.
May 24, 2004
Upgraded the following development components:
Tomcat : 5.0.16 -> 5.0.25
I also came upon a new UML tool called Jude. It has decent sequence diagrams but only supports UML 1.4 yet, not UML 2.0 with the nice ball and socket notation for interfaces. Maybe I can use Poseidon for clas diagrams and Jude for sequence diagram, at the cost of maintaining two models.
May 23, 2004
My neighbor works for DreamWorks and did the illustrations during the rolling credits at the end of Shrek 2. They look like medieval vignettes of various activities, but he somehow managed to have them represent modern activities of movie making, such as sound mixing and such.
I asked him if he could do icons for Dependency Finder in the same style and he said he'd look into it. So I put together a list of the icons and how they're used for him to look at. I hope it works out, it would be very cool.
May 22, 2004
New beta release for version 1.1.0. And I forgot to mention, I relabeled 1.0.2 to 1.1.0. I figured the changes to the tools, with the introduction of list-based scoping and filtering warranted a higher version number change.
I tried to generate a distribution that didn't include Xalan or Xerces and relied on what is provided by JDK 1.4.2, but I hit a wall when it came to creating SAX readers. Right now, I explicitly name a reader class from Xerces, which allows me to use custom attributes to trigger validation of the XML. But this custom class is part of Xerces while JDK 1.4.2 ships with Crimson; almost the same, but my reader is not in there. Once I had found the corresponding reader class, the custom attributes didn't match, so I was stuck. Changing reader might lock the code into JDK 1.4.2, which I am still reluctant to do. People relying on prior version of the JDK should still be able to just get the source, get Xerces and Xalan, and simply recompile.
I also tried to package the documentation in a separate JAR file. At one point, the main distribution file was about 800 KB instead of the current 5+ MB, once Xalan and Xerces and the documentation were removed. But since I cannot get rid of Xerces and Xalan just yet, I will wait a little longer before separating the documentation too. Right now, the difference is not worth the added complexity of downloading two files for people who want the documentation.
May 21, 2004
I don't know what SourceForge changed in their system, but their advice for my CVS problems were to get the latest version of my client. I did, and now everything's fine. I find it very hard to believe that they would change something as important as their CVS support without telling anyone. But what can you do.
Upgraded the following development components:
SmartCVS : 2.4.2 -> 3 rc
I was finally able to check in my most recent changes, including
documentation of new switches on Ant tasks and use of long names for
measurements when writing to .csv files.
Finally got around to updating my copyright notices to 2004.
I want to do a beta release for the next release, tentatively 1.1, compiled only for JDK 1.4.2 and above. This will allow me to see if anyone cares for me to stick with lower versions of the JDK. If enough people complain, I'll do the real release with JDK 1.3 again. Or, they could simply get the source code and compile it themselves with JDK 1.3 and track Xalan on their own, but I would have to stick with Log4J and Jakarta-ORO for this to work.
May 20, 2004
Upgraded the following development components:
Ant : 1.6.0 -> 1.6.1
Opened a new trouble ticket with SourceForge. I haven't been able to contact the CVS repository for over a week now.
May 13, 2004
I could depend only on JDK 1.4.2 instead of 1.3. This way, I would not have to ship Xalan with Dependency Finder. I could even go further and use Java Logging and Regex instead of Log4J and ORO respectively. Then, Dependency Finder wouldn't need any third party software.
A while back, I compared Log4J with Java's Logging API and preferred Log4J. It is more flexible and easier to configure. It would feel strange to move away from it now.
I chose ORO because it supports pretty much all of Perl's very rich regular expression language. From what I understand, its coverage even outdoes Java's Regex. But Dependency Finder only uses a small subset of that language, which is equally covered by both package, so I could easily switch.
So switching to JDK 1.4.2 would give me access to both the Logging and Regex APIs. It also includes a complete copy of Xalan. JDK 1.4.1 had a bug in its Xalan, but 1.4.2 is all better.
I wonder how many people out there currently use JDK 1.3 or a version of 1.4 that is below 1.4.2. If I switch now, how many users will not be able to follow? If I don't switch, then I need to keep dragging Log4J and ORO along.
CVS on SourceForge is still out.
May 10, 2004
Documented the new attributes of theDependencyReporter
and OOMetrics Ant tasks.
Adjusted the metrics's CSV printer to include each measurement's long name, in addition to their short name, to reduce confusion.
CVS on SourceForge is out. Again.
May 09, 2004
Documented the new switches on DependencyReporter and
OOMetrics.
CVS on SourceForge is back.
May 06, 2004
Deleted DeprecationReporter.
Updated the UML diagrams for the package
com.jeantessier.metrics.
Fixed javadocs for DocumentableDifference.
CVS on SourceForge is out again. Grrr.
May 05, 2004
CVS on SourceForge is finally back.
May 04, 2004
Cleaned up MartinConfig.xml to compute Robert C.
Martin's D' metric. I also drew a diagram of the various
measurements and how they feed into each other. This might be useful
documentation.
CVS on SourceForge is still down. This is annoying. I don't want to have too much code not checked in; it's not safe.
May 02, 2004
Added scope lists for OOMetrics similar to its current
filter lists. I don't know what good they could serve yet, since any
such filtering could already be achieved by extracting only the desired
classes.
Added -show-all-metrics switch to
OOMetrics to show metrics for classes that were not
extracted. This is so I can list metrics regarding inbound
dependencies on classes outside the examined codebase, so I can group
dependencies on deprecated symbols by those same deprecated symbols.
It still uses -filter-includes-list to limit the tracking
to dependencies on deprecated symbols, but all non-deprecated classes
and methods will now be empty. With the new switch, it will list all
non-empty metrics, including those metrics attached to symbols outside
the codebase.
CVS on SourceForge is down again.
April 30, 2004
Document dependency-related metrics in Developer Guide.
UC Irvine team to do Eclipse plugin using Dependency Finder.
Managed to get Poseidon license on laptop. Latest version supports UML 2.0 with new notation for interfaces. Might be interesting.
CVS on SourceForge is back.
April 29, 2004
Stylesheet for HTML of dependency graphs
Removed Poseidon from my desktop. Had trouble installing license on my laptop.
April 28, 2004
Removed trace, new OOMetrics now takes 6 minutes
instead of four hours.
CVS on SourceForge is down. I cannot check in changes.
April 27, 2004
The new OOMetrics on that production code and it still
took 4 hours, but at least it worked and stayed under the 500MB heap
size. I still need to figure out what it is taking so long. Im
tempted to try a custom version of MetricsGatherer that
only deals with dependencies.
The metrics configuration had some errors in it, so I mapped it first to verify where each piece of data came from, and then entered a new, much simpler version.
Had to adjust StatisticalMeasurement so it bases its
empty status on that of the measurements it monitors. Otherwise it
would say it was not empty when it was monitoring a bunch of empty
measurements in submetrics.
MetricsGatherer does not track dependencies on fields
directly, but rather only the class they are part of. In the context
of this latest work, this means it cannot detect dependencies on
deprecated fields. Maybe it is not such a big deal, since it will
never be able to track dependencies on fields of primitive types (int,
float, String, etc.) anyway because they are inlined by the
compiler.
April 26, 2004
Tried the new filtered dependency metrics report on some production code at work. Gave it 1GB heap and it crashed after 4 hours with an out of memory error. Filtering in accumulators is too expensive. The elementary measurements (IICM, OIP, ...) still gather all dependencies before we start filtering and they use up all the memory.
So I moved the filtering to MetricsGatherer instead.
This way, I can take out dependencies at the source. I only had time
to do filter lists now. I'll look at scope lists later. Also, right
now the resulting report is broken down by dependency source. Showing
them broken down by target is going to be more difficult, but I can
use MetricsFactory.AllxxxMetrics() to get at metrics
for deprecated symbols outside the codebase.
April 25, 2004
Finished Metrics.Empty(). It recursively looks at any
submetrics and also looks at all measurements, ignoring those that are
not visible. The stylesheet is also shaping up. I want to take the
same approach with my other HTML generators.
Now, OOMetrics skips empty metrics by default.
You have to pass it the -show-empty-metrics to see all
metrics like before.
I haven't updated the documentation yet.
April 24, 2004
Finished the new types of measurements.
April 23, 2004
Shifted strategy. I'm going to use OOMetrics instead
of a simple dependency graph. This allows me to have automatic counts
tallied at the class and package level. But the changes are extensive.
I need variations on the AccumulatorMeasurement and the
ability to ignore empty metrics and focus on the actual
offenders.
Also started playing with XSLT stylesheets for converting metrics
from XML to text and HTML. I also experimented with using CSS to
format the HTML. But with the introduction of external stylesheets,
it raise the question of where am I going to put them? I can provide
defaults in etc/ or simply embed the stylesheet in the
generated HTML. I'm not completely decided yet.
April 22, 2004
DeprecationReporter is working great to track usage of
deprecated APIs. Now, I need to provide a summary with counts broken
down by package. I should be able to do this using
OOMetrics with the right configuration. I will need a new
type of measurement to take into account the lists of deprecated
elements.
Adjusted the stylesheet for the website and the documentation to remove the underlining in hyperlinks. I think it makes them a little easier to read. They're still blue, so they stand out, of course.
April 21, 2004
DeprecationReporter is not flexible enough, so I found
a way to adjust DependencyReporter so I can use it
instead. I'm adjusting the printers in the
com.jeantessier.dependency package so they can all hide
inbound or outbound dependencies or empty nodes. In due time, I'll be
able to remove that business logic from XSL stylesheets.
I still have to document the new switches.
I will physically remove DeprecationReporter very soon,
before anyone really starts to use it.
I also want to write an HTML printer so I can generate the HTML directly from within the application. Then I could use it in the web app to have nicer output with hyperlinks.
April 20, 2004
Wrote a whole new tool to monitor usage of deprecated APIs.
ListDeprecatedElements scans JARs and collects a list of
names for deprecated classes, interfaces, fields, methods, and
constructors. DeprecationReporter is a variation on
DependencyReporter that uses the list instead of
regular expressions to figure out the scope and does no filtering.
There are CLI and Ant versions of each, with associated
documentation.
Refactored TestRecord to use StringReader
to read back generated XML documents in strings.
Refactored TestRegularExpressionSelectionCriteria to
make all its fields private.
April 19, 2004
Wrote unit test that uses XPath to validate the generated XML from
com.jeantessier.diff.Report. This will later help me
write tests that use Xalan to test the XSL transformations.
April 18, 2004
I started writing more tests to check that interactions with Xerces are tested. In the process, I cleaned up some of the tests for classes that generate XML documents.
I found some mistakes in classfile.dtd: missing
elements, typos in element and attribute names, those sorts of things.
I fixed them. I also changed the generated XML so it does not pretend
to be standalone anymore. The DTDs are on the project's website, how
can these documents be standalone!
Now, I need to write some regression tests for Xalan too.
April 16, 2004
Upgraded the following development components:
Xerces : 2.5.0 -> none Xalan : 2.5.1 -> 2.6.0
I am not going to chase after Xerces anymore. I do not use anything fancy that would require me to be absolutely up-to-date. I will do just as fine with the version that comes with Xalan. And this way, I don't have to worry about my Xerces version working with my Xalan version.
April 07, 2004
Someone else asked me about JAR-to-JAR dependencies. Last time I pondered this question was on 2003-11-14.
Since then, I thought of adding another layer at the top of the dependency graph, above the package layer. But passing the JAR information around all the way to the dependency extractor would introduce changes in the data model that I am not completely comfortable with.
Plus, this new layer would be incomplete. What should I do with outbound references to classes beyond the scope of the tool, that are possibly in other, unknown JARs? What should I do with packages that span multiple JARs?
Maybe with a parallel layer besides the packages instead of above it. This would impact visitors and printers and any other parts that deal with the dependency graph. And it still doesn't solve the problem of dependencies on classes outside the ones being analyzed.
I'll need to give this some more thought, still.
April 01, 2004
Built a stop condition for the new closure engine and came up with the public interface so I can control how many layers it computes.
Remove all remaining signs of support for object serialization.
This consisted namely of removing code that used
java.io.ObjectInputStream to read files and having
com.jeantessier.dependency.Node not implement
java.io.Serializable anymore.
March 30, 2004
Release the Dependency Finder tutorial at last. I managed to crop all my screen captures in a consistent fashion. At the last moment, I noticed that a tool tip was on one of the GUI captures. Too bad.
I started thinking about an OO Metrics tutorial too. Setting up a custom configuration is non-trivial and could use some kind of introduction.
March 29, 2004
Removed all support for serialization of the dependency graph. I
was never able to deserialize the graphs anyway. I was semi-useful for
guesstimating the size of the graph, but DependencyMetrics
is much better for that. Serialized objects are not forward-
compatible anyway, so they do not make a good mechanism for
persistence.
I started to compress the sample XML files on the project's home page. They were taking up too much space and making me overrun my quota over there.
March 28, 2004
Did some screen capture for the tutorial. My previous version had crappy mockups in PowerPoint. I captured the same pictures in both the web application and the GUI, but the images are too big (800x600) to put in the PowerPoint slides that make up the tutorial. If I shrink them down to make them fit, I cannot make out the details that I need to show. So I will need to crop the important parts out, on all images.
March 22, 2004
Outfitted the closure engine with an inbound selector in unit tests.
Fixed broken links on the Resources page.
March 21, 2004
Refactored closure selectors to share common code. This will also help me pass an abstract selector to the engine when calculating closures.
March 20, 2004
Added an InboundSelector to compute "upstream"
closures.
March 19, 2004
Looked at the bug list and feature request list. It had been a while. There was one bug request regarding broken links on the web site, and two requests for interesting new ways to use JarJarDiff.
It turns out that I had thought of one such way back on 2003-08-19. The idea is to use a dependency graph to list the parts of a third party API you are using. Then feed this list to JarJarDiff to limit the change report to the subset that you are really using. All the tools are there, it's just a matter of how you use them. I scanned my notes and added them to feature request #900446 until I come up with a formal description.
March 18, 2004
Figured out how to keep the graphs separate while I compute the transitive closure. The selectors and the engine need to keep two lists of nodes, one for each graph. This allows the closure to only copy the nodes and dependencies that will make up the closure.
But I have another problem. What if class A depends
on class B, and method foo() of
B depends on class C. When I traverse the
graph to compute the closure, is it reasonable to visit features of
classes for additional dependencies? Does A transitively
depend on C in this case?. At runtime, it would only if
foo() is called as a result of interactions on with
A. If that were the case, the graph would have a path
from some feature of A to foo() anyway, so
maybe the transitive closure engine doesn't need to go the extra
distance. I'll think about it some more.
March 17, 2004
More work on TransitiveClosureEngine. I'm stuck in the
selectors and how they navigate the original graph and copy only what's
needed to the destination graph, all the while keeping track of
individual layers as I build the closure.
March 15, 2004
Finished the initial step in the new transitive closure algorithm. Now, I need to work on each step's processing, where I incrementally build the closure, one level at a time.
March 14, 2004
Started working of a NodeSelector to handle the initial
step of the new transitive closure algorithm. I need to take a scope
criteria and traverse the graph, collecting nodes matching the
closure's starting point as I go.
March 12, 2004
I have a problem with test-driven development. People say you can use the test suite to document how to use a system; but if I'm new to this software, which one of the hundreds of tests should I look at first? I have been toying with the idea of using the dependency graph to categorize the tests and maybe provide a order in which to approach them. I wonder if I could use some clever heuristic estimate the complexity of a given test. I would have to start with a test method and look at dependencies to other classes and methods in the same package. I don't know what the heuristics would look like, yet.
I tried to list OO metrics for test classes by using a group
definition. I noticed that the group counters for the group I had
created were all at zero. It looked strange since the first one is the
number of public classes and it said zero. Statistical measurements
were just fine. After investigating a bit, I realized the counters are
incremented by MetricsGatherer, but only for the package
group of a given class. My custom group never had a chance.
I also noticed one more problem. The statistical measurements at the project level take all groups into account, packages and user-defined. This means that SLOC counts some classes more than once, for example. I don't have a solution at this time.
March 07, 2004
Following a recommendation from a user, I reworked the documentation for scoping and filtering in Ant tasks.
March 04, 2004
Adjusted PermissiveDispatcher so it ignores HTML files.
I also gave it its own unit tests.
A number of people have been asking about why Dependency Finder does
not list line numbers where dependencies occur. I added a section in
the User Manual that explains how the line number information in
.class files is so fragmented as to be useless. I put it
under the "Limitations" heading.
March 02, 2004
Scott Stirling pointed out IBM's SA4J to me. Apparently, IBM acquired SmallWorlds and this is based on the SmallWorlds tool. It would explain why my link to SmallWorlds on the Resource page is broken. Thanks Scott for plugging Dependency Finder in a related article on TheServerSide.COM.
Scott also gave me some feedback on the documentation and submitted some improvements. He's also investigating graphical rendering of graphs on his own. I'll keep you posted.
March 01, 2004
IBM released a review of Structural Analysis for Java (SA4J).
February 26, 2004
I've been reading "UML for Java Programmers" by Robert C. Martin. In one chapter, he talks about dependency management and recommends using tools to automatically track them in code. He goes so far as to recommend JDepend to readers. I wonder if he'd recommend Dependency Finder too. Maybe if I add a package-level dependency cycle detection feature, it would make the tool even more useful. At some point, I will have to start thinking about going beyond the raw data and have the tools do more work when it comes to analyzing design quality factors.
February 25, 2004
Got started on a TransitiveClosureEngine to handle the
next version of transitive closures. The engine should select a
starting point in the graph and incrementally grow a subgraph from that
initial set of nodes until some termination criteria is met. This
could be that a given node is reached or that a certain number of steps
have been taken.
Added a link to the patch tracker on SourceForge from the project's home page.
February 21, 2004
Finished passing XML encoding to XML writers.
February 20, 2004
Worked on having XML writers take an optional encoding identifier. The default is UTF-8 but may not be enough if some Java identifiers contain multibyte characters. I tried UTF-16, but IE and Xerces had trouble with it. So I'll just let the caller pick something they like.
February 19, 2004
Fixed ClassReader so it processes multiple
.class files correctly. I modified the DTD to allow
multiple <classfile> tags within an all inclusive
<classfiles> tag. I logged it as bug #900938.
I fixed it immediately as patch #900942.
February 18, 2004
Someone has been having a number of issues. I'll be able to fix some of them, but not all.
First, they analyzed classes with non-ASCII characters in
identifiers. For example, a class name or method name that includes an
"é" character. I was surprised that javac will let
you do such a thing; it turns out this is perfectly legal. Anyway, the
encoding for XML output is UTF-8. XML parsers cannot read the data
correctly because the characters in the stream do not correspond to the
UTF-8 encoding. They would like me to ad an option to specify a custom
encoding.
I looked into this an since Dependency Finder simply write out String objects, maybe I should simply use Java's default encoding instead. The documentation says this should be UTF-16, but when I try it, Xerces complains about byte ordering. And IE complains about the encoding not being supported. More thought needed.
Second, the .class file parser throws a
ClassCastException when it encounters unknown, illegally
constructed attribute_info structures. Apparently, this
was with output from Visual Age for Java. I logged it as bug
#900060.
I fixed it immediately as patch #900062.
Third, they encountered the situation I described on 2004-02-03. I am starting to think that maybe I should do something about it. But what?
Fourth, and last, they tried to run ClassReader on a
whole JAR file. It is designed for use on one file at a time (in
spite of what the documentation says), not on a whole codebase. The
result is an invalid XML document with repeated DOCTYPE and no root
tag. I'll try to fix that tomorrow.
Ran this journal through a spellchecker.
February 17, 2004
Fixed a broken link to Poseidon for UML in the user manual.
February 16, 2004
Someone at work brought TouchGraph to my attention. It's a graph package for complex graphs that lay themselves out. You can collapse nodes and stretch things around. It looks very cool and maybe I could make use of it in Dependency Finder for some kind of rendering of dependency graphs. I looked at the code on SourceForge, but there is no documentation and I don't have the time to investigate further right now. Maybe later...
February 09, 2004
Last November, I nominated Dependency Finder for the 2003 Jolt Award at Software Development magazine. Today, they announced the finalists. I'm afraid it didn't make the cut. Not that I had high hopes or anything. It did get a mention in the magazine after all.
February 06, 2004
Software Development magazine published a piece on open source software in which they mention Dependency Finder. It is listed right alongside heavy hitters like LAMP (Linux, Apache, MySQL, PHP), Perl, and JUnit. My name is listed with the likes of Richard Stallman, Larry Wall, Linus Torvalds, Yukihiro Matsumoto, Kent Beck, ...
... eh! ... wait a minute! ...
... all these guys are übergeeks! ...
They've put me in with a bunch of geeks! Args!!!
:-)
Or more precisely: :-D
February 03, 2004
Someone came up with some weird behavior in Dependency Finder and asked me for an explanation. It turns out to be caused by some interesting things done by the Java compiler. I touched upon it back on 2004-01-07, but I'll elaborate further here.
First, suppose you have the following classes A and
B:
class B {
void b() {}
}
__
__
__
__
class A extends B {
void a() {
b();
}
}
|
 |
Now, imagine for a second that we have the following class
C:
class C {
A a = new A();
void foo() {
a.b();
}
}
|
 |
The compiler resolves the line "a.b()" as a call to
method b() on object a of type
A. The JDK 1.3 compiler will see that method
b() is actually defined in superclass B of
class A and will generate bytecode to call
"method b() in class definition B, or one of its superclasses".
This is fine and dandy as long as nobody overrides b()
in subclasses of B, like A for instance.
Imagine that someone overrides b() in A but
does not recompile C, maybe because this client code was
developed by someone else and the person making the change is unaware
of its existence. Now C will go on calling
"method b() in class definition B", even though
the instance a is of type A and now has a new
definition for its method b(). The compiler said "call
the method defined in B" and that's what the VM will do.
So the good people at Sun changed the compiler in JDK 1.4 to use the
type of the reference instead of where it thinks the method is located.
The VM will walk the inheritance tree at runtime to find the method.
So in the JDK 1.4-compiled version of C even if class
A does not override the method b(), the
bytecode essentially says to call
"method b() in class definition A, or one of its superclasses".
Now, even if we modify A without recompiling C, the
method will resolve correctly.
Let's take a closer look back at class A's method
a(). In reality, it is calling method b()
on the implicit this variable, which is of type
A. So if you compile A with JDK 1.3, it will
try to call method b() in class B. If you
compile it with JDK 1.4, it will try to call method b()
in class A.
Dependency Finder gets its information from the bytecode in the
compiled Java class. It provides you with an exact rendition of what
the compiler did. In the case of the code above, compiled with JDK
1.4, it will list a dependency
A.a() --> A.b(), even though there may not be
any method b() in class A.
Now you may ask "Can't Dependency Finder figure it out and assign
the dependency to method b() in class B?"
The answer is no, it can't. For starters many dependencies go to
classes that the tool will never see such as classes and features in
external libraries that may not get analyzed, such as
rt.jar. Then, there is the issue of starting to make
assumptions. I've resisted the temptation to make any assumptions so
far. I would rather have to tools present an unmodified view of
reality and not run the risk of misleading users with possibly invalid
assumptions. Even if this means that results look strange from time to
time.
I also had someone else ask me about a launching script for JarJarDiff on AS/400. I have never even seen as AS/400 system, so all I could do was to point them to the current Windows and Unix scripts, and what it is that the JarJarDiff tool classes do, in the hope that they are able to fix it for their system.
February 02, 2004
Looking at the release plan, I think I'm a little dispersed right now. I need to focus and get things rolling again. The holiday break really threw me off and left me with a couple of unfinished tasks. I'm going to complete the documentation and fix the dependency closure bugs and ship the net release ASAP.
January 30, 2004
Turns out the discussion on praprog was aimed at code analyzers that are part of the language compilers and how they traverse parse trees to determine the type of expressions in loosely typed languages. It was not directly related to the work done by Dependency Finder, but there were still some interesting ideas. Like Tarjan's algorithm for finding minimum spanning trees using depth-first search. It was a good exercise, even if the knowledge will not be immediately useful.
January 29, 2004
Dependency Finder is three years old!
I have been thinking some more about tracking inter-JAR
dependencies. I could come up with some kind of GroupNode
that would be the parent of PackageNode. But this
assumes that packages are wholly contained in one location, which is
not necessarily the case. An alternative would be for groups to be
made of arbitrary sets of classfiles, kind of like the group
functionality in OOMetrics, where classes can be part of
more than one grouping. Some groups represent packages while others
could represent JAR files. Still needs more thought.
The praprog mailing list had a discussion on dependency cycles and some of the theory behind cycle detection and resolution. Looks like I'll need to hit the books to keep myself current. :-)
January 27, 2004
Started working on a tool to list packages by JAR file in a given codebase. I'm thinking I could turn this into a way to track classes by their location, be it a loose class file or as part of a JAR file. I have had a few requests for tracking inter-JAR dependencies and this could be a step in that direction.
January 26, 2004
Yesterday, I forgot to refactor the JSPs to use the new
SelectionCriteria instead of the previous
SelectiveTraversalStrategy directly. Of course, the Ant
task for compiling JSPs using Jasper has changed between Tomcat 4.1.27
and Tomcat 5.0.16, so I had to spend a fair amount of time getting my
custom Ant build script up to stuff. After that, upgrading the JSPs
was pretty easy.
There was a thread on the praprog mailing list about code inspection tools. At first, I didn't want to mention Dependency Finder because the original message asked for tools to evaluate code style and unused variables/methods. Dependency Finder can't do much about style, and while it can find elements that are not referenced directly, that does not necessarily mean they are not used. They could be interface methods or things called via reflection. But then, someone else brought up JDepend, so I had to say something. Some of the other tools mentioned:
I haven't tried any of them myself, but some of the brochures looked nice.
January 25, 2004
I'm done with the refactoring. It was a lot of work but went on smoothly. Now, I move on to the next task in fixing the closure logic.
January 24, 2004
I started revamping the dependency closure computations. First, I
need to extract node selection logic to its own class and refactor
SelectiveTraversalStrategy to use the new
SelectionCriteria to determine both scope and filter.
This is getting to be quite an undertaking, but it will help the new
closure logic figure out starting nodes and stopping conditions.
January 21, 2004
Tried the web application with Tomcat 5.0. Someone claimed they had trouble deploying Dependency Finder with it. I'm afraid this is going to turn into one of those nasty "It works fine on my machine" as I was unable to reproduce their problem.
January 19, 2004
Upgraded the following development components:
Ant : 1.5.3-1 -> 1.6.0 Jakarta ORO : 2.0.7 -> 2.0.8
There is a nice new feature in Javadoc that Ant 1.6 now makes
available to me. The -linksource switch to Javadoc links
the documentation to the source code. An HTML-ized version of the
source files is created alongside the javadocs. I also saw something
called either "j2h" or "java2html" a while back that created
hyperlinked version of the source code, complete with syntax
highlighting. I wonder if I could somehow get to two to work together.
The links between documentation and source could definitely be useful,
and the syntax highlighting is quite cool too.
I hesitated to checking the new version of build.xml
that uses the linksource attribute to the
<java> task. This would require that people upgrade
to Ant 1.6 just to compile Dependency Finder. But then again, it is
only if they try to generate the javadocs, so it shouldn't really be a
problem.
January 16, 2004
Found a reference to Dependency Finder on the OSSwin project page. They had mistakenly listed the licensing scheme as GPL when it is actually BSD, but it has all been fixed now. This project is a nice, comprehensive list of open source software for the Windows platform.
I also found someone who listed Dependency Finder in their resume under a "tools used" heading. I will take it as a testimony to the broad acceptance and wide adoption of Dependency Finder. :-)
Someone asked if I could add the line number where the dependencies occur in the dependency graph. Back on 2002-10-31, I had toyed with the idea of modeling each dependency with their own object. This would allow me to collect a lot more data about each dependency, but at the cost of massive object creation. I'm afraid this would impact performance too much. I'll keep thinking about it some more.
January 14, 2004
Latest SourceForge tallies show downloads only for old release files:
release 20020127 of "DependencyFinder.zip"release 20020127 of "DependencyFinder.src.zip"release 20020711 of "DependencyFinder.war"
These coincide with the first time these names were used, when I removed the release label from the file names. I suspect that some new logic for tallying downloads at SourceForge looks at filename now instead of what maybe used to be either a combination of release ID and filename or some form of file ID.
Actually, looking at the links on the download page, the links for
the various DependencyFinder.zip files are identical. I
wonder what people are downloading? The most recent file or one from
over 18 months ago? A quick download at least reassured me that they
are indeed sending the most recent file, but that's regardless of which
link I click. I cannot download any of the previous versions; I always
end up with the most recent file.
So I always download the most recent file by a given name, but the download gets tallied with the oldest file by that name. Strange. I hope this is temporary and the SourceForge people fix this soon. Otherwise, I'll have to reinstate the version label in the filenames (which might actually not be a bad idea).
January 12, 2004
Updated this journal.
Added quotes to the website.
Cleaned up leftover text on the resources page.
Now, I need to go and update all the copyright notices to 2004.
The SourceForge website mentions that project statistics are currently impacted by known issues. They are working on it. They have been affected since 2003-12-22.
January 11, 2004
I fixed my HTML scraper to account for the new HTML on SourceForge's download page. It now seems to work just fine. But the data on SourceForge is stale. The statistics page only go to December 30, 2003. I fear that SourceForge is having problems with its statistics collection again.
Apparently, there were over 50 downloads of release 20020127 during the holidays. I don't see why people would be interested in that old version. Something is definitely fishy with SourceForge's statistics and download tallies.
January 08, 2004
Rosalyn Lum, of Software Development magazine, sent me an email to enquire about Dependency Finder. It seems it might get mentioned in their upcoming March issue. Yeah!
January 07, 2004
Researched how inherited methods are represented in compiled code.
Method access is resolved based on the type of the object reference
through which the call is made. In the case of a concrete class
calling its inherited methods, it does so against the this
implicit variable which is typed to the concrete class itself. Hence,
all the dependencies are to the concrete versions of the methods.
Here, JDK 1.3 and JDK 1.4 differ slightly. In JDK 1.3, the compiler would resolve method calls to where the methods are defined in the inheritance hierarchy. In JDK 1.4, the calls are resolved to the lowest point in the inheritance hierarchy. This allows redefinition of the method in subsequent versions of subclasses, where appropriate. With the JDK 1.3 compiled class, it would have to be recompiled to benefit from the new definitions.
Look to 2004-02-03 for an example.
Someone is having trouble deploying the web application in Tomcat 5.0. I will have to research this further.
January 06, 2004
Someone is asking about classes depending on methods they inherit from interfaces or abstract superclasses. If a concrete class calls one of its own methods that it inherited from an interface or an abstract superclass, there is no dependency recorded between the concrete class and its ancestor. I'll need to research this a little further.
January 03, 2004
I have an automated task that scrapes the SourceForge "Files" page
for Dependency Finder and saves the download tallies in a
.csv file. I've been running it for over a year now. I
have a nice graph in Excel showing trends and releases. I was a little
apprehensive about my Windows 98 PC not crashing while I was away on
vacation, so I was relieved to find it still running upon my return.
But unfortunately, SourceForge changed the HTML for the page the day
after I left, with the result that I collected no data for the whole
time I was away. And now, I must rewrite the HTML scraper to account
for the new HTML.
December 31, 2003
I'm away on vacation, but I still found the time to check in on
messages. Someone has been having difficulties but I think it's just a
corrupted .class file.
They also asked to track database calls. I hope they meant calls on the JDBC API. It is very difficult to track the actual SQL from within Java. You need to setup dynamic proxies to trap all calls to statement objects and resolve parameters and all other kinds of transformations. This is way beyond the capabilities of Dependency Finder, and well nigh impossible with static analysis alone.
December 15, 2003
Came up with much better screenshots.
Started working on how to break up analysis of large codebases. I am struggling with where to put it, though. Should it go in the Manual or as part of the samples?
December 14, 2003
False alarm. They reinstalled the latest version of Dependency Finder and it now works just fine. I am extremely relieved to hear this. I was not looking forward to tracking weird flushing bugs.
Created a patch for fixing the long names for IEPM
and OEPF and published it as
patch #860191.
Fixed Ant tasks that are subclasses of GraphTask to
accept multiple graphs. Like <javac> and others,
you can use either the srcfile attribute or a nested
<src> element, or you can even use both. It uses a
path-like structure, but I wanted to use a FileSet
instead. You cannot really provide a directory, you have to specify
XML files. But as I was editing the documentation, I came upon tasks
that are subclasses of FileSet and can have nested
<include> elements. I'll have to look into doing
something similar instead of what I did just now.
I wanted to look at the size of serialized graphs to compare full graphs to class-to-class graphs. The way references are handled in serialized graphs is closer to how it's handled in memory than my own XML format. But I ran into a stack overflow situation when I tried to serialize this one graph. This whole idea of serializing graphs is just getting worse and worse.
December 13, 2003
Well, it didn't work out. They tried to break down their codebase
but all their DependencyReporter output is either of
size zero or badly truncated.
Back in July, I had problems with truncated files, but back then it
was because java.io.Writer instances were not being closed.
I removed all calls to java.io.Writer.flush() because the
stream is supposed to be automatically flushed when it is closed. It
has worked just well for me since then and I am troubled that they
should be having these kinds of problems.
They gave me a copy of their codebase to try and recreate the problem, but it worked fine for me. I'm down to thinking maybe it's because they're on Linux, for some reason. But that can't be it.
As I was working out their problem, I realized how great it is to
have DependencyReporter to merge graphs together. I can
give it as many graphs as I want and it can combine them all
together. I noticed the Ant task version doesn't do that; it can
only take a single graph at a time. I'll need to fix that.
I fixed measurements IEPM's and OEPF's long name. Now, I'll need to create a patch for this.
December 12, 2003
That one customer with the large codebase and low memory still has
problems. They had tried OOMetrics without much success.
The dependency-related measurement proved too hard to figure out
right. I really need to do something about them.
So, they need to count dependencies between classes.
One approach is to use the dependency counts from
OOMetrics. The downside is that it uses an
AggregatingClassfileLoader to load all the class
structures before making any measurements. Some measurements attempt
to traverse multiple classes and the tool must make sure they are
present in memory at that time.
Another option is to use DependencyExtractor to extract
a dependency graph first, and then get the information from it.
DependencyExtractor uses a
TransientClassfileLoader and discards each class structure
as soon as it's gotten the dependency information it needs. The memory
requirements are much less.
But for a large codebase, the resulting graph can still be quite
large. If you are really restrained memory-wise, it may still be too
much. My customer was trying to run DependencyExtractor
to create one large graph and then reduce it with c2c.
Since all they needed were class-to-class dependencies, we figured they
could run DependencyExtractor multiple times on subsets of
the codebase, run c2c on the resulting graph subsets, and
finally recombine the now much smaller class-to-class graphs. After
trying this with DependencyFinder.jar, it turned out that
the class-to-class graph reduced complexity by 98% compared to the
equivalent extracted graph. I'm anxious to see if this worked for
them.
December 11, 2003
Someone has been trying to analyze a large codebase with limited
memory. They're interested in counting class-level dependencies and
have been using DependencyReporter to reduce the graph and
then count inbound and outbound dependencies. I suggested they use
OOMetrics instead. It has a whole group of oddly named
measurements (OEP, IIPM, etc.) that already track dependencies. As I
was reviewing them especially in the context of
MartinConfig.xml, I realized they were kind of cryptic and
I need to document what each one does and how you can combine them to
arrive at the counts you're interested in.
I noticed that measurement IEPM and OEPF had the wrong long name. They said "Extra-Class" when they are actually "Extra-Package".
December 10, 2003
Got a new laptop. Now I can have something closer to a real development environment.
Upgraded the following development components:
OS : Windows 98 -> Windows XP Home JDK 1.3 : 1.3.1_05 -> 1.3.1_09 JDK 1.4 : 1.4.1 -> 1.4.2_03 Tomcat : 4.1.27-LE-jdk14 -> 5.0.16
With the Windows XP based on Windows NT, I can actually use the startup scripts that ship with Dependency Finder. On Windows 98, I had to use variations that worked around limited memory and an impossibility to create temporary environment variables.
December 09, 2003
Added help links to the resources page.
Started an embryonic screenshot gallery.
December 06, 2003
Added a feature to ClassMetrics that counts the occurrence of each VM
instruction in the analyzed codebase. I had to do some minor refactoring of
classes Hex and Instruction. The feature is actually in the class
com.jeantessier.classreader.MetricsGatherer and used by the UI classes for
the CLI and the matching Ant task.
December 05, 2003
Steve Kirk sent me his rt.jar file. I tried ClassList on it with logging
turned on to see exactly where it fails. I also discovered
"javap -c classname" which dumps the instruction sequence for each method.
I compared the sequence from my logs with the one from javap to see if I'm
interpreting the bytecode correctly.
It turns out the class com.jeantessier.classreader.Instruction had the wrong
size for the instruction "fstore". It listed it as 1 byte when it is really
2 bytes. This threw off the bytecode reader and eventually led to some runtime
exception that crashed the program. I have fixed it and published a patch for
it as
patch #855085.
I find it had to believe that it took over two years for this bug to surface.
I'm very tempted right now to write a tool that counts the number of times each
instruction is present in a give codebase. With it, I could see if maybe some
other rarely used instruction is also be wrong in
com.jeantessier.classreader.Instruction.
December 04, 2003
Steve Kirk has been having problems analyzing rt.jar
from JDK 1.4.2_01 on Linux. From the error message he sent me, it
seems the bytecode is screwed up. One instruction tries to look up
entry 47105 in a constant pool that has only 445 entries. It would
appear that the compiler generated bad bytecode. In any other
software, I'd believe that. But in the JDK itself? I'll have him
send me the file so I can investigate this myself.
December 03, 2003
Someone brought NoUnit
to my attention. From what little I read, they seem to be using a
.class file parsing library from
NetBeans to get a method call
graph. I guess they then use logic similar to dependency closures to
figure out if methods are called directly from unit tests or if
indirectly, how many degrees are they removed from the tests. Since
they only analyze .class files and then use XSL transforms
for rendering the information, they cannot take into account
conditional logic. As far as I can see, the information can only be an
educated guess at best. I think you'd be better off using a code
coverage tool like Clover or jcoverage to run the tests. Maybe NoUnit
can give a quick estimate since you don't need to run the tests, and
that is worth something.
November 30, 2003
Nominated Dependency Finder for the 2003 Jolt Award at Software Development magazine. When I have a URL for people to use to vote for Dependency Finder, I'll post it here.
November 29, 2003
Release 1.0.1. Of course, as I was closing down, I noticed that I had forgotten one image file. So the new release is not even 12 hours old and it already has a patch. Bummer.
November 28, 2003
Fixed bug #804400. It dealt with "start ..." commands
in both DependencyFinder.bat and OOMetrics.bat
batch files. I added a quoted string right after the initial
start so the shell interprets the executable name
correctly under all circumstances.
Ant's latest version of their list of external tools now includes Dependency Finder. That was quick!
November 26, 2003
Sent a message on Ant's user mailing list to request that they add Dependency Finder to Ant's list of external tools. I'll have to keep an eye on their file to see how long it takes them to include the reference.
Did some code clean up to replace error reporting via system
println() calls with logging via Log4J instead.
I want to revamp the release schedule. I'm going to break it up into smaller chunks so I can have smaller, more frequent releases. I am going to put most of the small, miscellaneous tasks as "unscheduled", that is I will not hold up a release just because of them, but I will work on them as time allows.
November 25, 2003
Used Ant to compile JSPs for dependency analysis. I'll have an
Ant build.xml soon.
November 14, 2003
Someone asked me about a tool to do jar-to-jar dependencies. I've been thinking for some time now about a tool to list dependencies between JAR files, but it hasn't gone beyond being just a thought, yet.
I was about to say that if the project is small enough, you can always do the jar-to-jar analysis manually with the help of some package-to-package reports. I was going to show an example using Dependency Finder, but even this small example ends up being quite big. In the end, I don't think this would work on anything beyond a trivial example.
For example, if I run this against Dependency Finder, I get:
% DependencyExtractor -xml -out df.xml DependencyFinder.jar
% p2p -scope-includes /^com.jeantessier/ \
-filter-excludes /^java/ \
-filter-excludes /^com.jeantessier/ \
df.xml
com.jeantessier.classreader
--> org.apache.log4j
--> org.apache.oro.text.perl
com.jeantessier.commandline
com.jeantessier.dependency
--> org.apache.log4j
--> org.apache.oro.text
--> org.apache.oro.text.perl
--> org.xml.sax
--> org.xml.sax.helpers
com.jeantessier.dependencyfinder
--> org.apache.log4j
com.jeantessier.dependencyfinder.ant
--> org.apache.tools.ant
--> org.apache.tools.ant.types
--> org.xml.sax
com.jeantessier.dependencyfinder.cli
--> org.apache.log4j
com.jeantessier.dependencyfinder.gui
--> org.apache.log4j
--> org.apache.oro.text.perl
--> org.xml.sax
com.jeantessier.diff
--> org.apache.log4j
--> org.apache.oro.text.perl
com.jeantessier.metrics
--> org.apache.log4j
--> org.apache.oro.text
--> org.apache.oro.text.perl
--> org.xml.sax
--> org.xml.sax.helpers
com.jeantessier.text
--> org.apache.oro.text
--> org.apache.oro.text.regex
There are a number of problems:
- There are quite a few packages and a lot of repeated information. If some JARs are quite obvious, like
ant.jar,jakarta-oro.jar, andlog4j.jar, it is not clear where "org.xml.*" would come from. I'm thinking that the JVM would probably get them from itsBOOTCLASSPATH. - It the tool analyzes
A.jar, it will find dependencies on packages outside ofA.jar. It would then be quite difficult, maybe impossible, to find out in which JARs these extra packages are located. The tool would need a mapping of packages to JAR; this mapping would preferably be generated automatically by some other tool. - It is possible to put two classes of a package in two separate JARs. This means that the tool would have to work at the class level instead of the package level.
I'm sorry there is no obvious answer to this problem, but I will keep thinking about it. In the meantime, there are some tools on the Internet that track jar-to-jar dependencies. Just google it. :-)
November 13, 2003
Finished the "about..." box for the GUI. I used Swing and
JOptionPane.showMessageDialog(), the Internal
version was for MDI applications.
Reorganized the release plan. Pushed back documentation and moved unscheduled HTML output forward.
November 12, 2003
Looked at building and "about..." box for the GUI. I started with
the one in JUnit, but it is based on AWT. I think that I may be able
to cook up something similar using Swing instead. I'll start with
JOptionPane.showInternalMessageDialog() and see where it
leads.
November 11, 2003
Fixed the progress bar in the GUI. DependencyFinder
and OOMetricsGUI now scan ahead to count files and classes
and use this information to drive a more accurate progress bar.
November 07, 2003
Svetlin Stanchev brought up the idea of having the web application
produce HTML instead of pre-formatted text. I already have an
unscheduled task for this, so now I must decide whether or not to move
it forward. I could use a dedicated Printer subclass,
like I do for text rendering. This has the disadvantage of
duplicating the logic of rendering a dependency graph to a Java class
and an XSL transformation. But I already did it for the text form, so
there is a precedent ... I'm just not sure it really is a good
thing.
October 30, 2003
Fixed MaximumCapacityPatternCache. It turns out that
Perl5Util use a second cache internally which is
initialized with the pattern cache's capacity. This additional cache
pre-allocates memory proportionally to the capacity, in my case
proportionally to Integer.MAX_VALUE, or about 2 billions.
I changed my cache to use a hard-coded value of 20. That should be
enough to keep things going.
I added my new cache in a few other Perl5Util instances
where they might run into many regular expressions. I had to create a
new package, com.jeantessier.text for the ORO-related
class.
Added xml-apis.jar and xercesImpl.jar to
the web application's WAR file.
Fixed junit.bat and textjunit.bat to use
xml-apis.jar instead of the former
xmlParserAPIs.jar.
October 29, 2003
Svetlin Stanchev requested a variation of the web application that
can read in a dependency graph saved as an XML document. This way,
one can build on one machine, including generating the graph, and only
copy the graph to the web server machine instead of copying all the
classes resulting from the compilation. It sounded like a good idea
and so I added load.jsp to do just that. I might have to
redesign the footer a little and the web app's parameters. One
drawback is that in order to read the XML document, the web application
needs an XML parser. This means I need to add Xerces to the web app,
bumping up the WAR file's size considerably.
By configuring Log4J correctly, Svetlin Stanchev took graph extraction from 6 hours down to 10 minutes. I'm happy about that.
I was trying to analyze the main JAR file of Together Control
Center as an example of working with a large piece of software (i.e.,
with a huge number of classes). I didn't get very far because one
of the classes in the JAR appeared corrupted and broke the whole
.class file loading process. I adjusted
ClassfileLoaderEventSource so it can skip single,
malformed classes without aborting everything. It turns out they used
an obfuscator and it added a text file with a .class
extension, fooling Dependency Finder into trying to parse it like a
regular .class file with bytecode in it.
I gave a shot at Feature Request 825582,
the one about the pattern cache for Perl5Util. I tried
to build a cache based on a simple HashMap with
"unlimited" capacity, but when I use it in
SelectiveTraversalStrategy, I get a bunch of
OutOfMemoryError even from seemingly unrelated areas of
the code. More later...
October 28, 2003
Expanded the documentation for dealing with Ant and XSL transforms. Check out the documentation, under the "Ant Tasks" heading.
As I was preparing a reply to the original call for help, I noticed
that whether or not Log4J is configured properly can have a huge impact
on the performance of the tasks. In one test, running
DependencyExtractor on Dependency Finder itself took over
7 minutes with the missing Log4J configuration versus 14 seconds
with the configuration that ships with Dependency Finder. So if you
find that Dependency Finder is a little unresponsive, you might want
to check your Log4J configuration.
October 27, 2003
The "No more DTM IDs" problem with using Ant's
<xslt> task has surfaced again. I had not given it
any thoughts since last April. The solution is to upgrade Xalan in JDK
1.4.1 or use its java.endorsed.dirs settings. I added
an additional documentation page under "tasks", but I will need to
explain it further and tests workarounds.
Added dependencyfindertasks.properties so defining Ant
tasks is made easier.
October 24, 2003
Svetlin Stanchev asked me to include a property file for Ant tasks
directly into DependencyFinder.jar, and also asked for
more extended Ant documentation. I have had a task on my desk to
provide more process-related documentation for the Ant tasks and
provide examples of how to use them together to provide added value. I
guess it's time I get to it.
Jason Bell, in his JDJ editorial for October 2003, talks about "dependency rot" and how tracking dependencies is critical. I need to make him aware of Dependency Finder! :-)
October 21, 2003
Fixed progress bar notification in GUI. It had trouble dealing with
the processing of nested groups and was getting off track. In doing
so, I ended up renaming events under DependencyListener
and MetricsListener from StartX() and
StopX() to BeginX() and EndX()
respectively. This way, all events follow the same convention. It
could impact people who developed on top of Dependency Finder, I'll
see if it causes an uproar. They should be able to upgrade by simply
renaming their methods and adding empty implementations for the new
BeginSession() and EndSession() events.
October 18, 2003
Added copyright dates to the version information. I will need to do something about the code duplication in all the CLI tools.
I want to nominate Dependency Finder for the next Jolt Awards. I couldn't last year because products needed to have had a major release in the year, but now with 1.0 out and 1.0.1 on the way, I'm in the clear.
October 17, 2003
Someone tried to run a dependency query with an exclusion list that
had over 10,000 regular expressions! On a sizeable codebase, the whole
thing took about 13 hours. They dug around a bit and found that
Perl5Util only caches 20 regular expressions at a time by
default. Their query was taking forever because the ORO engine was
constantly recompiling regular expressions. They entered
Feature Request 825582
at SourceForge.net to request some way to adjust the caching
configuration for Perl5Util.
I added a -version switch to most CLI tools. It
prints version information from the JAR file's manifest and then exits
the tool.
I have a problem with some of the tools that require some mandatory
switches, such as ClassClassDiff and
JarJarDiff. The command-line parser throws an exception
when the mandatory switches are missing, therefore bypassing any
further processing. Right now, I can't do anything about it and the
user must provide the mandatory switches to see the version output. I
see one possible way to handle it. The parser could throw a different
type of exception when mandatory switches are missing. The caller
could catch the exception and still inspect the command-line for the
-version switch. If it is present, the caller could then
print version data instead of usage data.
For the GUI, I want to use an "About ..." box in the menu bar. I will look at the code in JUnit for "inspiration".
October 15, 2003
Someone claimed that ListDocumentedElements was missing
some elements, "whole classes". They wouldn't give me more details.
How can they expect me to find and fix a potential problem if they
won't even help me recreate it? It'd be one thing if they were some
unrelated party working on proprietary code that they can't show me,
but this was a coworker. We work together on the same code. They just
didn't want to be bothered. So if anybody out there ever sees this
too, where ListDocumentedElements is missing some valid
elements, please let me know. Until now, it has worked just fine for
me, so I'll just assume that my coworker had a bad configuration.
October 09, 2003
For a while, I had thought about modifying OOMetrics to
output multiple formats in one call. You could call it with
-csv, -txt, and -xml to generate
all three formats at the same time. And I could do the same thing with
other tools than generate multiple output formats. I finally decided
against. There is very little value in this feature and it would need
broad sweeping changes in the way tools interpret command-line
arguments, such as figuring out the extension for the output filename.
I'll just leave things as they are for now.
October 01, 2003
Adjusted the verbose output in the CLI and Ant packages. I still have to deal with the progress bar in the GUI.
Possible third-party software that might be useful:
| JCharts | SourceForge | graphical charting package |
| JOpenChart | SourceForge | graphical charting package |
| The Big Faceless Java Graph Library | The Big Faceless Organization | graphical charting package |
| The Big Faceless Java PDF Library | The Big Faceless Organization | library for handling PDF documents |
| Japhar | Japhar.org | JVM |
| Kaffe | Kaffe.org | JVM |
| Jeode | esmertec | JVM |
I haven't checked them yet. More on this later.
September 30, 2003
Someone wrote to me saying they had problems with
ListUnused. It was showing their constants as unused.
This is because the compiler inlines them in the bytecode if they are
simple enough. I amended the documentation for ListUnused
to explain this in a little more details.
September 29, 2003
Someone wrote to me saying they had they couldn't figure out the measurements names from their short acronyms in CSV output. I pointed them to the metrics configuration XML document, which lists the long name next to each measurement's short name. I also pointed out that the text and XML outputs list both side by side.
Back when I was preparing version 1.0, I toyed with the idea of having part of the documentation describe each measurement the same way that I have detailed descriptions for each tool in Dependency Finder. I gave up it when I figured that the long names were already fairly indicative and keeping this document in sync with the configuration file would be a lot of work. Maybe I can still add a simple description section in the descriptor...
September 25, 2003
Moved the GUI's LoadListener implementations to use the
new VerboseListenerBase. Instead of mingling it in the
action class, I moved it out into delegate listener classes. Again,
classes should do one thing only, and do it well. A lesson to
remember.
Now that the GUI, the CLI, and the Ant tasks have access to the full group processing stack, I can work on to how use that information in the progress messages.
September 24, 2003
Found some interesting leads for free graphical packages in next month's JavaPro magazine. I will need to look more closely into JChart and JOpenChart. There also seems to be a few packages out there for dealing with PDF files. That could also be an interesting avenue for future development.
That same issue of JavaPro also listed Small Worlds as an analysis tool. I will need to write to them that maybe they should have listed Dependency Finder too. :-)
Moved the CLI's and Ant's VerboseListener classes to
use the new VerboseListenerBase. I aligned their output
to match more closely that of extract.jsp.
Interestingly, I had CLI's VerboseListener extend from
java.io.PrintWriter for some reason. Of course, it made
changing in to extend from VerboseListenerBase instead a
rather interesting experience. Let this be a lesson against inheriting
implementation. Incidentally, the other candidates for extending
VerboseListenerBase are in the GUI and already extend
javax.swing.AbstractAction. I am not sure how I'm going
to deal with this one, yet.
September 22, 2003
I'm rewriting the VerboseListener classes to use the
group tracking behavior I wrote for extract.jsp. I
started by extracting the basis from it and moving it into the
com.jeantessier.dependencyfinder package.
September 18, 2003
Martin Fowler reorganized the articles on his web page, so I had to adjust the URLs on the resources page. Thanks to Vadim Nasardinov for pointing it out.
September 10, 2003
Added an extraction timestamp to the JSPs' footer. I was tired of
always having to manually type the URL to extract.jsp
every time I wanted to know if I could rely on the data.
Someone has mentioned that API diff reports still list modified methods even when the class is deprecated. Would it not be better if a class that is now deprecated simply repress all further modifications to it? I say no. Even though the class is now deprecated, it is still part of your supported API until it is completely removed. As such, its modifications should still be listed since users of the library are likely to still be using the class.
Upgraded my testing environment from Tomcat 4.1.24 to 4.1.27.
September 09, 2003
Looked into using the JSP compiler from Tomcat to automatically compile the web app's JSPs. This way, I can include their dependencies in reports and so forth.
At the same time, I noticed some nice patterns in how to use Ant with external properties files. I might even apply some of them to Dependency Finder.
September 08, 2003
Came up with an idea for a LoadListenerBase that would
handle the group-related events and maintain a stack of group data.
This way, all VerboseListener classes can share that
behavior, including rendering the group stack consistently. This new
abstract base class would include much of the LoadListener
logic from extract.jsp. I still not sure if I should call
it LoadListenerBase or LoadAdapter.
September 05, 2003
Created a release plan for version 1.0.1.
September 04, 2003
Added some links to the resources page.
Semantic Designs, Inc. has a suite of tools to analyze source code, compute metrics, and perform refactorings.
Infotectonica has a tool called Juliet that tracks dependencies and cross-references with a lot of details and a rich query language. It works off of source code and integrates with popular IDEs.
Robert C. Martin came out with a book on software that is gathering a lot of praise. I have taken many ideas from his various papers and presentations. All that material is collected and augmented in "Agile Software Development: Principles, Patterns, and Practices". I just got my copy and I have been going through it slowly. So far. so good. It holds up to expectations.
September 03, 2003
Added MANIFEST.MF to the list of files for the
PermissiveDispatcher to ignore.
Added tests for both PermissiveDispatcher and
StrictDispatcher to increase code coverage.
September 02, 2003
Added a more permissive ClassfileLoaderDispatcher that
tried to use ZipClassfileLoader on files of unknown type.
I also made this new, more permissive dispatcher the new default.
Finally figured out how to use @link tags for javadoc
and fixed the one file where I was using it: the package description
for com.jeantessier.classreader.
Also edited the website's introductory page to adjust some of the phrasing.
September 01, 2003
Fixed backlog in journal entries.
August 31, 2003
Rewrote the web application so that the copyright notice at the
bottom is actually coming from footer.jsp, which gets
included using <jsp:include>.
For the longest time, I have tried to keep the JSPs as simple and self-contained as possible. I figured they would make handy examples of how to use the various parts of Dependency Finder. But now, they are becoming more and more difficult to manage, with all that duplicated HTML between them, and I am not even touching the duplicated code between all versions of the tools. Anyway, I decided to make my life a little easier and at least break out the duplicated HTML to a shared satellite JSP.
August 29, 2003
Adjusted all implementations of LoadListener to handle
the new events. It is still a little quirky and I will need to fine
tune them later.
I also renamed some of the attributes in the LoadEvent.
What was the filename is now called the groupname_ and
what was the element is now called the filename. This
way, the naming reflects more closely the use for these attributes.
I have been considering removing ClassDependencyCollector and
FeatureDependencyCollector. I am not using them anymore,
and CodeDependencyCollector does a much better job.
August 28, 2003
Got all unit tests to pass again, except for those four that deal
with closures. Finished the work on ClassfileLoader. Now
I need to adjust all LoadListener as well as come up with
a more permissive ClassfileLoaderDispatcher that is also
configurable. Maybe another XML descriptor?
August 27, 2003
Finally figured out the flow between ClassfileLoaders. Did most of
the coding for ZipClassfileLoader, which also takes care
of JarClassfileLoader. But I could not get to
DirectoryClassfileLoader, so the unit tests are still
failing.
August 26, 2003
I have been thinking some more about the flow of control to manage to recursively process ZIP-like files. But I can't quite wrap my head around it right now.
August 24, 2003
Wrote the tests for the new events. They are all failing, of course.
August 22, 2003
Came up with a sequence diagram to better understand the
interactions between various ClassfileLoader instances.
This will help me organize the interactions to deal with recursive
processing of ZIP-like files.
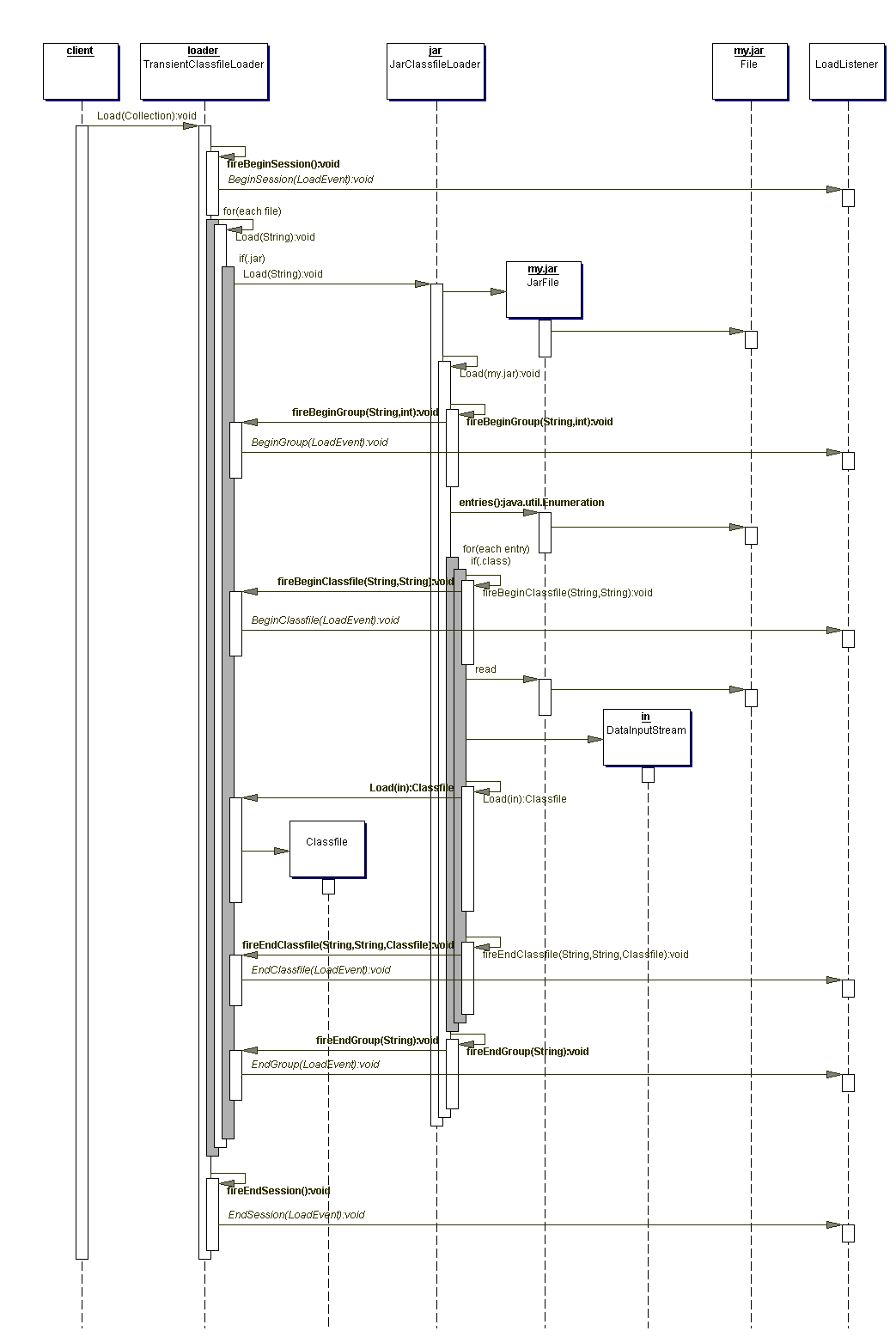
I had to explode the ClassfileLoader instances to show
how the behavior is spread across the inheritance hierarchy. This
yields a cleaner diagram, thanks to the fact that each class is
responsible for one and only one thing.
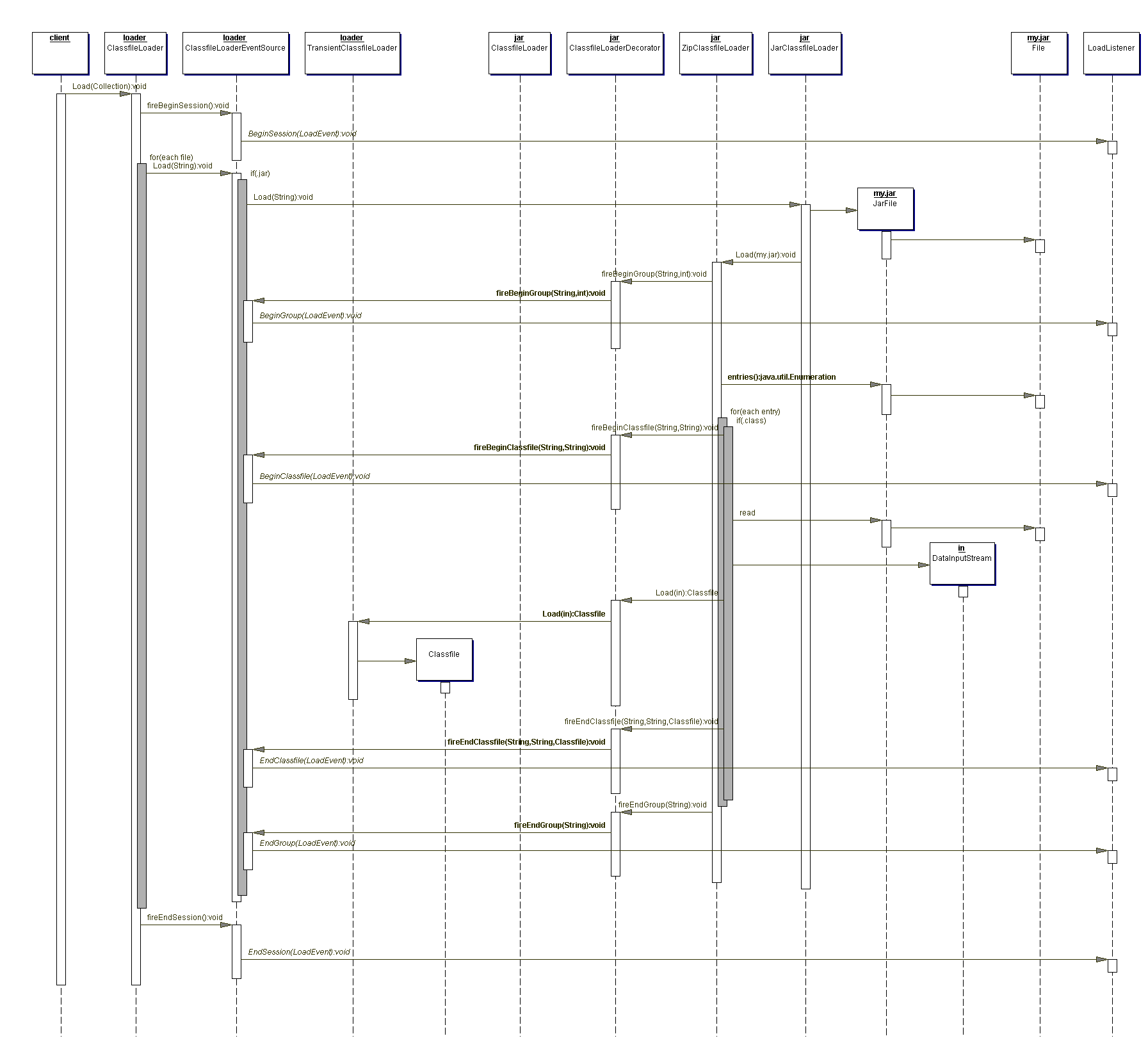
August 21, 2003
Started coding BeginFile and EndFile
load-time events. I also want to automatically expand ZIP and JAR
files, so I can open compound ZIP-like files, such as WAR and EAR,
directly. This will complicate the flow of events, though.
August 20, 2003
When extracting from ZIP or JAR files, the progress reports always
fall short of 100%. I realized that this is because the size estimates
include directory entries and non-.class files. The
progress function only counts .class files, and therefore
always comes up short a bit. So I have added two new load-time events
for when the ClassfileLoader start on a file, regardless
of its extension, and when it is done with a file. These events occur
before and after the BeginClassfile and
EndClassfile respectively.
August 19, 2003
I thought of a new way to use JarJarDiff. So far, I
have talked about how you can use it as a producer of software
libraries to monitor the evolution of the published interface you
expose. But another usage is as a consumer of software libraries,
where you want to know if a new version of the library introduced
changes on the part of the library that you use. I am putting
together detailed instructions on how to use Dependency Finder to
automatically compute which part of the third-party library you are
using and use this information to filter the output of
JarJarDiff. More on this later.
August 15, 2003
Added a BeanInfo helper class to the
Version class. This way, I can use
<jsp:getProperty> tags in JSPs and not have to call
my accessors getX() and setX(). It works on
Tomcat, but I remember having problems with using BeanInfo
with other application servers in the past. I just hope they have made
progress since.
I found a bug (#789373) with using the XSL stylesheet
PublishedDiffToHTML.xsl from Ant with the
<xslt> task. I will have to investigate, but I
should really rewrite that entire stylesheet so it complies with proper
XSL rules. In the meantime, people can use the
<java> task to run Xalan's XSL processor,
org.apache.xalan.xslt.Process, instead. Just make sure
you set fork"yes"= on the task's attributes so that JDK
1.3 VMs pick up the Xalan JAR file. The bug report has a sample Ant
build file that shows how to do it. I will also add it to the
documentation eventually.
Ran JarJarDiff on Xerces and Xalan for the latest
upgrade.
August 12, 2003
Moved the version stuff to its own class, but since it reads
information from its JAR file's manifest, I cannot find a way to test
it properly. The good news is that with its no-args constructor, I
can use it in JSPs with the <jsp:useBean> tag. Next, I will
outfit the CLI tools with a -version switch. And maybe
I can even get an "About" box for the GUI.
On the downside, I am not too sure where to put this new class. It
is in the new package com.jeantessier.dependencyfinder,
soon to be joined by tools to group the cut and pasted code that ends
up duplicated between the CLI, the GUI, the JSPs, and the Ant tasks.
I might even go as far as creating custom tags for the JSPs, or at
least JavaBeans for the parameters to the query, closure, and
dependency metrics engines.
I created a feature request to address the start scripts for Unix (#787904). Since I don't have an environment setup to develop and tests and package on Unix (yet), I am going to leave these scripts in a patch for now. These scripts don't use the contribution from Jonathan Doughty because I am not done studying it, yet. More on this later.
August 11, 2003
Figured a way to get at the information in the JAR file's
/META-INF/MANIFEST.MF entry. I now use it in the web
application's JSPs to generate the "Powered by ..." branding with a URL
back to the Dependency Finder website. I will soon refactor it into a
class I can use with -version switches in the CLI and in
an About box in the GUI.
I tried to use
getClass().getResourceAsStream("/META-INF/MANIFEST.MF"),
but the classloader has to defer to its parent first, before it tries
to resolve anything. So I always go the manifest for the JDK itself.
I had to get the resource URL for the class itself first, and parse it
to extract the path to the JAR file instead, and extract its manifest
via the java.util.jar package.
August 09, 2003
Upgraded the following development components:
Xerces : 2.3.0 -> 2.5.0 Xalan : 2.5 D1 -> 2.5.1
For Xalan, I used the distribution with two JAR files,
xalan.jar and xsltc.jar. I don't need the
material in the second one, so I only ship xalan.jar and
this keeps the size of the distribution down.
August 05, 2003
Published patch for choosing between a GraphCopier and
a GraphSummarizer when running dependency queries. This
new patch (#784040) replaces two previous ones (#776154 and #776161)
and also fixes a bug in ClassReader where it sent its
Printer to the output stream and generated erroneous XML
data.
Found that StatisticalMeasurement.CollectData() was
both synchronized and had a
synchronized block inside that synchronized on
this. This being redundant, I removed the synchronization
in the method signature and kept the internal block. This way, it runs
a tinny bit faster when the data set has not changed.
August 01, 2003
SourceForge download counters are working again.
July 28, 2003
Added a copy-only feature to DependencyReporter (both
on the CLI and the Ant task), DependencyFinder and
advancedquery.jsp. When turned on, the tools always use
GraphCopier to answer queries. This is useful if you
want a class-to-class graph with only inheritance, for instance. I
still have to document this new feature in the manuals.
I added navigation controls to extract.jsp. I was
tired of always editing the URL to go to the query JSP after
extracting a graph. The navigation is the same as on the other JSPs
and I adjusted the title at the top of the page to match that of the
other pages.
July 23, 2003
Thanks to Jonathan Doughty, who donated a Unix shell script for launching the tools in Dependency Finder. I haven't had the time to look at it yet, but I am curious about how he got around to doing it.
Incidentally, for those who wonder, the main reason I don't have a
Unix version of the scripts is not that I don't know how to write them,
but it is that I don't have a convenient environment to build and to
test them. I was thinking of Bourne shell scripts
(/bin/sh) that could discover
DEPENDENCYFINDER_HOME from their invocation path and figure
out the exact name of the class to invoke from their invocation name.
I have a prototype on the SourceForge shell server that dates back to
2003-01-23, but I cannot build a .tar.gz file with symbolic
links in it on my Windows machine, and I don't want to distribute my
build process either. And working via that dreadful SSH terminal is out
of the question. I need three or four launchers to handle the various
patterns in scripts, and symbolic links to create all the scripts.
Since I cannot create the symbolic links at build-time on my Windows
machine, I might have to write a quick install script that creates all
the symbolic links to each launcher. Running it would become part of
the installation process. Jonathan Doughty took a slightly different
approach, so I look forward to comparing what he did with what I had in
mind. Maybe I can get a patch together while we wait for the next
release...
I had put the wrong patch file in patch #776104. I was able to
recreate the correct file and upload it to SourceForge. Luckily, this
patch was very minor and did not address anything that was broken; it
simply removed redundant calls to
java.io.PrintWriter.flush(). I actually considered
removing the patch altogether and keep the fix for a release. Maybe I
will change my mind again at some point in the future. :-)
July 22, 2003
Someone found a bug with DependencyReporter. It does
not close its PrintWriter and ends up truncating the
output. I created a patch for it, after verifying that it was the only
tool experiencing this problem.
I also created a patch for the "refresh" button (a.k.a. "reload") on
DependencyFinder.
I also created a patch for the clean up of calls to
flush() from a while ago.
I cleaned up some indentation text. There were still places where
there were four spaces instead of TAB characters.
About the whole optionally using a GraphCopier thing,
I have been thinking that this functionality really belongs to the
advanced controls and I don't need to clutter the simple controls with
it.
Upgraded my testing environment from Clover 1.1.1 to 1.2.
July 21, 2003
Upgraded my testing environment from Tomcat 4.1.18 to 4.1.24.
July 20, 2003
Regenerated the code coverage output from Clover. Added the code coverage output from jcoverage.
July 18, 2003
Toyed with the idea of using a GraphCopier instead
of a GraphSummarizer again. I could prototype JSPs
very quickly that I'll need to work into CVS. I might also apply
the same logic to the CLI and Ant tools.
July 17, 2003
Fixed the typos in the page on A vs. I graphs.
Added a "reload" button to DependencyFinder. It
re-extracts the last extracted file and clears the result areas in
the GUI.
July 15, 2003
Found some typos in the page on A vs. I graphs.
The GUI could really benefit from a "reload" button. I keep having to do "New" and then "Extract", but that resets the controls, which can have complex regular expressions in them. All this is too tedious.
Again in the GUI, it would be nice to save the results from dependency queries to an XML document for future reference.
July 08, 2003
I'm back.
Suppose you place a query against a dependency graph. You only want
to see class-to-class dependencies. If a method is class A calls a
method in class B, but class A does not refer to class B directly,
there is an implicit dependency A --> B but
not an explicit dependency A --> B. 99% of
the time, you want to see the implicit dependency. But on rare
occasions, you don't. Is that justification enough to add a switch to
the user experience to show only explicit dependencies? The code is
already written; it means using a GraphCopier instead of
a GraphSummarizer to perform the query. This is what the
tools do when the graph is maximized anyway. I think I'll sit on this
one a little while longer. I can always use
DependencyExtractor and look at the raw output for the
rare times I don't want to see implicit dependencies.
June 13, 2003
Someone is having problems with JarJarDiff when their
JAR files are generated by Maven, an Apache tool that looks like a
super-Ant. I'm going on vacation, I cannot look into it right now.
It will have to wait until I return. The problem seems related to
the MANIFEST.MF file, so maybe if they rename the files
to .zip it will bypass that file and work.
Uploaded a patch to fix the extraneous text in the output of
OOMetrics.
June 12, 2003
Minor correction in the documentation of Ant tasks. When defining
the CLASSPATH for Dependency Finder, always put the
classes directory before the
DependencyFinder.jar file.
My download counters are still at zero, but so are others at SourceForge. I suspect that SourceForge has some kind of bug.
I am going to be on vacation for three weeks, starting this Sunday. I will be back around the 4th of July. I still have a patch to produce before that. I will do a 1.0.1 release upon my return.
I have been struggling with rewriting the JSPs and break them up into headers and footers and navigation pages. Maybe even use tags for the processing and JavaBeans for the request parameters. One argument against doing this is that the JSPs provide examples of how to use the classes in Dependency Finder. I'm not fully decided yet.
June 06, 2003
This is my luck. The day after the 1.0 Release I find a number of oversights.
First, OOMetrics still tries to print its printer.
This made sense when the printers contained a StringBuffer
and returned the text as part of their toString()
method. But now, they print directly to the output stream and don't
have a toString() method anymore. The output now has
weird strings in odd places, which actually breaks the XML output.
Second, the version information in the JAR file's manifest is the
stripped version: "10" instead of "1.0". I added additional properties
in build.xml to handle CVS vs. version labels.
Third, some classes call flush() on streams before
closing them, and others don't. The documentation says this is
redundant, so I removed all of these calls.
Added "Powered by ..." statement to all the JSPs. This also gave me an occasion to do minor touch ups in the HTML.
I realized that I ran OOMetrics on non-debug code
yesterday when I gathered metrics for the 1.0 release. This means that
SLOC metrics are way off. I'll have to figure a way to recompile that
version and rerun OOMetrics.
June 05, 2003
1.0!
June 04, 2003
Renamed some of the XSL stylesheets. The names confused me and I always get confused about which one does what.
DependenciesToX-->DependencyGraphToXDependablesToX-->DependablesToXDependentsToX-->DependentsToXListDependablesToX-->HideOutboundDependenciesToXListDependentsToX-->HideInboundDependenciesToX
I have been thinking about an installer that would generate all the
.bat files and adjust them for Windows 98 vs. Windows NT
and JDK 1.3 vs. JDK 1.4. I cannot use Perl because the machine where
you want to install it might not have Perl installed. I cannot write
the installer as a DOS script either because string substitution would
just be too hard, or the Windows 98 version is quite limiting. But I
could make it as a simple Java program. And this way, it could figure
out the JVM version by itself, and even the OS from system properties.
Unless I have an epiphany, I won't delay the 1.0 release for this;
it'll go in the next release.
June 03, 2003
More fixes for the quotes in the .bat file. This time,
I am quite confident that they work fine.
Ad hoc testing of the printer modification show that the memory footprint went down by roughly 80% and the processing time remained pretty much the same. This is nice.
I added a new tool to the web app to provide dependency metrics the
same way that the CLI and the GUI do. I also added navigation controls
to move between graphs, closures, and metrics. In the process, I moved
com.jeantessier.dependency.MetricsReport to a
java.io.PrintWriter instead of a
java.lang.StringBuffer, like I did for other printers
yesterday.
Added the web/ directory to the source archive
DependencyFinder.src.zip.
Fixed com.jeantessier.dependency.MetricsReport that did
not interpret inbound and outbound dependencies correctly.
June 02, 2003
I got a fix for spaces in DEPENDENCYFINDER_HOME. I have not tested it fully
yet, so I need a little more time before I give it my seal of approval.
Someone mentioned they are running out of memory when extracting dependencies
from large JAR files. This is because the various printers use internal
StringBuffer instances that grow as the graph gets rendered. I need to take
one more look at using character streams instead, like I mentioned on
2003-03-12.
I went ahead and modified com.jeantessier.classreader.Printer,
com.jeantessier.dependency.Printer, and com.jeantessier.metrics.Printer to
take a java.io.PrintWriter instead of their java.lang.StringBuffer. The
modifications were quite extensive, and com.jeantessier.diff.Printer is still
untouched. It will need more rewriting than I am willing to deal with at this
time.
May 31, 2003
Someone found a problem with the .bat files. If
DEPENDENCYFINDER_HOME contains any spaces, they don't
work. I need to put quotes around variable uses in each and every
file.
May 29, 2003
I have been thinking about adding another set of JSPs to the web
app to duplicate the functionality in DependencyMetrics.
I am also thinking of putting in a navigation structure to switch
between the query, closure, and now the metrics tools. I would also
like to pass the parameters around so you can run a query in
query.jsp and click on "metrics" to get the dependency
metrics relating to the subgraph issued from the query: number and type
of nodes, number of dependencies, etc. I might put it in the 1.0
release if it does not take too long to do. Now, all I need to do is
figure out how to render a nice navigation structure.
I have also been toying with the idea of a second web app to provide
the functionality of OOMetrics. I'm still not clear if a
separate web app is really required. The main difference between the
two is that the current extract.jsp does not hold on to
parsed .class files. It discards them as soon as it has
extracted their dependencies. The metrics tools read everything in
first and then go about their business. So the memory footprint is
larger, which might become problematic.
May 27, 2003
Added some documentation for the
com.jeantessier.commandline package. I had kept the
main() method on CommandLine as a sample,
but it started to bug me. So I replaced it with actual written
documentation, both in Javadoc and in the developer guide.
May 26, 2003
Memorial Day has come and gone and I was too busy with other things to spend much time with Dependency Finder, let alone do the 1.0 release as I had hoped. In the meantime, the number of daily downloads is still at zero; I must get this release out quickly so the downloads start up again.
May 24, 2003
Made some minor renaming in the
com.jeantessier.commandline package.
It is interesting that since I announced I might do the 1.0 release imminently, there has been no downloads of Dependency Finder. I would like to think that the world is standing still, waiting for this 1.0 release. :-)
May 20, 2003
Worked on the design for the new closure calculator. It will be a little more structured and keep track of each layer as the closure is expanded. This way, I should be able to print actual paths instead of just dumping the graph and let users figure it out. I will also be able to use this calculator in finding the shortest path between two groups of elements (packages, classes, and/or features).
I haven't heard anything about the ongoing beta trial, except for the nasty problem with the ZIP file. I'm thinking of closing the beta and release 1.0 over the upcoming Memorial Day weekend (this weekend). I'll see.
May 16, 2003
I have been looking at the output from Clover. It includes a few metrics, such as:
- Number of classes
- Number of methods
- Lines of code (LOC)
- Non-comment lines of code (NCLOC)
It is interesting to compare them to the metrics from
OOMetrics. First, the number of classes are the same.
But this is where the similarities end.
Second, Clover counts the number of methods explicitly defined in
the source code. Dependency Finder counts all methods in the compiled
.class file, which includes default constructors added
by the compiler and synthetic methods. So the Dependency
Finder count ends up being slightly higher than Clover's count.
Third, Clover's LOC counts all lines in a file, indiscriminate of
whether the line is code, a comment, or even empty. Its NCLOC count
limits itself to lines that actually contain code, but it includes
lines with non-executable code, such as a single closing curly brace
(i.e., '}'). Dependency Finder's SLOC uses information
from the compiler, when it is run with the -g switch, to
count the number of lines with really executable code. It then adds a
few more lines to account for class, field, and method declarations.
It overshoots a little because it even counts implicit constructors and
synthetic elements, but it stays in the ballpark.
| Metrics | Clover | OOMetrics | delta | |||
|---|---|---|---|---|---|---|
| Number of packages | 12 | 12 | ||||
| Number of classes | 275 | 275 | ||||
| Number of methods | 2,642 | 3,609 | +967 | +37% | ||
| Lines of code | 26,544 | (NCLOC) | 24,694 | (SLOC) | -1,850 | -7% |
| 42,939 | (LOC) | |||||
Overall, it is just curious that Dependency Finder comes up with more methods, but less overall lines of code.
May 15, 2003
Finally got around to running
Clover
on Dependency Finder. Overall coverage is at 52.2%. About 16 tests
in the com.jeantessier.metrics package failed because the
code instrumentation from Clover messed with the expected metrics. I
have put the preliminary results
here. I can move the tests for
com.jeantessier.commandline package from the
main() methods to proper JUnit tests. That should raise
coverage somewhat. I'll look further into Clover for what else I can
get from it.
I came across someone who was actually trying to extend Dependency
Finder. This person had downloaded the source code, modified the
classes directly, and recompiled Dependency Finder with the
modifications. While this might have seemed like a good idea, it
will create problems later on when I release an upgrade to Dependency
Finder and this person will have to merge their custom changes with the
new version of the files. It would be much better if they had put
their custom code in separate classes, in their own custom packages,
and compiled them against DependencyFinder.jar. When a
new version of Dependency Finder comes along, they can just drop it
in.
May 06, 2003
Updated the samples to add 1.0 beta data.
I had been having problems with the ZIP files that come out of the
builds. For some reason, I could not see their contents using WinZIP
and could not extract them. Other tools, such as unzip,
jar, and even Emacs did not have any trouble. For some
time, I thought this was a problem between Java-generated ZIP files
and WinZIP 8.1. It turns out that Ant was the culprit. They even had
an open bug report about it. It got fixed in the latest release, but
it is too late for the 1.0 beta release. I hope people can make do
with jar for the duration of the beta. Future releases
will work with WinZIP as expected.
Upgraded the following development components:
Ant : 1.5.2 -> 1.5.3-1
May 04, 2003
Forgot to clean some of the diagrams on the website. All is better now.
May 02, 2003
The good people at SourceForge have removed the stale locks and the 1.0 beta is finally here! Go get it!
May 01, 2003
I was all set and ready to go with the 1.0 beta release and "billfan" strikes again. He keeps locking the CVS repository and keeping me from doing anything in there. This is very frustrating. I tried to contact him, but my emails bounced. Each time this happens, I have to open a ticket with SourceForge admins and wait until the next day for them to get to it and blast his locks.
"billfan", if you're listening, GET OUT OF MY REPOSITORY!!!
Thanks to "billfan", you all have to wait until tomorrow for the beta.
April 30, 2003
Finished the documentation. I added a section for contributors. For now, I feel very paternal about Dependency Finder and I am not quite ready to give up control. I guess I'm more on the cathedral than the bazaar side of things. For those who don't get it, it just means I can be quite stuck up. :-)
I will be releasing the 1.0 beta shortly. Stay tuned.
April 29, 2003
Started playing with a code coverage tool. They gave me a free license because Dependency Finder is open source. So far, it looks interesting; it consists of Ant tasks to instrument code and gather measurements. Check it out on the Clover website. I'll publish the coverage report for Dependency Finder when I have one.
It turns out the problem with Ant's <xslt> is well known. It
is a bug with the version of Xalan that ships with JDK 1.4.1. To fix
it, you have to upgrade the JDK's Xalan; the best way of doing this is
with the java.endorsed.dir property. I'll document it
in more details either in a bug or on the help discussion board.
Dependency Finder is starting to show up on Java indexing sites. Just do a search for "depfind" and find out for yourself.
April 27, 2003
I have been trying to add Dependency Finder tasks to the build
file, but Ant's <xslt> tasks has problems with some of the XSL
transformations. At least DependenciesToHTML generates
and error about "not enough DTMs", whatever that means. I can still
run the transform with the CLI script, so I will have to investigate
some more.
I just need to add a legend to the diagrams for
JarJarDiff and write up the project's policy regarding
code contributions. Then I can release the beta.
April 25, 2003
Redrew the diagrams for JarJarDiff.
April 23, 2003
Finished the equivalence table. In the end, I decided to put it in the manual.
April 22, 2003
Added TOC elements to PublishedDiffToHTML.xsl, so it
looks more like DiffToHTML.xsl.
April 21, 2003
Took a break for a few days, but now I'm back and bent on getting the beta out. I need to build some kind of equivalence table for features between the CLI, GUI, Ant tasks, and web app. I don't know quite where to put it. One place might be as part of each tool description in the tools docs, but that spreads it a little too much. I might just go with a table in the manual instead.
After this, I should be done. The Beta is near!
April 11, 2003
Completed Ant task documentation.
April 09, 2003
Added status messages in the processing of Ant tasks.
April 07, 2003
Ant task documentation.
When I changed PrettyPrinter to
TextPrinter, I forgot to update the JSPs. This is now
fixed.
April 05, 2003
Ant task documentation.
April 02, 2003
Ant task documentation.
March 31, 2003
Wrote the Ant task for ListDiff. Just a little more documentation for the Ant
tasks and the beta will be ready.
Fixed a typo in the license's text. I went to check it all in, but the same person who locked the CVS repository on 2003-02-10 has locked it again. I logged a bug report with SourceForge.net, but it might be up to 24 hours before they break the stale locks.
March 29, 2003
I decided not to make an Ant task for ClassReader, but
I will need one for ListDiff to complete the workflow
outlined in the manual. Now I'm going to pay for not separating behavior
properly. ListDiff has all the behavior and a utility
class that is in the com.jeantessier.dependencyfinder.cli
package. How am I going to reuse this from the
com.jeantessier.dependencyfinder.ant package?
March 27, 2003
Wrote the Ant task for OOMetrics.
March 26, 2003
Wrote the Ant task for DependencyMetrics.
March 25, 2003
Wrote the Ant task for DependencyClosure.
Cleaned up some of the documentation.
March 24, 2003
Finished the Ant task for DependencyExtractor and
also wrote those for ClassMetrics,
DependencyReporter, and JarJarDiff.
I decided to stick with the Ant naming convention and use
destfile for the output attribute.
Introduced a new tool, ClassClassDiff, which compares
two classes, even if they don't have the same name. I found a need
for it when a renamed one class to work on temporarily and wanted
to see later on what differences I had introduced. The class was
too large for me to do this with regular diffs.
March 23, 2003
Wrote Ant task for DependencyExtractor. It turns out
that using a path-like structure is actually easier than extending
MatchingTask. I hesitate about the name of the
attribute for the output file. The other tools use out
but Ant recommends destfile instead. So do I make it
consistent with other Dependency Finder tools or with other Ant
tasks?
March 21, 2003
Getting familiar with writing Ant tasks.
March 20, 2003
Tech docs for the developer guide. Added an additional reference
to the OOMetricsGUI screenshot for after the extract.
March 19, 2003
Had a bout with the flu.
Jeff Harman asked questions about dependency visitors and such, which prompted me to document that control flow a little more. I'll add the new information to the fledgling developer guide when I get a change and when I can find a decent (free) editor for UML diagrams.
Had some ideas about correlating project size and complexity and estimating each via the current metrics. I might be able to do something about complexity with a combination of intra-class, intra-package, and extra-package dependencies at both the class and method levels.
March 12, 2003
Gave some more thought to having Printer work off a
java.io.Writer instead of a StringBuffer.
This would lessen the burden on memory by streaming large graphs
straight to file or output stream, but the character conversion might
add processing overhead. The design below separates formatting of the
text by DecoratorPrinter from how that text is actually
saved by FilePrinter and StringPrinter. The
latter behaves like the current Printer so I can compare
both approaches. But beyond that, it makes little sense since I could
just as easily pass a java.io.StringWriter to the
decorator.
This first scenario shows saving to a file. Saving to an output stream would look just the same.
This second scenario saves the graph to an in-memory string, though
I could just as easily do the same with a
java.io.StringWriter.
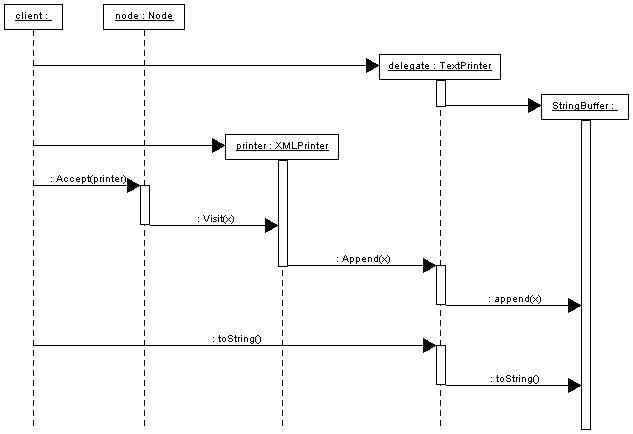
This design looks like overkill, since FilePrinter and
StringPrinter end up with empty implementations for their
VisitX() methods. In fact, they don't even need to be
related to Visitor at all since they are not accessed
directly by the client code. If I am going to define a new interface
for them, I might as well simply use java.io.Writer.
I will probably just replace the StringBuffer in
Printer with a java.io.Writer and be done
with it.
I'm not too happy with the way the sequence diagrams came out too, but that's the fault of the tool I've been using. And even the class diagram has undesirable artifacts. I have no budget for this project, so I could not use the one I would have really wanted. And the one I ended up using was quicker to use than a plain drawing editor.
I also kept looking at the new Xerces and Xalan. All the unit tests
are passing, but PublishedDiffToHTML prints nothing when
I pass it a validation list. I must figure out if this is due to the
new Xalan or the test data. I tried a couple of code samples, but they
are still too large for me to track exactly what is going on.
I upgraded the libraries anyway, I will figure out the kinks later:
Xerces : 2.2.1 -> 2.3.0 Xalan : 2.4.1 -> 2.5 D1
March 11, 2003
Created some UML diagrams for com.jeantessier.dependency
and com.jeantessier.metrics packages. As I'm trying
to describe the internals of dependency graphs to Jeff Harman, I
figured they would come in handy.
March 10, 2003
Still investigating Xerces/Xalan upgrades. Having troubles with
PublishedDiffToHTML; for some reason, it prints out
nothing.
Was approached by Jeff Harman about writing dependency graphs to database. This could be the first contribution to the project that did not originate from me! I'll let you know how it turns out.
March 09, 2003
Still investigating Xerces/Xalan upgrades.
March 08, 2003
Looking at upgrade for:
Xerces : 2.2.1 -> 2.3.0 Xalan : 2.4.1 -> 2.5 D1
I need to investigate how this will impact usage with JDK 1.4.
March 06, 2003
Upgraded the following development components:
Log4J : 1.2.7 -> 1.2.8 Jakarta ORO : 2.0.7-dev-1 -> 2.0.7
March 05, 2003
Fixed TableHeaderListener so the tooltips in table
header display correctly. It wouldn't change the tooltip when you
moved the cursor between columns within the header. I had to put
the tooltip login in mouseMoved() instead. My current
use of this treats the whole header as one large component.
Then further tweaked the text of the tooltips, adding the range information even to column headers and enhancing the tooltips' descriptive quality.
Refactored the text rendering of StatisticalMeasurement
and centralized it. This may change some more since I am not too
fond of mixing application logic and presentation logic, but I don't
have a better place at this time.
Fixed the named scope of two measurements in the default metrics configuration. There were mistakenly labeled per group when they are in fact per class.
March 04, 2003
Added tooltips to OOMetricsGUI. Column headers show
the measurement's full name, cells show the element's name,
measurement's full name, abbreviation, and value.
Removed the documentation of metrics and measurements. With the new tooltips, it is not all that necessary anymore.
I thought of putting a target in build.xml to
update the codebase from CVS, but I had trouble getting it to work
on Win98 and to authenticate properly, so I just dropped it.
Only the Ant tasks left. I've had some ideas about extracting
the cut & pasted code in the tools and put it in central tool classes.
The Ant tasks would just be another way to invoke those tool classes.
So far, they would be in a new
com.jeantessier.dependencyfinder package.
March 03, 2003
Finished tools docs.
Removed useless -dispose switch to
OOMetrics.
February 27, 2003
Tools docs.
February 21, 2003
Removed -plain and -raw switches
from ClassReader, DependencyExtractor,
and DependencyReporter. Their output was not adding
any new information and looked ugly.
Fixed MetricsTableModel.
DependencyFinder uses it to render dependency
distributions in a JTable. A small glitch was making
it miss the last row of data. I also renamed
com.jeantessier.dependency.MetricsGatherer.ChartSize()
to
com.jeantessier.dependency.MetricsGatherer.ChartMaximum().
Normalized naming of human-readable text printers from
PrettyPrinter to TextPrinter. In
com.jeantessier.dependency, I had to merge the two
classes. I also got rid of
com.jeantessier.dependency.UglyPrinter. As a
result, I could get rid of -plain and -raw
command-line switches and simplify the output of
ClassReader, DependencyExtractor, and
DependencyReporter.
Tools docs.
February 20, 2003
Tools docs.
Figured out how to get Ant's <cvsTagDiff>
task work from "now" instead of "last midnight". It turns out
that adding the time to the date screws up how Ant generates
the resulting CVS command. There is an open bug report with
Apache, so maybe they'll fix it in the future. While we are
waiting, I had to add the quotes in the tag's attribute myself.
I'm thinking of getting rid of the -plain switch
to some of the CLI tools. It is useless. I should be able to
get rid of com.jeantessier.dependency.TextPrinter
by the same token. We'll see about this last one.
February 19, 2003
Tools docs.
Added an HTML index page to the documentation directory.
Got rid of the -trace command-line switch. If
you want that level of details, edit log4j.properties.
Reworked the -verbose command-line switch. It
prints progress as files are read and data is created, kind of like
the status bar in the Swing applications. The tools use the new
VerboseListener to trap events and print them to the
specified output stream or file. This has helped simplify the
code around main() in the tool classes.
Considered optimizing event sources so they don't do anything
if there are no registered listeners. With the new mechanism
for -verbose, there is always at least one listener,
this optimization is therefore useless, so I dropped it. For it
to make sense, I would have had to complexify the life cycle of
VerboseListener too much.
Added IntelliJ IDEA and Xrefactory to the resources page.
February 18, 2003
Tools docs.
Rewrote the intro page for the website. I thought it needed some words of encouragement to prospective users as to why they should use Dependency Finder instead of the other available solutions.
February 17, 2003
Tools docs.
February 14, 2003
My JavaOne proposals were not picked up. :-(
After I launch the beta, I'll work on some articles.
February 13, 2003
Tools docs.
February 12, 2003
Tools docs.
February 11, 2003
SourceForge broke the locks on the CVS repository and I was able to check in the minor improvements to the JSPs.
February 10, 2003
Used onMouseOver and onMouseOut
JavaScript event handlers in the JSPs instead of onFocus
and onBlur respectively. This way, the hints appear
in the status area as the mouse goes over each field and the
user does not have to click into them, or use TAB
to move between them and see the hints.
Fixed the tables in the JSP so they show up correctly in
either Mozilla or IE. Lucky I recently learned about
<tbody> and <colgroup>
tags.
Someone locked the CVS repository for the project. I tried to contact them through SourceForge, but the email bounced. I opened a trouble ticket with SourceForge in the hope they can blast the lock themselves.
Added tasks in build.xml to convert the text files
that make up the documentation to HTML. I also added by conversion
perl script, bin/txt2html.pl. It is finally under
source control. I had to adjust the dist target so it
does not include it in the distribution.
I realized that someone made a feature request on the SourceForge
project page. This is the first time in over a year that Dependency
Finder has been open to the public. The request is for Ant task
equivalents to the CLI tools. This should be easy enough. All the
XSL transforms can already be done with Ant's <xslt>
core task. For the other tools, you could use Ant's
<java> task and pass in the equivalent parameters.
But I think I will go one step further and actually create a new
package with classes that extend
org.apache.tools.ant.Task. I will add sample usage in
the Manual. Thanks to Andy Laun for a great proposal.
February 06, 2003
Tweaked the website.
The tables for the controls in the JSP do not come out correctly in Mozilla. The frames are missing. I will have to rewrite them so that they show up correctly in either Mozilla or IE.
February 05, 2003
Finished the User Manual.
February 04, 2003
Updated the example for LinkMinimizer and
LinkMaximizer and merged it with the User Manual.
I also had a idea to use a Writer in the various
Printer classes. This would ease the resource needs
of various command-line operations since the tools would not need
to hold all the output in memory. Anyway, I'm just thinking about
it at this time.
February 03, 2003
Added an icon to DependencyFinder and OOMetricsGUI.
February 02, 2003
Quick comparison of minimized vs. raw vs. maximized graphs.
February 01, 2003
Tech docs.
January 30, 2003
Fixed table colors for OOMetricsGUI.
January 29, 2003
"Refactorings" Happy Hour.
January 28, 2003
Rewrote part of A vs. I study.
Reorganized the menu for the website.
January 27, 2003
Added an analysis study of Robert Martin's metrics, as described in Robert C. Martin's Design Principles and Design Patterns article.
Also added output from
<cvsTagDiff> tasks in Ant that list files
that changed between release.
January 23, 2003
Played with SourceForge resources. Someone mentioned that I might be able to use SourceForge shell server to test Unix launch scripts. The shell server does not have compilers and connecting through SSH is tedious, so I will not do this on an extended basis. But I did setup the website as a checkout from CVS. Now I need to figure out how to setup the cron job so it updates itself automatically.
I think I've got it...
Yup.
January 22, 2003
Tech docs.
January 21, 2003
Tech docs.
January 20, 2003
Changed initial status message in
MetricsExtractAction and
DependencyExtractAction to account for long
waiting time while DirectoryExplorer scans for
.class files.
I was having problems with SumMeasurement
today. I added trace statements to track down what was going
on and it started going haywire. Took me a while, but I
realized its Compute() method was not thread-safe.
I synchronized its processing and it is now fine. I looked at
the other measurements and NbSubMetricsMeasurement
was in the same situation. I fixed it too.
I noticed that cut & paste of values in
OOMetricsGUI were coming through as calls to
toString(), yielding the default stringification
from java.lang.Object. I added an implementation
of toString() to MeasurementBase so
that measurements print their numerical value by default. It
works well, except for StatisticalMeasurement
which ends up displaying itself five times.
Added standard deviation subvalue to
StatisticalMeasurement.
Added an InRange() method to Metrics
that returns false if any of the measurements is not
in range.
January 19, 2003
Found a way to separate between visited and non-visited
methods, classes, and groups by keeping separate lists in
MetricsFactory.
January 18, 2003
Looked at ways to restrict listed metrics to the classes and
methods actually visited, instead of all referenced elements. I
tried to distinguish between getting a metrics and creating it
only as part of a VisitX() method, but that didn't
work since metrics would only start accumulating after their
call to VisitX(). I'll have to try something else.
January 17, 2003
Tech docs.
Looked into Poseidon for UML, Community Edition, to generate UML diagrams of Dependency Finder for the documentation. It still has a few quirks, but hey, it's free.
January 16, 2003
Tech docs.
January 15, 2003
Tech docs. I started a developer's guide.
January 14, 2003
Tech docs.
January 13, 2003
Found and fixed bug #667642 about MetricsFactory not
recognizing static initializers of the form "static {}".
Switched log4j.properties to use CHAINSAW instead
of log files.
Found another article on Small Worlds. This time, it was a review in Software Development Magazine.
The more I think of it, the more I was to revamp
-verbose and get rid of -trace
switches. I'll have -verbose behave somewhat like
extract.jsp or the status bar of the GUI tools.
January 11, 2003
Upgraded my testing environment from Tomcat 4.1.12 to 4.1.18.
January 10, 2003
Tech docs.
January 01, 2003
New release!
Updated the copyright notice for the new year.
December 30, 2002
I now have progress bars on the GUIs!
I am going to do one more release before the beta, either tomorrow (12/31) or the day after (1/1). Like I said before, this will let people out there use the new features and bug fixes without having to wait on the user guide.
December 28, 2002
Fixed all the broken unit tests for metrics.
Added metrics-processing events so the UI can track
progress in OOMetricsGUI.
For a while, Jakarta ORO had two versions of
Perl5Util.split() that differed in how they
split the empty string "". They seem to have fixed the
discrepancy in their latest version, so I moved my code
to the new version that uses java.util.Collection
instead of java.util.Vector, which is
deprecated.
December 27, 2002
Finally got to fixing the broken unit tests, for metrics, at least.
It turns out that JDK 1.4 is doing some funny accounting
for line numbers in try ... catch blocks and this fixes some
inaccuracies in my SLOC estimation. These changes in the
generated bytecode will help debuggers step through these
clauses with more meaningful feedback. By removing the
special accounting in MetricsGatherer, the SLOC
count of code compiled with previous versions of the JDK
will be slightly underestimated. But it is a rough estimate
to begin with, so I guess it is safe.
I am going to standardize the tests for JDK 1.4 and the way that it generates bytecode. In the future, I might put special instrumentation in the tests to detect bytecode that has been compiled with previous versions of the JDK, but it is not a priority for now.
December 26, 2002
Finally got around to checking that the upgrade to Xalan did fix bug 13106. It works, but I must still rewrite the stylesheet to comply with XSLT rules.
December 21, 2002
Refactored
com.jeantessier.dependencyfinder.gui.DependencyFinder.
Also refactored some of the metrics handling code to simplify processing of multiple measurements.
December 19, 2002
I have been thinking some more about the progress status and what information would be displayed in a dialog, such as elapsed time and a guesstimate of how much more time will be required.
December 11, 2002
More refactoring for the ClassfileLoader event
model. I've added a concept of session, basically a call to
Load(Collection). This will allow me to start
measuring how long extraction is taking and maybe even make an
estimate has to how much longer it'll take. In the meantime,
I have "percent completed" measurement in place.
I'm thinking of having one more release before the beta. This would let people out there use the latest features and bug fixes without having to wait for the user guide. One thing that I would like to release quickly is the new, simpler user interface.
December 10, 2002
Refactored ClassfileLoader and its subclasses.
The decorators are now hidden inside the
ClassfileLoaderEventSource class, so clients of the
package don't have to bother with which decorator to instantiate.
This paves the way to including progress measurements in the
LoadEvent passed in LoadStart() and
LoadElement() events. This way, I can have either
a "percent complete" or a progress bar as things are loading.
I might even be able to have an elapsed time and a predicted
remaining time.
Documented the methods of LoadListener, but I
must revise the description of the various attributes and under
which cases each one has a value.
December 06, 2002
Refactored CanAddDependency().
Fixed references in slides for the tutorial. I need to think about this before I publish it on the website. I used the slides from a previous presentation, but this would mean that I would have to come up with some new material if my submission to JavaOne is picked up. Then again, I would have to come up with some new stuff anyway!
December 05, 2002
Worked on tools documentation.
Found a bug with GraphSummarizer. I describe it
fully on SourceForge; it is bug
#649375.
Basically, when adding dependency between nodes from two different
node factories, such as in GraphSummarizer, the logic
that prevents self-dependencies relied on all classes of a package
being present, which may not be the case while summarizing a graph.
I rewrote the validation logic in Node and its subclasses
to use a template method instead. Since it does not rely on list
traversal anymore, it should speed things up a bit (but I have not
tried to measure it).
Relabeled the beta from "0.1 beta" to "1.0 beta 1". It might have a little more appeal, so more people will try the software.
December 04, 2002
Worked on tools documentation. Got rid of original
Tools.xml, copied the information so far into
Tools.txt. Pretty soon, I will have to put
the Perl script generator under source control too.
December 03, 2002
Checked in a bunch of changes that were just accumulating on my machine.
Upgraded the following development components:
Xerces : 2.2.0 -> 2.2.1 Xalan : 2.4.0 -> 2.4.1
The upgrade to Xalan should have fixed bug 13106. I'll check it out tomorrow.
December 02, 2002
Worked on tools documentation.
November 26, 2002
Finished the generator and generated a template for documenting the tools that make up Dependency Finder. Now, I must fill in the template.
I'm afraid that I must forget about the Jolt Awards this year. No way I can get an official major release out before December 31. But next year, for sure.
November 25, 2002
Started working on a generator for a template for
documenting the tools that make up Dependency Finder. I am
using a Perl script to scan the bin/ directory
and automatically generate information about each script.
When I am done, the template will use the same kind of
annotation that I have been using for the user guide.
This way, I can use the same translator for both files to
convert them to HTML. At first, I thought of generating
XML and then use XSLT to convert it to HTML, but managing
XML with embedded HTML tags proved too much. This way,
the notation is simpler and the embedded HTML does not get
in the way.
November 21, 2002
Technical documentation.
Fixed some minor bugs in how I generate the manual.
November 20, 2002
Submitted a proposal for the Spotlight on Open Source column in Java Developer Journal.
Found an article on dependencies titled Managing Java Source Code Dependencies for SCM in Java Developer Journal, vol. 7, no. 11, November 2002. It deals mainly with compile-time dependencies and keeping track of components under revision control, but still makes a few good points regarding dependencies in general.
Fixed some minor bugs in how I generate the manual.
November 19, 2002
Technical documentation.
Discovered another free tool that deals with metrics:
JavaNCSS.
It includes two measurements: McCabe's cyclomatic complexity
and its own non-comment source statement. I really need to move
com.jeantessier.metrics off of the Visitor pattern
and let people code and add their own measurements.
I looked up McCabe's cyclomatic complexity and it shouldn't be too hard to implement. It's basically just a matter of counting specific instructions.
Found another, older article by Robert C. Martin about his "distance from the main sequence" dependency metric.
November 18, 2002
Technical documentation.
November 12, 2002
I worked out the design of a new TransitiveClosure
that uses breadth-first search through the dependency graph.
It is not based on com.jeantessier.dependency.Visitor
and uses the Strategy pattern to decide how far to go from the
scope, either up to a given path length or unbounded, with
separate strategies for following inbound versus outbound
dependencies.
I also laid out the design for a scope selector to help with computing transitive closures on non-maximized graphs. This will also come in handy for the next item today.
I have also outlined the algorithm for finding the shortest paths between two groups of nodes, using the engine that computes transitive closures. By growing closures from both groups, one following inbound dependencies and the other following outbound dependencies, and growing them until I have a non-empty intersection, I will get a subgraph that contains all the paths from A to B with minimal length. I can use the scope selector described above to select source and sink groups.
I also found out that Software Development magazine is taking nominations for its Jolt Awards. I'm going to submit Dependency Finder. But they don't want betas, so I will have to push up my release schedule. I'll have a very short beta period and a release in December. ;-)
November 11, 2002
I have been catching up on graph data structures and their
operations by reading my old college textbooks again. I was
pleased to see that my implementation of dependency graphs was
not too far from implementations they discuss in the book. I
was also pleased to see that TransitiveClosure uses
a depth-first search algorithm, but the breadth-first search
algorithm in the book is more in tune with what the class is
trying to do. I will write a breath-first class when I get a
chance.
The book also has an algorithm for finding a path between two vertices (nodes) in a graph. I will modify it to find paths between two groups of vertices.
Before I forget, the books are:
- "Data Structures and Their Algorithms" by Harry R. Lewis and Larry Denenberg
- "Data Structures in Java" by Thomas A. Standish
- "Data Structure Techniques" by Thomas A. Standish
- "Algorithmique: conception et analyse" by Giles Brassard and Paul Bratley
This last one was written by teachers at the Université de Montréal, where I went to school.
November 09, 2002
Wrote a new unit test for TransitiveClosure.
Right now, it requires a maximized graph to be useful. I want
to have it accept any graph, like I did for GraphCopier
with GraphSummarizer.
Running the tests reminded me that I still have a bunch of unit tests for metrics to fix, with regard to the fact that I moved to JDK 1.4.
November 08, 2002
Found two references to Perl regular expressions in Java. I will be able to point people to them in the manual and the JSPs. This will help with teaching people how to use the regular expressions to get them data they want.
org.apache.oro.text.regexin Jakarta OROjava.util.regex.Patternin JDK 1.4
I will also write a more decent samples section in the manual. The current one is rather laughable.
November 07, 2002
Submitted another session for the next JavaOne conference. This one is about JarJarDiff and API evolution management. I also got someone from work to give first hand experience of how this stuff is used as part of an actual development process.
November 04, 2002
Submitted a session for the next JavaOne conference. I used the presentation from 2002-10-23 as the basis. I might add sessions for JarJarDiff.
I will use the presentation's slides for the tutorial. I must get back to finishing the manual, too.
October 31, 2002
Got some new ideas on fixing the serialization of dependency
graphs. I can separate the nodes from the dependencies and put
everything in a Graph-like object. Each dependency
would become its own object, allowing me to record additional
information about each dependency such as its type (dependency,
association, generalization, realization) and weight (how many
times it occurs in the code).
Looked at possible graphical renders for metrics.
October 27, 2002
Manual.html now has a table of contents and
named anchors for each section title for easier reference.
The web app now has an error page. The next step will be to have invalid regular expressions reported within each JSP instead of shifting context to this special error page.
October 26, 2002
Write out AccessField values as bit sets.
October 24, 2002
Got some more ideas regarding layout of dependency graphs.
Found interesting thing that JDK 1.4's javac
does with method calls. The bytecode now points to the actual
type of the reference now, instead of the last class in the
inheritance hierarchy to implement the method.
Cleaned up com.jeantessier.classreader.XMLPrinter
to better print field accesses and method calls.
Added manifest information to the JAR file.
October 23, 2002
Presentation went well. Two questions:
When will there be a graphical representation? This is a tough one to crack; it will require a lot of work.
Why Perl regular expressions? Because they are quite powerful and the only regular expression syntax that I bothered to learn a long time ago.
October 22, 2002
Worked on the PowerPoint presentation some more.
October 21, 2002
Started PowerPoint slides. When I am done, I will use them for the tutorial item on the release plan.
October 19, 2002
Drafted talk for this Wednesday. 34 pages and counting.
October 18, 2002
Will present Dependency Finder at work on 2002-10-23.
October 17, 2002
I'm planning to populate the manifest.mf
file in DependencyFinder.jar. I will also
put in code to printout version info, including versions
of all 3rd party JARs.
October 16, 2002
Added usage hints to controls in web app JSPs. I also changed the look and feel and put it in an external CSS2 stylesheet. It looks great in IE 5.0 but Netscape 4.7 has trouble with the table that encloses controls. The JSP works, it just doesn't look as great. I'll worry about it later.
Added the same usage hints to controls as tool tips in
the Swing version of Dependency Finder and
OOMetrics.
Created a CSS stylesheet for this website.
Upgraded the following development components:
Log4J : 1.2.6 -> 1.2.7
October 15, 2002
Further simplified the default settings in
DependencyFinder and query.jsp.
The new defaults print the entire package-to-package
dependency graph, as opposed to the entire graph like
it was doing before. This is so that new users, as they
start using the interface, can simply launch a query and
see something useful without using all the memory available
to render an immense graph.
I will expand the manual to include a tutorial with sample queries and their results.
There was a rendering problem for JTable
under JDK 1.3. I try to group rows in bands of three with
alternating background colors. For some reason, under JDK
1.3, the cells in column 0 would not get the right background
sometimes. This problem is gone under JDK 1.4. Since this
is not breaking any functionality (it is just annoying), I
will recommend that you upgrade your JVM if it bothers you.
October 14, 2002
I'm dropping support for JDK 1.2.2. I upgraded my JDK 1.3 from 1.3.101 to 1.3.105. I also started playing with JDK 1.4.
This is interesting, now. JDK 1.4 ships with some basic
XML support, including a version of Xerces. But it looks
like it's an older version than the one I'm using, because
it requires me to explicitly specify the system property
org.xml.sax.driver. I need to dig further to
figure out which version they're shipping and how I can
force it to use the latest Xerces that I ship with
Dependency Finder. Maybe some day, in the far future, when
I don't support JDK 1.3 anymore, I can stop shipping Xerces
with Dependency Finder altogether. But for now, I'm stuck.
Maybe I can weasel out of it by requiring users to install JAXP 1.2 from Sun. The documentation claims that JDK 1.4 ships with JAXP 1.1. Maybe JAXP 1.2 uses something close to the latest Xerces; and it also includes Xalan! I will investigate further.
Also, the compiler in JDK 1.4 behaves slightly differently from the one in JDK 1.3. The result is that the unit tests are breaking because the compiled classes don't have the same number of features. I will have to either revert back to JDK 1.3 or update the unit tests. I haven't quite decided yet, but I'm leaning towards the latter.
I also seems that JDK 1.4 has problems with Log4J too. More on this later.
Upgraded the following development components:
Xerces : 2.1.0 -> 2.2.0
October 11, 2002
I did a quick check to see if I can still compile
Dependency Finder with JDK 1.2.2, but I can't anymore.
I use java.util.Collections.singletonList() in
com.jeantessier.commandline.MultipleValuesSwitch
and a new constructor for
javax.swing.JRadioButtonMenuItem in
com.jeantessier.dependencyfinder.gui.DependencyFinder
that takes an instance of
javax.swing.Action. Given the context in
which these happen, I don't see how I can write around
them in a clean way.
So I'm probably just going to drop support of JDK 1.2.2 and ask people to use Dependency Finder with JDK 1.3 and above.
October 10, 2002
Everybody at work is asking how to use Dependency Finder. I guess I need to work on usability and the intuitiveness of the user interface.
Also, maybe the default settings should not try to print the whole dependency graph. The two instances my colleague deployed have over 50,000 nodes and the JVM runs out of memory trying to render them. A think a default of package-to-package dependencies might be better.
Here, I need to choose between default settings that make it non-threatening to newbies versus settings that people use most of the time, so the tool is quick to use, without having to flip the same switches all the time.
October 09, 2002
Maybe I could submit papers for sessions at JavaOne.
A colleague deployed two instances of the Dependency Finder web app for us to use.
October 08, 2002
Moved article outlines from paper to Word.
October 06, 2002
I may have found suitable examples on how to rewrite
PublishedDiffToHTML.xsl in Michael Kay's
book on XSLT.
October 04, 2002
The good folks at Xalan fixed
bug 13106.
They pointed out that I violate an XSLT rule when I reference
validator instances in match clauses of
<xsl:template> tags. It has been working
until now because Xalan is lenient, but there is no guarantee
that it will do so in the future or that the stylesheet will
work with another XSLT translator. I will need to rewrite
the stylesheet to use <xsl:if> tags to do
the validation.
Wrote two outlines for articles or white papers on Dependency Finder and JarJarDiff, respectively.
October 01, 2002
Adjusted classfile.dtd and
com.jeantessier.classreader.XMLPrinter to make
the <interfaces> tag under
<classfile> optional. This is to make
it consistent with the other "optional" sections for
fields, methods, and attributes.
September 30, 2002
Adjusted classfile.dtd and
com.jeantessier.classreader.XMLPrinter to make
<fields>, <methods>,
and <attributes> tags optional. This is
to account for backward compatibility and make the resulting
XML documents a little simpler.
September 27, 2002
Found a deficiency with
com.jeantessier.classreader.XMLPrinter: it
is not printing attributes of class fields. I opened
a bug about it,
bug #615616.
I used the Inherited Behavior design pattern to normalize
the handling of attributes across implementations of the
com.jeantessier.classreader.Visitor interface.
This solved the bug, but I had to change the DTD for
classfiles. I don't know how that will impact validity
of outputs once I change it the web site that the tools
point to by default.
I worked out the problem with
PublishedDiffToHTML.xsl. If I use the full
notation for Xalan extensions instead of the abbreviated
one for Java, it works just fine, even with Xalan 2.4.0.
So I will upgrade back to Xalan 2.4.0. I opened a bug
with the Xalan folks:
Xalan bug 13106.
September 25, 2002
Found a problem with Xalan. For some reason, it won't
recognize my extension for PublishedDiffToHTML.xsl
for the Validator. It used to work just fine.
I can't find anything in the documentation regarding
changes on to specify extensions. The release notes hint at
improvements regarding detection of extensions, but there are
no specifics.
I have downgraded Xalan from 2.4.0 back to 2.3.1.
I've had an idea for a new web app where people can upload their JAR files and whatnots and get custom graphs for the duration of the session, or something. More on this later. In the meantime, I've put it in my release plan.
September 20, 2002
I found a tool that a lot of the same features of
DependencyFinder, but with a GUI and can also
handle C++. I read a review in
Java Developers Journal.
The tool is called
Small Worlds and it
sells for around $1,750. The screenshots are really nice.
I need to write to JDJ, maybe get an article out of it. And I need to follow up on Martin Fowler and Bob Martin too.
I put (most of) the website in CVS as a new module.
I also had an idea for a possible layout of classes, by package, for a dependency graph. Classes in a package are laid out in a circle, forming a cluster. The clusters are they laid out in a larger circle. This way, one can zoom in on a cluster to explore dependencies within a package. If you zoom out far enough, inter-package dependencies dominate and packages with lots of dependencies stand out.
September 18, 2002
Worked on documentation.
Upgraded the following development components:
Ant : 1.5Beta1 -> 1.5 Log4J : 1.2.3 -> 1.2.6 Jakarta ORO : 2.0.6 -> 2.0.7-dev-1 JUnit : 3.8 -> 3.8.1 Xerces : 2.0.1 -> 2.1.0 Xalan : 2.3.1 -> 2.4.0
It turns out that a semantics change in Jakarta ORO is breaking one of the unit tests. I will look into it later.
And I'm also playing with Tomcat 4.1.10.
September 17, 2002
Compressing by looking at consecutive lines does not
work. I changed the algorithm in ListDiffPrinter
to be a little more thorough. It can still have some
problems with inner classes, but that only result in a
little too much output; nothing is lost. I'll live with
it for now.
Also fixed ListDiff.bat which was missing
a JAR, now that ListDiffPrinter uses Jakarta
ORO.
September 16, 2002
Fixed the problem with ListDiff. I'll
double check with the person who first complained about
the problem before definitely hanging my hat on this one,
though.
September 15, 2002
Turns out ListDiff is not as easy to fix
as I first expected. I know I have to be smarter than
just doing a prefix check in ListDiffPrinter,
but how do I distinguish between a package name, a class
name, and a field name? The answer will drive how far the
prefix match has to go.
I have an idea. I will have ListDocumentedElements
mark each entry with a suffix in " [P]",
" [M]", or " [F]". Then, in
ListBasedValidator, I will trim it off. That
will take care of JarJarDiff and the XSL
transformations. Then, in ListDiffPrinter,
I can use this information to do better compression of the
lists.
I've opened a bug on the matter on the SourceForge project page.
September 13, 2002
Someone found a problem with ListDiff and
how it compresses lists. It turns out that my simple use
of prefixes when performing compression was a little too
simplistic after all. Packages mask subpackages. Classes
and fields with names that are prefix of others mask those
others. This should be easy enough to fix.
September 10, 2002
Finished simplifying the UI in the Swing application of
DependencyFinder.
September 06, 2002
Added separators and table of contents to the output of
DiffToHTML.xsl. This helps me combine reports
into one long history file, with individual diffs separated
by <hr> tags. I also added new sample outputs of
JarJarDiff.
September 05, 2002
Looked into making each implementation of
Measurement compute its own metrics,
instead of having everything crammed in
MetricsGatherer. This is a major
undertaking and will have to wait until after I have
launched the first beta test. I would have to create
over 60 custom Measurement implementations,
one for each current measurement collected by the
gatherer.
September 04, 2002
Added caching of values to MeasurementBase
subclasses. This is to speed up rendering in
OOMetricsGUI and other reports.
August 31, 2002
Finished MartinMetrics.xml for the metrics
in Robert C. Martin's
Design Principles and Design Patterns article.
August 30, 2002
Refactored AccumulatorMeasurement some more.
Yesterday's implementation was to limiting. Still has a
few kinks to work out. I'm also working on
etc/MartinMetrics.xml which has the metrics
configuration to support instability and abstractness
metrics and his A vs. I graph.
August 29, 2002
Refactored AccumulatorMeasurement so I can
aggregate extra-package dependencies and compute coupling
metrics.
August 28, 2002
Added filtering to NbSubMetricsMeasurement. I
was misled into thinking I could simply count classes that have
outbound dependencies and classes that have inbound ones, and
that would be enough to compute coupling metrics. But I was
wrong. This modification is pretty useless, I can't think of
a valid use case. But what the heck, it's in there already.
August 27, 2002
Fixed yesterday's problem with CodeDependencyCollector.
It now treats the static initializer like any other feature.
I also set the static initializer's signature to
static {}. I decided to fix it since the
com.jeantessier.metrics package was already treating
it that way.
August 26, 2002
Worked on the documentation a bit. I tried to clarify how scoping and filtering work.
I found out that CodeDependencyCollector treats
dependencies coming from a class' static analyzer as if the
dependencies emanated from the class itself. This means that
dependencies from the static initializer to features show up as
class-to-feature dependencies, something I said in the manual
did not exist. Now I must decide if I'm going to amend the
documentation or treat the static initializer like a feature.
And if the latter, how am I going to name it? I'm thinking
maybe package.Class.{} or something similar.
August 25, 2002
Removed obsolete constructors in tests, now that I've upgraded
JUnit and that junit.framework.TestCase now has a
no argument constructor.
August 23, 2002
Found some articles (one by Robert C. Martin) and a tool for the Resource section. The article by Mr. Martin gave me the idea of providing a custom metrics configuration with the metrics he describes in the article, using the same abbreviations. I might need more powerful computational measurements to handle the equations.
I've put up some sample outputs so you can see what they looks like.
Upgraded the following development components:
JUnit : 3.7 -> 3.8
August 22, 2002
Worked on simplifying the UI in the Swing application. So far, it eludes me. But I'm done with the web application version.
In the meantime, I'm producing dependency reports and API difference reports for past versions of Dependency Finder.
August 21, 2002
67, 18, 4, 1, 1, 1, ...
The flow of downloads has tarried. But that's OK. I'll get another chance when the beta comes out (if I can get to it).
Worked on simplifying the UI in the web application. Both
query.jsp and closure.jsp now have
a simple and an advanced form. The advanced form has all the
options whereas the simple form only takes regular expressions
that apply to all packages, classes, and features. I'm thinking
of relying on external cascading stylesheets, but I have to
check about browser support. I suppose this is not really an
issue anymore, but I'll check anyway.
August 14, 2002
67 downloads!!!
I posted a message at 10am PDT and by midnight EDT there had been 67 downloads!
August 12, 2002
I found two other tools that do similar things as Dependency Finder: classdep and reView.
Faced with the declining number of downloads of Dependency Finder recently, I'm going to have to start advertising. I'm going to start by spamming newsgroups... See you in comp.lang.java.* :-)
August 07, 2002
I've had an idea for a logo. Here's the initial draft.
![]()
July 29, 2002
Added date of last extraction to extract.jsp.
July 23, 2002
Trying simpler UI with web application JSPs because they are easier to manipulate than the Swing code.
July 11, 2002
New release! I was hoping to launch a beta, but I'm behind with the documentation. With this release, people can benefit from the bug fixes while I finalize the docs.
I'm still going through the change logs from CVS to publish the list of changes since the last release.
July 09, 2002
Back from vacation.
Adjusted release plan to close current release and spec out the first beta.
Wrote a Perl script to parse log information from CVS to prepare the change file listing differences since the last release. New release is imminent.
June 17, 2002
Done with SLOC.
Added indent-text switch to commands that
generate textual output, including XML documents. This
allows users to adjust file size by replacing four spaces
with a single TAB or whatever else they want.
June 14, 2002
Finished initial SLOC testing. I need to check a few more things dealing with synthetic elements and inner classes.
June 13, 2002
Fixed the ListDocumentedElements doclet so it
skips static initializers.
Added dtd-prefix switch to commands that
generate XML documents. This allows users to point to local
DTDs when they are disconnected from the Internet. The
user can simply use
"-dtd-prefix %DEPENDENCYFINDER_HOME%\etc". The
default value points back to the Dependency Finder website.
June 12, 2002
ListDiff can now compress the resulting list.
This means that if, for instance, a class is in a list, it
will remove entries for methods of that class from the list.
The same goes for packages and their classes. Just call it
with the compress switch.
I changed the published list to use with
PublishedDiffToHTML. It makes more sense to use
the old list, since the goal is to notify customers of the
changes that possibly break backwards compatibility.
June 11, 2002
I'm done with dependency-related metrics. Now, I need to finalize SLOC.
June 10, 2002
I'm not going to make it. I wanted to finish the first beta release before going on vacation next week, but I'm not done with the coding and there is a lot of documentation to write still. I'll do a date-tagged release with all the code fixes so I can close the bugs and do the beta later, when I've had some time to write good docs and package the whole thing properly. I've updated the release plan accordingly.
Worked on dependency-related metrics. I think I've got it nailed down, but I need to write more tests.
Made progress with SLOC. Methods are pretty good.
Fields are accounted for. I've added one for the class
declaration. I still need to work out try {
lines.
I got feedback regarding ListDiff and
PublishedDiffToHTML.xsl. I need to do more
testing to make sure that they compute differences
correctly.
June 09, 2002
Worked on dependency-related metrics.
June 08, 2002
Wrote test cases for dependency-related metrics.
I'm thinking of using it to test
CodeDependencyCollector too, some day.
June 06, 2002
Changed the default self-disposition of
StatisticalMeasurement to average values. It
turns out that in my attempt yesterday, I had changed the
wrong default value in the measurement's initialization.
You can now expand AccumulatorMeasurement
values when using the -expand switch with the
-txt switch to OOMetrics.
Fixed -verbose and -trace
switches on all executables.
Fixed a bug in SumMeasurement when dealing
with StatisticalMeasurement and empty lines.
Allow group definitions to be defined by multiple regular expressions.
Used SumMeasurement to compute SLOC on classes
as the sum of SLOC on submetrics + 1. I still need to figure
out how to ignore counts for synthetic elements and add
abstract methods and try { lines.
June 05, 2002
Created classfile.dtd and put it at:
https://depfind.sourceforge.io/dtd/
Added a TableCellRenderer to the
JTable instances in OOMetricsGUI
to draw out-of-bound measurements in red. I also tried
to set the background to create bands of three rows of
alternating colors, but it is not working perfectly yet.
Added a new metrics tool to OOMetricsGUI
to reset the list of measurements.
Measurements in the configuration file can now be made
invisible via an XML attribute on <measurement>
tags.
I tried to change the default self-disposition of
StatisticalMeasurement to average values, but it
behaved strangely by ignoring itself instead. Strange! I
also tried to have separate renderer classes for
StatisticalMeasurement and the other subclasses
of MeasurementBase, but that also didn't quite
work out. More on that later ... maybe.
June 04, 2002
Added SumMeasurement in preparation for SLOC
and dependency measurements.
Created metrics.dtd and put it at:
https://depfind.sourceforge.io/dtd/
Fixed a mistyped measurement in MetricsConfig.xml.
Fixed MeasurementBase.InRange() to handle
textual thresholds. It assumed the thresholds were instances
of Number, but the XML descriptor provides them
as text which has to be parsed.
June 03, 2002
Addressed a possible performance issue which
com.jeantessier.metrics.XMLPrinter where using
four spaces for indent was yielding huge XML reports.
I changed OOMetrics to use a tab character
instead. We'll see how it goes. At the same time, I adjusted
XMLPrinter to generate <measurement>
nodes instead of <metric>. It will also ignore
NullMeasurement instances from here on.
Use the system property line.separator
instead of "\n" in metrics reports. This should help with
cross-platform portability.
Rigged MetricsFactory to handle group
definitions properly.
I've been looking at using tool tips in the header of the
result tables in OOMetricsGUI to expand the
measurement names. Each header has an associated
JComponent, but getting to is proving rather
difficult. I'd almost have to provide a custom
implementation of TableColumnModel, but I
only need to override a tiny piece of the behavior. More
on this later.
June 01, 2002
Finished MetricsConfig.xml and the constants
com.jeantessier.metrics.Metrics. I adjusted
some of the reporting functions in printers and in concrete
implementations of Measurement.
May 31, 2002
Worked on unit tests for MetricsGatherer.
May 30, 2002
I'm working out MetricsGatherer to bring it
closer to the old, hard-coded MetricsFactory.
This is going to take a while ...
The optional validation was not enough when working in a disconnected environment. It still tried to load the DTD, even though it was not using it to validate the document. I've used an Apache feature to turn off loading of external DTDs when validation is turned off. It now works fine.
May 29, 2002
Finished with the whole MetricsConfiguration
mess. All I have left to do is adjust the measurement names
in MetricsGatherer and complete the descriptions
in MetricsConfig.xml
Next, it is time to fix SLOC and dependency metrics. Then I'll simplify the UI, write tons of docs, and the first beta will finally be available by the middle of June.
Famous last words ...
May 28, 2002
I was looking into Ant and found some interesting
features. I added descriptions to the build script to help
people understand the various targets. I also managed to
use the <ant> task to compile the JarJarDiff
test samples.
I realized that the combination of a validating parser
with remove DTDs might not work when disconnected from
the Web. So I made the validating behavior optional in
com.jeantessier.dependency.NodeLoader and in
the DependencyReporter CLI application.
I upgraded all the scripts to use the new Xerces JAR files configuration.
Upgraded the following development components:
Ant : 1.4.1 -> 1.5Beta1 Log4J : 1.2rc1 -> 1.2.3 Jakarta ORO : 2.0.5 -> 2.0.6
May 26, 2002
Redesigned the Measurement hierarchy and
got rid of NumericalMeasurement and
NumericalMeasurementBase. Now, all
measurements have a "value" and StatisticalMeasurement
uses a self dispose parameter to determine how to
evaluate itself. The class diagram is now almost trivial.
The implementations of Measurement can
be configured using the init-text tags in
the descriptor.
Class Init-Text AccumulatorMeasurement[SET | LIST]CounterMeasurement[initial value]NbSubMetricsMeasurementnone RatioMeasurementbase measurement name [DISPOSE_x]
divider measurement name [DISPOSE_x]StatisticalMeasurementmonitored measurement name [DISPOSE_x]
[self DISPOSE_x]
May 23, 2002
I have fixed all the unit tests!
I was not happy with the way that most measurements
inherited from MeasurementBase and implemented
NumericalMeasurement. This led to a lot of
duplicate code and the resulting class diagram was hard
to read. So I created NumericalMeasurementBase
to store the common code and provided some sensible default
method implementations in both abstract classes. Now, there
is no longer any duplicated code and the class diagram is
simple and obvious.
May 21, 2002
I have fixed all the unit tests except the one for
StatisticalMeasurement. I've got it pretty much
figured out, but there is just a lot of code to change to fix
these.
I stumbled by pure chance on articles by Martin Fowler on coupling and public vs. published interfaces. I am now thinking of writing follow up articles that show how Dependency Finder helps with addressing these issues.
May 20, 2002
I have a new design for Measurement
implementations. Now I get over 100 compile time errors when
compiling the unit tests. This is going to take forever...
May 17, 2002
I finally figured out my problem with Xerces and unit tests.
The Xerces and JUnit's class loading behavior do not play well
together. I had to craft an excluded.properties
file so that Xerces files are not reloaded with every test run.
I finished MetricsConfigurationHandler. In the
unit tests, I tried to test Xerces's XML validation feature.
It load the external DTD, alright, but fails to flag documents
that do not follow the DTD. So much for that.
To use the validating parser, I had to put the DTDs on:
https://depfind.sourceforge.io/dtd/
Upgraded the following development components:
Xerces : 2.0.0 -> 2.0.1
May 13, 2002
I still haven't solved my problems with Xerces.
May 10, 2002
I am having problem with unit testing Xerces.
XMLReaderFactory complains that the default
XMLReader is not a XMLReader.
May 06, 2002
More work on MetricsConfiguration.
May 03, 2002
I switched the XML formats to use an external DTD instead of an internal one, like I've been doing so far. Not that I have an "official" web site, I can store the DTDs there for all to share. When the release is ready, I'll put the DTDs at:
https://depfind.sourceforge.io/dtd/
I have got a design for the configuration of metrics system. I have started writing some unit tests.
May 01, 2002
Fixed bugs in:
com.jeantessier.classreader.DirectoryClassfileReadercom.jeantessier.classreader.JarClassfileReadercom.jeantessier.classreader.ZipClassfileReader
where they were not closing the files they were opening. This resulted in locked resources under Windows NT that prevented me from recompiling classes after finding out stuff about them.
Upgraded the following development components:
Log4J : 1.2beta3 -> 1.2rc1
April 30, 2002
I have found a silly bug in com.jeantessier.dependency.TextPrinter
where it was not following the Inherited Behavior pattern in
some of its methods. This was slowing down the printing of
dependency graphs tremendously (by a factor of 60 for analyzing
Dependency Finder itself). It is all fixed now.
April 28, 2002
I have started defining the DTD and initial document for the metrics configuration. I have yet to read it in or do anything useful with it.
April 24, 2002
I have changed how Metrics manages
Measurement instances. If the Metrics
instance is not tracking a given measurement, it returns a
NullMeasurement object instead of null.
April 22, 2002
I just started on the metrics features. After these are done, and I've completed the user's manual, I'll be done with this release!
I need to adjust the MetricsFactory to create
the elementary measurements at each level and then setup the
composite measurements from some configuration. This will set
the stage for using custom configuration files for custom
metrics reports in the next release.
April 19, 2002
I have added a utility for diff'ing published API lists.
The utility is called ListDiff and has two XSL
stylesheets for writing to HTML and regular text.
April 16, 2002
I fixed some images in the user manual.
April 15, 2002
I'm looking at having a Java Web Start version too.
April 14, 2002
I am done with JarJarDiff (for this release)!
I have fixed DifferencesFactory. I have renamed
some of the stylesheets. I have added even more unit tests.
DiffToExternalHTML-> PublishedDiffToHTMLDiffToDocumentationHTML-> ListDocumentationDiffToHTMLDiffToInheritanceChange-> ListInheritanceDiffToText
April 13, 2002
I have moved all the difference computation code from the
constructors to the various Differences classes to a
single DifferencesFactory class. I have added
additional unit tests that cover most cases.
April 11, 2002
I have figured out how to work around the expression size
limitation in DiffToExternalHTML.xsl. I have added
a full-signature attribute to declaration
nodes in the DTD for differences. This keeps the size of the
expression somewhat lower, but it is still a behemoth.
I am now done with the higher-resolution validation feature.
The XSL stylesheets for JarJarDiff seem to work
fine. I have added one more to only list documentation level
changes. I also need to test DiffToExternal on a
real-life sample. I am still not clear as to which validation
list to use: the one generated from the old code, the one generated
from the new code, or a merge of the two.
April 10, 2002
I have been looking at the DiffToExternalHTML.xsl
stylesheet, looking for a way to get the additional validation
now that the resolution has gone down to the feature level.
I have noticed that the match expression for
class nodes has exceeded some internal buffer in
Xalan. If a add a few characters, I get an
ArrayIndexOutOfBoundsException from the transformation
engine.
April 09, 2002
I am almost done with new features to JarJarDiff!
I fixed all the unit tests and the XSL stylesheets. In the
process, I fixed a bug in PackageDifferences and
ClassDifferences when adding decorators.
DiffToExternal may need additional tweaking. I
also need an new XSL stylesheet to extract the documentation
level information from all the other differences.
April 08, 2002
JarJarDiff is a mess. I have started writing
unit tests in an effort to regain control.
April 05, 2002
The code is in place, but it does not seem to be working.
April 03, 2002
First shot at tracking documentation levels using
JarJarDiff.
After looking at the format used by Argo/UML to save UML project files, I'm having renewed interest in XMI to import dependency graph into UML modeling tools. This would allow people to draw the graph visually using their favorite UML tool. Argo/UML also uses PGML to store graphics. This has led to W3C to standardize SVG, which I might be looking into in the future.
March 31, 2002
I finished the reorganization of the Differences
hierarchy for the Decorator pattern. I have made this change to
ease listing of documentation status changes. Come to think of
it, I might not have needed this change to do the new feature.
I have added some documentation for JarJarDiff
in preparation for the new feature..
March 30, 2002
I started some unit tests for the Differences
hierarchy.
March 27, 2002
I reorganized the Differences hierarchy to
make room for a Decorator pattern. I'm reimplementing tracking
of deprecated features to arrange the code. After that, I'll
be better able to take care of documented vs. undocumented
programming elements.
Right now, I've broken something. I don't have the adequate unit tests to tell me what it is that I broke. I guess I've been a bad boy. This will take a little while to fix.
March 21, 2002
I am rediscovering the com.jeantessier.diff
package in an attempt to incorporate a documented
attribute to programming entities. I have added javadocs
to explain some of the classes and interfaces.
March 19, 2002
That validation list is still giving me headaches. How can I make that feature fit without breaking the purity of my code so far? :-)
In the meantime, I've added a confirmation screen to
extract.jsp, hoping this will prevent lengthy
extractions from happening by accident.
March 13, 2002
I have regained control over DiffToExternalHTML.
With finer control over validation, how the validation list
is generated and used becomes more and more important. If we use
javadoc comments, and we want to track when things transition
from valid to invalid or vice versa, we now need a list for the
old version and a list for the new version. How these two lists
are combined and used remains to be determined. Should they be
fed to JarJarDiff and merged into the XML output?
Should they be fed to the XSL stylesheet, making it even more
convoluted? And what about DiffToHTML.xsl? Should
it start to use Java code too?
I streamlined Diff.dtd to remove duplicated
information in the output of JarJarDiff.
March 10, 2002
I wrote ListBasedValidator and I have
ListVisibleElements, a doclet for listing programming
elements that have been flagged through their javadoc comments.
This way, one can use javadoc tags to flag classes and features
as part of the published API and guide DiffToExternalHTML
to limit the report to those classes and features.
I've started to adjust DiffToExternalHTML, but
that XSL non-trivial.
March 07, 2002
I refactored PackageValidator to create the
Validator interface. This is in preparation to a
more granular validation that would have a feature-level
resolution.
March 04, 2002
I've simplified how TransitiveClosure determines
whether or not to follow inbound and outbound dependencies. But
I still have problems with weird interactions when following both
inbound and outbound dependencies at the same time.
I've created closure.jsp, a web application
interface to TransitiveClosure.
I've added the appropriate switches to
DependencyClosure.
I fixed a typo in DiffToExternalHTML.xsl.
March 03, 2002
I've bounded TransitiveClosure.
February 27, 2002
I finally have a release plan.
I may have found some more/better icons in another open source software. More on this later.
February 26, 2002
I got rid of the previous DiffToHTML.xsl and
renamed DiffToInternalHTML.xsl to it. I also added
the product's name to the template and redesigned the title line.
I added it to DiffToExternalHTML.xsl too. I'm
thinking of making that one simply an XML filter and use the new
DiffToHTML.xsl for all rendering. But I will need
to figure out how to efficiently copy XML trees in XSLT.
Upgraded the following development components:
Log4J : 1.2alpha6 -> 1.2beta3 Jakarta ORO : 2.0.4 -> 2.0.5 Xerces : 1.4.3 -> 2.0.0 Xalan : 2.2 D11 -> 2.3.1
February 21, 2002
I rewrote the Documentation page to the new Resources center. I hope to keep track of articles and competing software there.
I'm going to upgrade Xerces, Xalan, Jakarta ORO.
February 19, 2002
Fixed bugs with com.jeantessier.classreader.XMLPrinter.
The XML now uses lower-case tag names. I'm still missing a DTD.
I upgraded extract.jsp and query.jsp,
so they are a little more friendly now.
I moved log4j.properties under src/.
February 13, 2002
I modified the com.jeantessier.classreader package
so that ClassfileLoader can notify listeners as soon
as a .class file is loaded. This way, tools like
DependencyExtractor can use a
TransientClassfileLoader since it does not need the
Classfile instance once the dependencies have been
extracted.
February 05, 2002
I need a release plan. I've had a number of ideas lately for new features and I need to scope what's doable and what's not, and have some idea of when I can expect the release.
I fixed TransitiveClosure. I also added to it a
feature where it can now follow inbound dependencies in addition
to outbound ones. Maybe this will become handy somehow. I'm
thinking of limiting the depth of the closure exploration, though.
And finally, it now has two modes of operation: one where it only
records the first dependency that led to a Node, and
another where it records all such paths.
I adjusted the code so that Log4J is initialized from
log4.properties located on the CLASSPATH.
I thought about putting the file in DependencyFinder.jar,
but decided against. If someone is familiar with Log4J, they can
edit the configuration file and adjust logging to their liking.
It took a lot of hard work to figure it out. I had to follow all
the steps below, pretty much in that order:
- RTFM
- RTFM
- RTFM :-)
I temporarily removed xerces.jar and xalan.jar
from the web application WAR file. This dramatically reduced its size.
I also added deploy and undeploy targets to
the build.xml file for Tomcat.
February 03, 2002
I adjusted GraphCopier and GraphSummarizer
to reduce the noise in their scope output. They used to output the
whole package of any node that was in scope. This often produced extra
output that would obscure the answer to the query.
The new GraphCopier maintains a separate NodeFactory
for scoped nodes and filtered nodes. Only nodes in the scope are
created using the scoping NodeFactory. This cuts away
a lot of extraneous information.
This has unfortunately broken TransitiveClosure.
February 02, 2002
I fixed JarJarDiff. I forgot to adjust it when
I changed ClassfileLoader to add support for
"progress report"-type of information. JarJarDiff
did not call Start() on its ClassfileLoader
instances.
January 29, 2002
Dependency Finder is one year old!
January 28, 2002
I put the functionality for exploring dependency graphs into a web application. It is governed by three application context parameters:
-
name - A user-friendly name for the codebase. This allows users to know the subject of the dependency graph without revealing where it is on the server's file system.
-
source - The compiled Java code to be extracted. You can specify multiple locations by separating them with commas.
-
mode - Whether to maximize or minimize the graph, or leave it in raw form.
The application consists of only two JSPs:
-
extract.jsp -
Extracts the dependency graph from the source specified
by
application.getInitParameter("source"). The graph will further be processed based onapplication.getInitParameter("mode"). -
query.jsp - Displays a subset of the dependency graph, according to the user-specified scope and filter.
I may look into better rendering and status out of the JSPs.
January 25, 2002
I finally found a practical way to parse the input from the GUI to allow users to specify multiple regular expressions.
I have a plan for making a web application version. The
application implicit object can hold on to the
dependency factory and a query JSP can run queries and format
the results. This is going to be cool!
January 23, 2002
I'm working on the manual. I started to use MS Word for some of the figures. I'll use Poseidon for the UML.
January 22, 2002
I fixed the minimize and maximize discussion. It had broken links and I had to regenerate the HTML from the source MS Word document.
While I was at it, I fixed the Documentation section too. It had a few obsolete links.
Someone brought JDiff to my attention. I've given it a cursory look and I still believe that my work is so much better. ;-) More on this later. I'll have to create a section on the competition.
January 21, 2002
It turns out the problem with XSL was my fault. Apparently, I was not supposed to use the string "--" in comments the way I did to format the copyright notice. I'll put the fix in the next release. In the mean time, people can either edit the files themselves or stick to the GUI.
I'm working on fixing -verbose and -trace
switches.
Upgraded the following development components:
Log4J : 1.1.3 -> 1.2alpha6
I thought about upgrading Jakarta ORO, who just came out with version 2.0.5. But the changes are just bug fixes that don't impact me, so I decided against.
I'll also try to fix the dependency metrics for the next release.
January 18, 2002
I'm making progress with the user manual. I've expanded the TWiki-like notation to include HTML and inlined images. I put the working draft on the project's web site. It'll be part of the distribution for the next release.
I got my first support call today. Someone is having difficulties
with one of the XSL converters. This is all Xalan
stuff, so I'm thinking it might be JVM memory. I instructed
them to set DEPENDENCYFINDER_OPTS and call me
back.
January 17, 2002
I got started on a user manual. I want to enter the core text quickly, so I wrote a Perl script to replicate the TWiki shorthand. I'll use it to generate the initial version of the text and we'll see later if it's worth while to keep the original shorthand.
January 15, 2002
Added feature 502554 "Sorting doesn't work on NaN".
I changed com.jeantessier.metrics.MetricsComparator
so that NaN always appears at the bottom of the
list.
January 11, 2002
I am going to switch to SourceForge's project management tools for keeping track of status and downloads. It provides more information and is easier to maintain than my little manual HTML page. I'm going to merge it with this journal and then merge it.
January 10, 2002
I moved the code to the BSD-style license.
Emacs behaves strangely when under CVS. I'll need to adjust the code formatting. It is back to indenting with tabs and spaces.
January 09, 2002
I finally managed to create the CVS repository on SourceForge. I've uploaded a first version of the code, but it still has the LGPL license instead of the BSD-style one.
I also uploaded the release file in SourceForge's FRS. One more thing to learn (and is not trivial).
I looked at BCEL.
It looks too complex for me to bother with right now.
I already have something that works. I'm going to stick with
it for now. I like how my code uses the Visitor
pattern to provide hooks for traversing the structure.
January 07, 2002
The Jakarta Project
at Apache has
BCEL,
a subproject that does the same thing as
com.jeantessier.classreader and more.
January 03, 2002
I requested a SourceForge project and had it approved the same day. I got SSH to work, but CVS still eludes me.
I'm going to change the licensing. I'm going to move away from LGPL to a BSD-style license.
December 20, 2001
I've been considering switching from Log4J to the JDK 1.4 Logging API. I decided against it after reading Ceki Gülcü's comparison of the two. I've played a little bit with the Logging API and it was very difficult to introduce a new format for the logged messages. I believe Log4J is more flexible and easier to use.
This being said, I still need to work out the
-verbose and -trace switches so
that they properly adjust the logging configuration.
I also need to compare the speed of the tools when
they use Log4J as opposed to com.jeantessier.log.
I got rid of the JAVA_BIN and
JAVA_EXE environment variables. I should be
able to use only JAVA_HOME like everybody else.
December 15, 2001
I switched from com.jeantessier.log to
Log4J. I must now figure out how to send the
information to a log file instead of the console.
December 13, 2001
I merged back together JT and JarJarDiff
into DependencyFinder.
I renamed com.jeantessier.util.commandline to
com.jeantessier.commandline and
com.jeantessier.util.log to
com.jeantessier.log. The next step is to replace
com.jeantessier.log with Log4J from the Jakarta
project.
December 03, 2001
I added a filtering function to OOMetricsGUI.
With this feature, I can filter a set of metrics to only show
the rows that interest me, out of a large body of code.
There is a bug with the sorting function. If a column contains NaN values, only the segments between NaN values get sorted. The NaN values don't move and I then have islands of data, each one sorted by itself.
November 27, 2001
I change the root of the packages from jt to
com.jeantessier. This comes as part of the preparations
to make this software open source.
Upgraded the following development components:
Jean Tessier API : 20011114 -> 20011125
November 21, 2001
I added the ability to sort the columns in tables from OOMetrics.
I also fixed a minor bug in jt.dependency.GraphSummarizer
where it was not using the right level for scope and filters (class when
it should have been package).
November 13, 2001
I've put everything under the LGPL.
Upgraded the following development components:
Jean Tessier API : unknown -> 20011114
November 07, 2001
I got some performance numbers. I don't recall which column is which implementation, but it seems to point to a decrease in performance. :-(
| Corpus | Before (secs) | After (secs) |
|---|---|---|
| JDK 1.3.1_01 | 148.363 | 154.507 |
| EFS 4.0 b29 | 206.717 | 210.042 |
I'll have to redo these tests to make sure.
November 06, 2001
I removed trace statements from
jt.dependency.VisitorBase to boost performance.
In tests with JT.jar and DependencyFinder.jar,
I couldn't detect any difference. Can you see the difference?
I also got the latest JT library.
I revamped the web page.
November 04, 2001
OOMetricsGUI is a Swing GUI put on top of
OOMetrics. It resulted in the creation of the
jt.swing package to hold generic classes for
Swing applications.
The next step is to be able to sort on arbitrary columns.
I must also integrate it with DependencyFinder.
October 30, 2001
I fixed a problem with inner classes. OOMetrics was
counting all inner class entries in the InnerClasses class attribute.
This included references to inner classes in other classes, resulting
in a count that was higher than reality. It now restricts itself to
actual inner classes of the current class, resulting in the correct
count.
I also adjusted how the jt.classreader.Classfile
constructor writes trace entries about its constant pool. This way,
the text of the pool gets generated only if there is a log object to
print it. I'm expecting a 25% improvement in performance as this
involves quite a bit of conversions when printing the entries in the
constant pool.
I also fixed a bug in OOMetrics so that it now uses the
-project-name command line switch instead of
-project to determine the project's name in reports.
October 28, 2001
For a while now, I have been less than pleased at having to
operate on maximized graphs. I revised jt.dependency.GraphCopier
to make jt.dependency.GraphSummarizer. The latter
explores the graph more fully to compensate for the sparseness of the
graph. This modification will shorten the time it takes to read the graph,
but queries will take longer to process. Usage in the field will tell which
mode works best on real projects, whether it is normal, minimized,
or maximized. I had to retrofit DependencyReporter,
DependencyMetrics, and DependencyFinder and give
them the appropriate switches.
October 24, 2001
I found a bug in jt.dependency.CodeDependencyCollector
where it does not process catch clauses to include
dependencies on caught exceptions.
In order to fix this bug, I revisited
jt.classreader.VisitorBase to build in default
behavior that explores all parts of the classfile structure.
I also modified DependencyFinder to include
command-line switches -trace and -verbose.
October 19, 2001
I added switches to OOMetrics to make the parts
of the report conditional. This way, the users can request only
specific parts of the report if they want.
I need modified jt.metrics.ui.OOMetrics so that
it parses all classes before starting the analysis.
October 18, 2001
I fixed a bug in jt.metrics.MetricsGatherer
that caused a NullPointerException when analyzing
java.lang.Object. It also skewed Depth of Inheritance
metrics.
I also fixed a bug when processing static class initializers. They were getting attached to a no name class in the default package. Parsing the name correctly fixed the problem.
I might have to have two sets of parsed classes, one for analysis and the other for support classes. This is in order to correctly compute the Depth of Inheritance metric.
I need to modify jt.metrics.ui.OOMetrics so that
it parses all classes before starting the analysis. Right now,
it parses and analyzes each parameter on the command-line
separately.
October 17, 2001
I adjusted the display of ratio metrics in
jt.metrics.PrettyPrinter and reorganized the code
in the subclasses of jt.metrics.Printer, making it
implement jt.metrics.MeasurementVisitor. I used
the occasion to normalize the behavior of the -time
switch to OOMetrics.
October 16, 2001
I added ratio metrics in jt.metrics.MetricsFactory.
I now use instances of java.text.NumberFormat in
jt.metrics.PrettyPrinter to adjust the display of
numbers.
I played with using Jikes to compile the code
instead of javac, but the difference in compile
time was not worth the extra warnings (4 secs vs. 10 secs).
I now use the default compiler mode in javac,
modern, instead of classic. I hope
this won't break the compatibility with JDK 1.2 VMs.
October 15, 2001
It's been a while, but I've been preparing an OO metrics module.
Right now, it is only available as a command-line utility named
OOMetrics. It is very unstable and not all metrics
are computed yet. Output is either text, .csv file,
or XML. I will eventually have XSL stylesheets to format the XML
output. I will also eventually incorporate it in
DependencyFinder.
I added PC counter information to the trace information from
jt.classreader.Code_attribute.
Upgraded the following development components:
JDK : 1.3 -> 1.3.1_01 Ant : 1.3 -> 1.4.1 Jakarta ORO : 2.0.1 -> 2.0.4 Xerces : 1.4.1 -> 1.4.3 Xalan : 2.2_D3 -> 2.2_D11
August 30, 2001
I fixed a bug in jt.dependency.CodeDependencyCollector.
It was not looking at the signature of called methods when looking
for dependencies. I also stopped processing instruction 0xBB (new),
since the call to the constructor always follows shortly after.
I fixed a bug in jt.dependency.PrettyPrinter. It was
not collecting dependencies correctly when they were between
different kinds of nodes (e.g., feature to class).
There was a bug with jt.dependency.LinkMinimizer.
It misses some redundancies. The whole class had to be redone.
I now have a strong test suite for it and for
jt.dependency.LinkMaximizer too.
August 28, 2001
I added controls for the printer of dependency reports in
DependencyFinder. This way, we can now limit the
results to inbound or outbound dependencies only, and remove
empty nodes from the result.
August 24, 2001
I adjusted the text output for a nicer printout. I reorganized
the jt.dependency.Printer hierarchy to preserve the old
format and maximize code reuse.
August 21, 2001
I fixed a scoping problem in jt.dependency.GraphCopier.
It did not follow inbound dependencies and was therefore missing many
dependencies. I suspect that the same goes for
jt.dependency.TransitiveClosure, but I have not had the
time to investigate.
August 17, 2001
I fixed a scoping problem in the jt.dependency.Visitor
hierarchy. I also added some new unit tests in the process.
August 16, 2001
I made major changes in the jt.dependency.Visitor
and jt.dependency.TraversalStrategy hierarchies. I
have consolidated the visitors under a single base class and
moved the complex traversal logic into a traversal strategy
implementation.
There is a bug with the new traversal strategy which does not
traverse the graph at all unless
jt.dependency.TraversalStrategy.PackageScope()
is true. Likewise, feature nodes don't get visited unless
jt.dependency.TraversalStrategy.ClassScope()
is also true.
August 12, 2001
Made jt.dependency.MetricsGatherer inherit from
SubGraphSelector instead of VisitorBase
so that I could apply scoping to metrics queries. I had to
retrofit DependencyFinder and DependencyMetrics
to pass in the scoping parameters.
I wrote GraphCopier. I can now easily make copies
of graphs before maximizing them.
I have unit tests, using JUnit, for GraphCopier.
August 03, 2001
The status line of DependencyFinder (previously
known as SwingDependencyReporter) was using up too
much CPU time, so I trimmed down the number of messages that get
displayed. I also had OpenFileAction display class
names on the status line as they are being loaded.
May 29, 2001
I fixed bugs in SwingDependencyReporter.
- The class
XMLFileFilterno longer ignores directories. - I now use the Metal look and feel.
- I made the result area non-editable. You can still cut and paste from it (at least on Windows).
May 27, 2001
I added SwingDependencyReporter, a Swing-based
GUI for DependencyReporter. It is still a
little buggy, but it works.
I also reorganized the jt.dependency
package to isolate the UI-related stuff in subpackages.
The package hierarchy may still need some tweaking.
May 22, 2001
I revised all the .bat files to support an
arbitrary number of arguments. On Windows machines, this
can require messing with the CONFIG.SYS file
to increment the amount of memory dedicated to environment
variables.
May 17, 2001
I added a -f2f switch and matching .bat
files for DependencyReporter to analyze
software at the feature level.
I am rewriting the .bat files to support an
arbitrary number of arguments.
I also added a -time switch to all commands
so we can time their execution.
April 26, 2001
I upgraded the package jt.classreader so I could
get signatures from all methods references. I also upgraded the
package jt.dependency to track methods by signature,
instead of only by name.
April 16, 2001
Upgraded Ant (1.0.8 -> 1.3) and Jakarta ORO (1.2 -> 1.2.1).
I need to get JUnit involved!
I thought of adding support in the jt.classreader
package for generating the .class file. This way,
I can easily test the whole package by parsing and then rewriting
a .class file. If the bytes are the same, then no
information was lost during parsing.
April 09, 2001
Spun off JarJarDiff.
Reorganized the package structure.
April 05, 2001
When attempting to locate a feature, the code now looks at
implemented interfaces too. ClassDifferences will
use this for all fields and only for methods between classes or
between interfaces.
- A field removed from an interface or from a class will only be showed as removed if it cannot be obtained from a superclass or supported interface.
- A method removed from an interface will only be showed as removed if it cannot be obtained from a supported interface (superinterface).
- A constructor or method removed from a class will only be showed as removed if it cannot be obtained from a superclass. It will not consider a matching method that would be obtained from an interfaces, since this interface would not provide an implementation for that method.
I renamed the packages. I'm still not happy with all the names,
specially the jt.tools package.
April 04, 2001
I adjusted JarJarDiff so that when it detects a
feature that has been removed, it looks in the superclasses of
the class for a matching signature or proper visibility. This
can happen when refactoring pushes a method up the inheritance
tree. The method is no longer in the class, but it can still
be visible if it was declared public or
protected. The XML node gets a new attribute to
indicate that a removed feature is now inherited. The XSL
stylesheet can then choose to ignore the removed feature, if it
wants to.
I've added a tool called DiffToInheritanceChange
that lists interfaces and classes whose extends
or implements clause have changed.
I need to redo the packaging and add documentation.
April 02, 2001
I fixed a bug in the package jt.dependencyfinder.classreader
to process unknown or custom attributes in the .class
file, such as those generated by the Microsoft compiler.
I also fixed bugs in DiffToExternalHTML.xsl dealing
with restricting the processing to public or protected features,
as well as correctly detecting changes in visibility from protected
to package or private.
March 28, 2001
I gave a copy to Mickey Reilly so she can start using
JarJarDiff. I had to add quick installation instructions
in readme.txt.
March 20, 2001
JarJarDiff is done, along with its stylesheets. If I
have the time, I'll build test cases so we can verify that it really
does trap everything it's supposed to.
The script JarJarDiff.bat takes two codebases (JAR files,
Zip files, or directories) and saves the differences in an XML document.
The script DiffToInternalHTML.bat takes the XML document
generated by JarJarDiff and transforms it completely to HTML.
The script DiffToExternalHTML.bat takes the XML document
generated by JarJarDiff and transforms the public subset of
it to HTML.
I may need to split this website according to the various tools:
DependencyExtractorDependencyReporterDependencyClosureDependencyMetricsClassMetricsJarJarDiff- utilities
I may also need to revise the package names and organization.
March 19, 2001
Pretty much done.
In DiffToExternalHTML.xsl, I now use an XSLT Extension
in Xalan-Java to limit the report to a subset of packages defined in a
separate file. The XSL stylesheet has a default value for the filename,
and I should be able to pass in a value from the command-line. I can
now trap changes in extends, implements, and
throws clauses, as well as in the return type of methods.
March 16, 2001
In DiffToExternalHTML.xsl, I can use an XSLT Extension
in Xalan-Java to limit the report to a subset of packages defined in a
separate file.
In DiffToExternalHTML.xsl, I need to filter out
declarations that only remove abstract, final,
and static, instead of filtering in declarations that
add it. This way, I might be able to trap changes in extends,
implements, and throws, as well as return type.
March 15, 2001
Refactored JarJarDiff and the XSL stylesheets
to generate both reports from the same XML file. JarJarDiff
still supports the -external switch, but not for
long. I am also more strict regarding what goes in the external
(i.e., public) report. Now, all I need to do is be still more
strict on what features are reported, and restrict the report to
a subset of packages.
It turns out we want feature signatures after all.
March 14, 2001
Refactored JarJarDiff and the
jt.dependencyfinder.diff package. I adjusted the
XSL stylesheet accordingly. Now, all I need to do is be more
strict on what features are reported, and restrict the report
to a subset of packages.
Also, do we want feature signatures or full declarations in lists?
March 12, 2001
Renamed the JarDiff tool to JarJarDiff,
at a friend's recommendation. I adjusted the output so that it
lists methods by signature instead of name. It actually outputs
XML and has a XSL stylesheet for converting to HTML. I don't have
one for text, yet.
I've added a tool to compute the transitive closure of elements.
It is named DependencyClosure. If creates a sub-graph
of the dependency graph by following outbound dependencies. By
starting on one class, you can find out all the classes that are
used directly or indirectly by that class. It uses the same scoping
and filtering engine as DependencyReporter.
I've added another tool to compute dependency statistics, such
as the number of inbound vs. outbound links. It is named
DependencyMetrics. I also renamed Metrics
to ClassMetrics in the process.
March 08, 2001
Added the JarDiff tool to compare different
versions of the same codebase, using the
jt.dependencyfinder.classreader
package. This first version is pretty stupid and writes
only text output from main(). It needs to
be refactored to produce XML, and then use XSL stylesheets
to generate text and HTML reports.
I've added many utility methods in the
jt.dependencyfinder.classreader
package to help in interrogating classes.
March 07, 2001
More bug fixes with parsing .class files.
March 06, 2001
Fixed the .bat files. Also created the readme.txt file that explains how to
install the tool. The .bat files still depend on the JAVA_EXE environment
variable. I need to fix that so that the .bat files try JAVA_HOME and/or
give a nice error message when they cannot find the JVM.
Added Metrics to handle class metrics gathering, as described on
2001-03-05. I have yet to gather metrics about dependencies.
Fixed some bugs with parsing .class files.
March 05, 2001
I tweaked CodeDependencyCollector to process
new, anewarray, checkcast,
instanceof, and multianewarray opcodes.
It doesn't seem to add any dependencies that were not already
found by just looking at field access and method call instructions,
but maybe this is just a quirk of my code.
I need to adjust the .bat files so that they
are no longer tied to my environment. I'll create a
DEPENDENCYFINDER_HOME environment variable,
this way people only need to set that variable to start
using the tools. Eventually, I could look at some kind of
InstallShield or InstallAnywhere solution.
I also want to create some additional implementations of the
jt.dependencyfinder.classreader.Visitor
interface to compute software metrics, such as:
- number of packages, classes, methods
- number of classes per package or methods per class
- number of public, static, or synthetic classes or features (i.e., fields and methods)
- ...
I could do the same with additional implementations of the
jt.dependencyfinder.model.Visitor
interface to compute software metrics, such as:
- number of outbound dependencies per package, class, or feature
- number of inbound dependencies per package, class, or feature
- ...
For these last dependency metrics, the tools should be applicable to
the output of both DependencyExtractor and
DependencyReporter, so that scoping can be used without
duplicating the functionality in DependencyReporter.
March 02, 2001
After running the tools on themselves, I reorganized the package hierarchy and simplified it greatly.
I added XSL stylesheets for converting dependency graphs to text and HTML. Each stylesheet has three version:
- Whole graph
- List only outbound dependencies (show nodes that are dependent on others)
- List only inbound dependencies (show dependable nodes, i.e., depended upon)
I added shorthand options to DependencyReporter.
I also added shorthand .bat files.
I adjusted DependencyExtractor to scan the
bytecode using CodeDependencyCollector instead
of limiting itself to traversing the constant pool and looking
at signatures.
I refactored Collector, making it an interface
with a base implementation (CollectorBase) and
creating an inheritance ladder with Visitor.
I found yet another bug with byte as a signed type.
There may be others still waiting to manifest themselves.
March 01, 2001
Added a script for doing XSL Transformations. It uses Apache's Xalan. Now all I need are some XSL stylesheets.
DependencyReporter is working fine, except
that the command-line is starting to exceed DOS limits.
I will need to create an XML configuration document if
I want to process complex queries.
I fixed DependencyExtractor so that it can
read from JAR and Zip files.
I found yet another bug caused by things use index 0 in the constant pool to represent special cases. There may be others still waiting to manifest themselves.
February 28, 2001
Simplified the command-line interfaces to the major
tools (DependencyExtractor and
DependencyReporter).
Fixed Reporter to assume it is operating
on a maximized graph. This simplifies the processing and
minimizes traversals. This might have also solved the
printing problems I was experiencing.
Fixed a bug where a feature could get a dependency on its class or package, and vice versa. The same thing was happening between classes and packages.
February 27, 2001
Added the CodeIterator class in the
jt.dependencyfinder.classreader
package. This allows me to traverse bytecode and capture
dependencies originating from methods. I have yet to figure
out exactly how to use it. I'm thinking of writing a
new DependencyCollector to do all the
collecting, instead of the current two step class then
feature collection.
Added the Reporter class in the
jt.dependencyfinder.model.Visitor
hierarchy. This allows me to build a Node
graph from the dependency graph which answers queries
such as package-to-package dependencies and the like.
I've adjusted DependencyReporter to make
use of this new class. There are still problems with
displaying scopes of other things than packages, but it
should be easy to solve.
The interfaces to DependencyExtractor and
DependencyReporter need work to make them
easier to use.
I must fix the deserialization bug in the
jt.dependencyfinder.classreader.Classfile
package.
I must also make the whole
jt.dependencyfinder.classreader.Classfile
easier to use for general purposes (i.e., Jeff).
February 21, 2001
Added the ClassfileLoader hierarchy in the
jt.dependencyfinder.classreader
package. This allows me to read from .class
files from a directory tree, from a JAR file, or from a
Zip files.
Right now, the loaders load and parse everything in the constructors. I need to enhance these classes to do lazy loading and provide a list of the entries they contain. Whether these entries will be file names or class names is not decided yet.
I also need to enhance the classes in the
jt.dependencyfinder.classreader
package to provide better navigation and query mechanisms
in the Classfile-rooted structure. I need to
be able to pull methods and fields by name rather than
iterate through the collections. I need to simple query
methods when looking for tagging attributes such as
Synthetic_attribute or
Deprecated_attribute.
February 20, 2001
Added a SAX parser for reading the dependency XML format, using Xerces from Apache.
Added an embryonic DependencyReporter tool.
I'm thinking of having this tools output some form of XML
and then use XSLT to convert it to whatever I need. I
would most likely use Apache's Xalan for that.
I'm also thinking of another tool that would create
a file hierarchy that mirrors the one from javadoc.
This way, I could embed dependency information in the
automatically generated documentation. Each class comments
could include a hyperlink to a local file with the dependencies
for that class. The same would go for packages.
I also need to figure a way to read .class
from JAR files, in addition to directories.
February 16, 2001
Renamed the extraction tool from
DependencyFinder to
DependencyExtractor.
Added LinkMinimizer and
LinkMaximizer visitors to control the
size of the dependency graph. LinkMinimizer
removes redundant edges while LinkMaximizer
replicates edges. The minimal graphs gives a more compact
representation, but traversal can be slowed down. The
full graph takes up more space, but its traversal will
be more efficient when computing metrics such as
aggregated package dependencies.
February 14, 2001
Refactored the
jt.dependencyfinder.model
package to have a Node hierarchy and
Visitor classes. This way, I will be
able to use visitors to implement reporting functions
in Java.
February 13, 2001
Added DirectoryExplorer and the
jt.dependencyfinder.model
package. The new DependencyFinder
tool either prints the forest of packages
or the burgeoning XML output.
We may have a problem with inlined code. Features
marked as public static final do not
show up.
February 12, 2001
Regarding the need for compiling in debug mode
(-g switch). This is required in order to
capture dependencies created by the type of local variables
in methods. The compiler verifies the legality of type
assignments and then discards the type information. When
the compiler is called with -g, it keeps the
type information to create the LocalVariableTable
attribute of Code attributes. If the
assignment is legal, then it meets all the dependency
requirements. It either uses the same dependency, or creates
a new one which is more restrictive than the initial
dependency (i.e., it transitively includes the former).
Dependencies are not automatically considered transitive,
but in this case they are. It is therefore acceptable
to ignore the dropped dependency. If someone really
wants to see it, he or she simply has to compile the
code using -g and run the dependency
finder again.
February 08, 2001
I should consider turning this into an Ant task.
What if I used a ClassLoader instead to
trap class requests as the target class is being
resolved? The good thing about looking at the
.class file only is that I don't need to
have all the dependencies on the CLASSPATH
at the time.
I looked at the classes used by javac
and it appears to be a mess. I'll stick with my things
for now.
February 05, 2001
I reinstated the Visitor pattern in the
jt.dependencygenerator.classreader
package with a vengeance. It turned out to
be useful in other areas of the .class
file as well. Visitors can now explore the
whole .class file, including fields,
methods, and attributes.
I moved the ClassReader tool from the
jt.dependencygenerator.classreader
package to the jt.dependencygenerator.tools
package.
The extractor now reads the entire .class
file.
It has problems reading from compressed JAR files.
It seems to be OK with uncompressed ones. Maybe I can
use the java.util.jar package to read the
whole byte stream in memory before starting the processing.
Handed a copy of the code to Jeff Chan.
February 01, 2001
I broke out the package and got rid of the Visitor
pattern in the
jt.dependencygenerator.classreader
package because I had only one simple visitable
object.
The extractor only reads from the constant pool,
which only holds references to methods that are
called and fields that are accessed. Each field
and method entry later in the .class
file maintains its own index to the name and
descriptor (i.e., signature) in the constant pool.
I must parse deeper in the .class
file to extract field and method entries and
get the references I need from there.
I must also make sure that I capture dependencies from local variables in methods!
François is looking for a JAR
comparison tool to analyze differences between two
versions of a given JAR file. Once I've tuned the
.class file parser, we could use it to
extract API information from JAR files.
January 30, 2001
The extractor is half-way done. The current version
is not very good at keeping track of which signatures
are really useful, and I'm not very happy with the
large switch() statements.
January 29, 2001
Project start.